⏱ 22 min read
Multi-Cloud Architecture Strategy for Enterprise Systems | Best Practices & Frameworks
Explore a multi-cloud architecture strategy for enterprise systems, including design principles, governance, security, interoperability, cost optimization, and operational best practices.
multi-cloud architecture, enterprise systems, cloud strategy, hybrid cloud, cloud governance, cloud security, interoperability, workload portability, cost optimization, enterprise architecture, cloud operating model, resilience, vendor lock-in, cloud migration, infrastructure strategy Sparx EA performance optimization
Introduction
Multi-cloud architecture is no longer an experimental pattern. In large enterprises, it is now a deliberate strategic choice. The real question is not whether the business will use cloud services, but how multiple providers can be used in a way that improves resilience, supports compliance, preserves agility, and avoids unnecessary long-term dependency. In practice, those choices are shaped as much by business conditions as by technical preference: mergers and acquisitions, regional regulatory obligations, inherited vendor contracts, modernization programs, and the need to serve users globally under a common operating model.
It is tempting to define multi-cloud as simply running workloads on more than one provider. That definition is too shallow to be useful. In many organizations, it leads to fragmented platforms, duplicated tooling, inconsistent controls, and a rising operational burden. A sound multi-cloud architecture starts from a different premise: intentional workload placement. Business capabilities should be assigned to the cloud environments that best fit their requirements. One provider may be the right home for analytics, another for regulated regional processing, and another for advanced AI or integration services. The objective is not balanced distribution. It is architectural fit.
That fit is rarely straightforward. Systems built deeply around provider-native services often deliver faster results, but they also increase switching costs and reduce portability. Systems designed only for portability often drift toward lowest-common-denominator choices and give up too much of what cloud platforms offer. Enterprise architects need a more selective discipline: standardize where consistency matters most—identity, observability, security controls, networking principles, deployment guardrails—and allow specialization where it creates measurable business value. Sparx EA best practices
This becomes especially important in large portfolios that combine legacy platforms, cloud-native services, data estates, and customer-facing digital products. These systems do not share the same latency profile, recovery target, regulatory exposure, or operating model. Without a portfolio-level view, multi-cloud becomes a series of isolated deployment decisions rather than a coherent architecture.
The central argument of this article is simple: multi-cloud succeeds when enterprises distinguish clearly between what must remain consistent and what can be specialized. That principle shapes how multi-cloud should be defined, why organizations adopt it, how it should be governed, and how it should be designed for interoperability, security, resilience, and cost control. The goal is not to erase provider differences. It is to organize those differences so that multiple clouds behave as part of one enterprise architecture rather than as separate technical estates.
1. Defining Multi-Cloud Architecture in the Enterprise Context
In an enterprise setting, multi-cloud architecture is the coordinated design of business systems, platforms, and control mechanisms across two or more cloud environments, with each environment serving an intentional role in the broader technology landscape. That distinction matters. Many organizations already have a multi-cloud estate without having a multi-cloud architecture. They use several providers through SaaS platforms, acquired business units, regional subsidiaries, or isolated project decisions, yet still lack a coherent model for governance, integration, and accountability.
The difference can be framed as accidental diversity versus governed distribution. Accidental diversity appears when teams choose providers independently, usually under local delivery pressure or based on existing skill sets. Governed distribution is something else. It is guided by enterprise principles that explain why workloads are placed in different clouds, how those clouds connect, and which capabilities must remain consistent across them.
A practical way to define enterprise multi-cloud is to look at architectural layers:
- Business layer: cloud use aligned to markets, regions, regulatory zones, or business capabilities.
- Application layer: services placed according to integration needs, elasticity, latency, and proximity to users or data.
- Platform layer: common capabilities such as identity, secrets management, policy enforcement, observability, and CI/CD.
- Infrastructure layer: networking, segmentation, encryption, and resilience patterns that allow the environment to operate as one governed estate.
This layered view highlights an important point: multi-cloud is not the same thing as universal portability. Portability may be desirable in some cases, but it is only one design objective among several. In many enterprise systems, interoperability matters more. A payments platform may remain optimized for one cloud while analytics runs in another; the architecture is effective if identity, event exchange, monitoring, and recovery processes work reliably across both.
