⏱ 26 min read
How We Fixed Sparx EA Repository Performance in a Government Program fixing Sparx EA performance problems
Learn how we improved Sparx Enterprise Architect repository performance in a government program by identifying bottlenecks, optimizing the database, and streamlining model access for faster, more reliable architecture work. Sparx EA training
Sparx EA performance, Sparx Enterprise Architect repository, EA repository optimization, Enterprise Architect database tuning, Sparx EA slow performance, government architecture program, EA model performance, Sparx EA troubleshooting, repository bottlenecks, Enterprise Architect best practices Sparx EA best practices
Introduction
In many government programs, a Sparx Enterprise Architect repository begins as a team tool. Over time, it can become something much more consequential: the place where architecture evidence, delivery decisions, governance records, and compliance traceability are expected to live together. At that point, it no longer behaves like a local modeling environment. It behaves like a shared enterprise service. That is usually when performance problems become visible.
The issue is seldom just that “EA became slow.” More often, poor performance signals a mismatch between repository growth and the way the platform is structured, hosted, integrated, and governed. A repository originally designed for a small architecture function may later be expected to support hundreds of users, large model packages, document generation, baseline comparisons, API-driven integrations, and stakeholders working across multiple locations. In government settings, those demands are compounded by network segmentation, security controls, constrained change windows, and tightly managed operational processes.
Performance matters because it directly affects confidence in the architecture function. If diagrams take too long to open, searches stall, or package navigation becomes unreliable, users stop treating the repository as the primary source of truth. They fall back to slide decks, spreadsheets, document libraries, and local working copies. What begins as latency soon becomes an information management problem, then a governance problem. Traceability weakens, assurance slows down, and architecture-led decision-making loses authority. how architecture review boards use Sparx EA
In the program described here, Sparx EA had become central to both delivery and oversight. The repository supported solution architecture, business process modeling, integration views, security artefacts, transition planning, and governance records across several teams. Architecture board decisions, such as whether to extend an existing case management platform or fund a new capability, were being recorded and traced in EA alongside the supporting models. Yet the way the repository was operated had not kept pace with the role it had acquired. Support arrangements, service ownership, model design practices, and performance controls still reflected an earlier and much smaller deployment.
We approached the issue as a service architecture problem, not as a narrow administration task. That meant looking across the stack: client behavior, Pro Cloud Server, database design, network path, model structure, support processes, and usage patterns. It also meant accepting that technical tuning alone would not hold if governance and modeling practices continued to generate avoidable load. architecture decision records
The result was more than a faster repository. It became a more stable and governable service, with clearer ownership, better structural discipline, and a more practical way to sustain performance over time. The sections that follow describe the context, root causes, remediation strategy, implementation approach, and the lessons that proved repeatable. The central point is simple: once an EA repository becomes a shared government capability, performance has to be managed as part of enterprise architecture.
1. Program Context, Repository Scale, and Performance Symptoms