To make this definition operational, architects need explicit decisions in three areas:
- Workload classification
Systems should be categorized by business criticality, regulatory sensitivity, latency profile, data intensity, and suitability for provider-native optimization.
- Connectivity model
The enterprise needs reference patterns for private interconnects, routing, DNS, service exposure, and network trust boundaries.
- Control plane model
It must be clear where policies are authored and enforced: centrally, federated by domain, or through a hybrid approach.
A realistic example is a global manufacturer that keeps SAP-centric finance workloads in one cloud because of established operational tooling, places product telemetry analytics in another cloud with stronger large-scale data services, and requires both environments to use the same enterprise identity provider, logging taxonomy, and privileged access model. That is multi-cloud architecture. By contrast, three divisions each choosing a different provider with no shared control standards is merely multi-cloud sprawl.
It is equally important to define what enterprise multi-cloud is not. It is not a requirement that every application run on every provider. It is not a mandate to duplicate every service across clouds. Nor is it an excuse to relax enterprise standards in the name of autonomy. A workable definition accepts asymmetry: some clouds are primary, some secondary; some controls are global, some jurisdiction-specific; some services are shared, while others are owned by individual domains.
The practical value of a clear definition is that it turns multi-cloud from a broad aspiration into an executable architecture model. Once workload placement, connectivity, and governance boundaries are defined, later decisions about security, integration, resilience, and cost can be made consistently rather than one exception at a time.
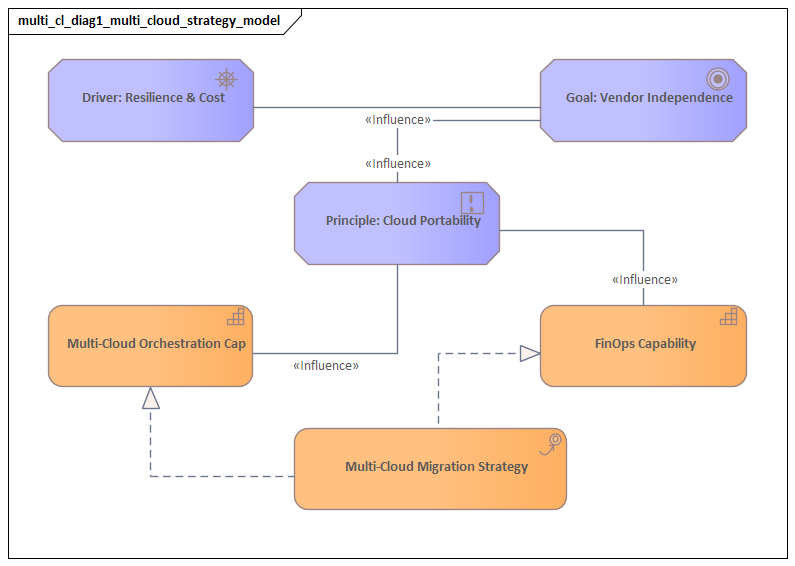
2. Business Drivers and Strategic Objectives
Enterprises adopt multi-cloud for business reasons, not because using multiple providers is inherently desirable. The architecture should therefore begin with clear strategic objectives that explain why governed distribution is necessary and what outcomes it is expected to deliver.
Resilience and concentration risk
A common driver is reducing dependence on a single provider. Executive concern usually extends well beyond rare catastrophic outages. It includes regional capacity constraints, service degradation, pricing shifts, contractual leverage, and overreliance on one vendor’s roadmap. Even so, this does not mean every workload should run active-active across clouds. The more useful question is which systems create unacceptable business interruption if they are tightly coupled to one provider, and what resilience pattern is proportionate for each. EA governance checklist
For example, a retailer may keep its e-commerce front end and order orchestration in one primary cloud, while maintaining a tested recovery capability for critical product catalog and payment-routing functions in a second cloud. That is very different from duplicating the entire digital estate everywhere at any cost.
Regulatory and jurisdictional adaptability
Global enterprises frequently operate under multiple legal regimes, each with its own requirements for data residency, auditability, sector-specific control frameworks, and operational sovereignty. Multi-cloud can provide flexibility by allowing regulated workloads or region-specific services to be placed where compliance is easier to achieve. Cloud choice, in that sense, becomes part of compliance design. It should be tied directly to data classification, encryption ownership, logging retention, and cross-border transfer rules.
A bank, for instance, may process customer onboarding data for one jurisdiction in a sovereign cloud region while using a different provider’s global analytics platform for anonymized fraud modeling. The architectural challenge is not simply placement. It is ensuring that data boundaries, audit evidence, and access controls remain coherent across both environments.
Access to differentiated capabilities
No provider is equally strong in every area. One may offer stronger analytics services, another better edge capabilities, and another more mature AI tooling or industry-specific platforms. Multi-cloud allows enterprises to match business capabilities with the providers that support them best. But the benefit only materializes when specialization is bounded by common standards. Without that discipline, differentiated capability quickly becomes fragmented architecture.
Commercial flexibility
Multi-cloud can improve negotiating position and preserve future options. That benefit does not come from spreading workloads thinly across every available provider. It comes from making deliberate decisions about where to remain loosely coupled and where to optimize deeply. Some components should preserve relocation options; others can accept tighter provider dependence because the business value is clear and the switching risk is understood.
Mergers, acquisitions, and federated operating models
Many enterprises become multi-cloud by inheritance rather than design. Acquisitions, regional autonomy, and decentralized business structures often produce a mixed cloud estate long before an enterprise strategy exists. In those cases, immediate consolidation is rarely realistic. A more effective approach is to establish common identity, security baselines, network trust boundaries, and portfolio visibility first, then rationalize platforms over time. Multi-cloud architecture, in other words, is as much an operating model as it is a hosting model.
These drivers can be summarized as a small set of strategic objectives:
- reduce concentration risk
- satisfy jurisdictional and regulatory constraints
- access differentiated provider capabilities
- preserve commercial choice
- integrate diverse technology estates under one governance model
When those objectives are stated clearly, architecture decisions become easier to govern. Workload placement, control design, and platform investment can then be judged against business intent rather than against abstract preferences for “more cloud choice.”
3. Core Architectural Principles and Operating Model
If the business drivers explain why multi-cloud is needed, architectural principles explain how it can remain coherent. The most important principle is straightforward: standardize the capabilities that create enterprise control; specialize the capabilities that create business advantage.
Principle 1: Policy consistency over tool uniformity
Enterprises do not need identical tools in every cloud, but they do need consistent outcomes. Access control, encryption, logging, backup, vulnerability management, and compliance evidence should meet the same enterprise standard, even when implemented through different provider-native services. Chasing surface-level tool uniformity often adds cost without improving control.
Principle 2: Abstraction at the right level
Too much abstraction strips away the benefits of cloud-native services. Too little produces fragmentation. The better approach is selective abstraction. Identity federation, secrets handling, certificate management, service taxonomy, observability standards, and deployment guardrails should be consistent. Beneath that layer, teams may use provider-native databases, analytics platforms, messaging services, or AI services where there is a clear case for doing so.
Principle 3: Explicit workload anchoring
Every major system should have a defined primary cloud and a documented reason for that placement. This avoids a common anti-pattern in which applications become operationally split across providers without clear ownership of latency, failure handling, or recovery design. Cross-cloud interactions should be treated as intentional integration points, not as the default shape of the architecture.
A useful micro-example is a claims platform in the insurance sector: policy administration remains anchored in one cloud close to core transactional data, while catastrophe-risk modeling runs in another cloud with specialized high-performance analytics services. The integration is deliberate and asynchronous. The system is not “half in one cloud and half in another” by accident. ArchiMate in TOGAF ADM
Principle 4: Federated delivery within central guardrails
Most enterprises need a model that combines central standards with domain autonomy. A central architecture or platform engineering function defines reference architectures, landing zones, connectivity, and security baselines. Product or domain teams build and operate workloads within those guardrails. The model works because it balances enterprise consistency with local accountability.
Operating model implications
These principles point to a product-oriented platform model. Shared capabilities should be delivered as reusable services rather than through manual approvals:
- environment provisioning
- identity integration
- network connectivity
- observability onboarding
- secrets and certificate services
- compliant CI/CD templates
- approved reference patterns for APIs, events, and data exchange
This reduces friction and allows governance to scale through adoption rather than through review boards alone. In practice, an architecture board might approve Kafka as the standard pattern for cross-cloud business events while allowing teams to use provider-native messaging services within a single cloud where no enterprise integration is required.
Enterprises also need a clear control plane model. A centralized control plane offers stronger visibility and standardization. A federated control plane gives regions or business units more autonomy. Many organizations settle on a hybrid model: centralized policy intent with federated implementation. The right choice depends on organizational structure, regulatory distribution, and platform maturity, but accountability boundaries need to be explicit.
Without an operating model, the principles remain theoretical. With one, multi-cloud becomes a repeatable enterprise platform rather than a collection of provider-specific practices.
4. Designing for Interoperability, Portability, and Integration
Multi-cloud discussions often blur three distinct ideas: interoperability, portability, and integration. In practice, they serve different purposes and should be treated differently in architecture decisions.
Interoperability as the default objective
For most enterprises, interoperability matters more than portability. Most systems do not need to move freely between clouds, but they do need to exchange data, events, identities, and operational signals reliably. That requires standardization at the boundaries between systems:
- API contracts
- event schemas
- identity assertions
- encryption approaches
- logging formats
- service naming and metadata conventions
Where cross-cloud interaction is expected, these standards should be as provider-neutral as practical.
Integration patterns that reduce fragility
Cross-cloud synchronous calls should be used with care. They introduce latency, network dependency, and troubleshooting complexity. In many situations, asynchronous patterns are more resilient:
- event streaming
- message queues
- change data capture
- scheduled or batch-based exchange
Consider a healthcare example: patient appointment booking runs in one cloud close to regional applications, while enterprise reporting and capacity forecasting run in another. Rather than chaining synchronous API calls across clouds for every update, the booking platform publishes appointment events to a shared stream, and downstream services consume them asynchronously. The result is simpler failure handling and cleaner operational ownership.
These approaches reinforce explicit workload anchoring by allowing each workload to remain centered in its primary cloud while still participating in enterprise-wide processes.
Portability applied selectively
Portability should be driven by business value, not ideology. Containers, Kubernetes, and infrastructure-as-code can improve transferability, but they do not automatically make managed databases, IAM models, or operational tooling portable. Architects should therefore define portability where it matters most.
A practical approach is to establish portability tiers:
- High portability: for regulated products, externally distributed platforms, or workloads with uncertain future placement.
- Moderate portability: for services packaged consistently but still using some provider-native platform services.
- Low portability / optimized native use: for workloads where provider-specific advantages justify tighter coupling.
This tiered model prevents overengineering portability for systems that do not need it.
Integration architecture as the execution layer
Interoperability and portability only become real through integration architecture. Enterprises need reference patterns for:
- API exposure and gateway strategy
- event routing and schema governance
- data synchronization and replication
- identity federation and machine-to-machine trust
- telemetry correlation across clouds
Operational integration matters as much as technical integration. If logs, traces, and incident data remain trapped inside provider-specific silos, the architecture may be technically connected but still operationally opaque.
The aim is to make cross-cloud dependencies intentional, observable, and economically justified. Interoperability provides cohesion, portability preserves selected options, and integration turns both into day-to-day architecture.
5. Security, Governance, Risk, and Compliance Across Clouds
Security and governance become harder in multi-cloud environments not simply because providers differ, but because risk often emerges at the boundaries between them. Identity trust chains, logging coverage, encryption ownership, and configuration management can all fail in the gaps, even when each cloud is well secured on its own. Enterprises therefore need a cross-cloud control framework built around consistent outcomes rather than identical implementations.
A layered control model
A practical model separates controls into three layers:
- Global controls: enterprise identity standards, privileged access management, data classification, minimum logging, encryption policy, incident escalation.
- Platform-specific controls: how each provider implements those outcomes through native services or approved tooling.
- Workload-specific controls: additional requirements based on business criticality or regulation.
This mirrors the broader principle of selective standardization: control intent stays consistent, while implementation varies where necessary.
Identity as the primary control plane
Identity and access management is the most important unifying layer. Human access should flow through federated enterprise identity with strong authentication and tightly governed privileged access. Non-human identities deserve the same attention. Service accounts, workload identities, API credentials, and certificates should all be managed through common standards, even if the underlying mechanisms differ by provider.
A common modernization step is to replace long-lived local cloud accounts with federated enterprise identity, short-lived privileged access, and workload identities for service-to-service authentication. That reduces standing access and makes audit trails more consistent across providers.
Policy enforcement architecture
Governance should combine preventive, detective, and corrective controls:
- Preventive: approved landing zones, hardened templates, segmentation defaults, policy-as-code in pipelines
- Detective: continuous configuration assessment, asset reconciliation, anomaly detection, centralized compliance reporting
- Corrective: automated remediation, quarantine patterns, time-bound exception workflows
This makes governance operational rather than document-driven.
Compliance evidence and auditability
Audit readiness is often one of the first things to break in multi-cloud environments because evidence is scattered across providers. Enterprises should define a compliance telemetry model: what evidence must be collected, how long it is retained, how it maps to business services, and who owns its integrity. This is especially important in regulated sectors, where controls must be demonstrated over time, not merely asserted once.
A realistic example is a pharmaceutical company running clinical trial workloads in one cloud and corporate data services in another. Audit teams do not want two unrelated piles of evidence. They need a unified control narrative showing who accessed regulated data, how encryption keys were managed, which configurations changed, and how exceptions were approved across both environments.
Risk-based application of controls
Not every workload requires the same level of control, but every workload should be mapped to a risk profile. That profile should influence placement decisions, resilience requirements, data handling, and monitoring intensity. This ties governance back to workload classification and helps avoid both under-control and over-control.
Security and compliance across clouds work best when control design is treated as architecture, not as a review step bolted on after deployment. Common control intent, provider-aware enforcement, and shared evidence models are what make multi-cloud governable.
6. Cost Management, Performance Optimization, and Operational Resilience
Cost, performance, and resilience are often managed separately. In a multi-cloud environment, that separation usually creates bad decisions. A poorly placed workload can cost more, perform worse, and still miss recovery targets. These concerns need to be treated as one architectural trade-off space.
Cost management beyond compute pricing
The most common mistake is to focus only on compute cost. In multi-cloud environments, total cost is often driven more by:
- cross-cloud data transfer
- duplicated tooling
- redundant environments
- support model complexity
- operational labor
Cross-cloud egress can become especially expensive in data-heavy systems. Architects should minimize unnecessary inter-cloud data movement, keep processing close to systems of record, and require cost visibility by business service rather than by account or subscription alone.
Performance shaped by topology
Performance problems are usually created by architecture, not fixed later through tuning. Synchronous cross-cloud service chains, centralized data access from distant regions, and excessive mediation layers all introduce latency. A better model is workload locality: place user-facing services near users, transaction services near their data, and integration patterns where they reduce repeated long-distance calls.
Performance assumptions should also be tested rather than accepted on faith. Similar services behave differently across providers, so benchmarking, scaling thresholds, cache strategy, and storage design should be validated instead of assumed to be portable.
Resilience based on explicit failure scenarios
Multi-cloud does not automatically improve resilience. It helps only when failure scenarios are defined clearly and matched to proportionate patterns. Some systems justify cross-cloud failover. Many do not. In many cases, isolated backups, tested rebuild automation, replicated configuration state, or alternate processing modes provide better value than expensive dual-cloud active-active designs.
A practical approach is to define resilience tiers linked to:
- business criticality
- recovery time objective
- recovery point objective
- dependency tolerance
- acceptable operating cost
This helps teams choose between active-active, active-standby, single-cloud recovery, or rebuild-based approaches.
A concise example: a media company may decide that its customer subscription ledger requires near-real-time recovery in a second cloud, while its recommendation engine can be rebuilt from source data within hours. Both decisions are valid because they reflect business impact rather than architectural fashion.
Shared telemetry for ongoing optimization
To manage these trade-offs, enterprises need telemetry that combines:
- FinOps data
- application performance indicators
- dependency health
- capacity and saturation trends
- recovery test results
This supports continuous architecture review. Workload placement, scaling behavior, traffic patterns, and resilience controls should be revisited as usage and business conditions change.
The goal is disciplined optimization. Multi-cloud creates more options, but it also creates more ways to spend inefficiently, degrade performance, or overcomplicate resilience. Architecture should make those trade-offs visible and measurable.
7. Implementation Roadmap, Organizational Readiness, and Future Evolution
A multi-cloud strategy becomes credible only when it is translated into a phased implementation roadmap. In most enterprises, the problem is not defining the target architecture. It is assuming the organization can adopt that target before the necessary foundations exist.
Phase 1: Establish the baseline
The first phase should create governed landing zones for each approved provider and standardize the fundamentals:
- account or subscription structure
- tagging and service taxonomy
- identity federation
- network segmentation
- logging and key management
- policy enforcement
- canonical asset inventory
The objective at this stage is not rapid expansion. It is controlled entry into each cloud.
Phase 2: Segment the portfolio
Once the baseline is in place, workloads should be classified into transition paths. Some will remain where they are and adopt common governance. Others will be re-platformed to a preferred cloud. A smaller set may justify cross-cloud redesign because of resilience, compliance, or integration needs. This portfolio-based approach keeps attention on business value rather than migration volume.
Phase 3: Productize the platform
Shared capabilities must be delivered as reusable platform products, not left as documentation alone. These typically include:
- environment provisioning
- compliant CI/CD templates
- secrets and certificate services
- observability onboarding
- connectivity services
- approved API, event, and data patterns
This is where enterprise architecture and platform engineering need to work in close partnership. It is also where lifecycle governance becomes practical: the platform team can publish approved runtime versions, retirement dates for unsupported components, and migration deadlines for legacy integration middleware. free Sparx EA maturity assessment
Organizational readiness
Technology foundations are not enough. Teams need the skills and decision rights required to operate in a multi-cloud model, including:
- cloud financial management
- provider-specific security design
- distributed operations
- cross-platform troubleshooting
- service ownership and accountability
Architecture governance also needs to change. Review boards should move away from one-time approvals and toward continuous oversight of patterns, exceptions, and platform adoption.
Measuring progress
Implementation should be measured through operating indicators, not just milestone completion. Examples include:
- percentage of workloads deployed through approved landing zones
- proportion of services mapped to business owners
- reduction in unmanaged cross-cloud connections
- policy compliance rates
- recovery test coverage
- onboarding time to governed platforms
These indicators show whether the architecture is becoming executable in practice.
Future evolution
Multi-cloud architecture will continue to evolve toward:
- stronger policy automation
- more converged control planes
- AI-assisted operations and governance
- sovereign and industry-specific cloud options
- tighter integration with edge environments
For that reason, the roadmap should establish a durable decision capability, not just a one-time migration program. The enterprise needs to reassess workload placement, standards, and governance as business conditions and provider offerings change.
Conclusion
A successful multi-cloud architecture is not defined by the number of providers an enterprise uses. It is defined by whether the resulting environment is governable, adaptable, resilient, and economically defensible. The central principle is consistent throughout: standardize what must remain consistent, and specialize where differentiation creates value.
That principle shapes the entire strategy. It defines enterprise multi-cloud as governed distribution rather than accidental diversity. It explains why business drivers such as resilience, compliance, capability access, and commercial flexibility must be translated into explicit placement rules. It supports an operating model in which central guardrails coexist with federated delivery. It also clarifies why interoperability usually matters more than universal portability, why security must be built on common control intent, and why cost, performance, and resilience should be assessed together.
The long-term advantage of multi-cloud is not provider diversity by itself. It is the ability to place digital capabilities where they create the most business value without losing control of security, operations, or governance. That advantage comes from deliberate architecture, repeatable platform patterns, and continuous portfolio-level decision-making.
When those elements are in place, multiple clouds stop behaving like competing technical silos. They become part of one enterprise architecture.
Frequently Asked Questions
How is ArchiMate used in cloud architecture?
ArchiMate models cloud architecture using the Technology layer — cloud platforms appear as Technology Services, virtual machines and containers as Technology Nodes, and networks as Communication Networks. The Application layer shows how workloads depend on cloud infrastructure, enabling migration impact analysis.
What is the difference between hybrid cloud and multi-cloud architecture?
Hybrid cloud combines private on-premises infrastructure with public cloud services, typically connected through dedicated networking. Multi-cloud uses services from multiple public cloud providers (AWS, Azure, GCP) to avoid vendor lock-in and optimise workload placement.
How do you model microservices in enterprise architecture?
Microservices are modeled in ArchiMate as Application Components in the Application layer, each exposing Application Services through interfaces. Dependencies between services are shown as Serving relationships, and deployment to containers or cloud platforms is modeled through Assignment to Technology Nodes.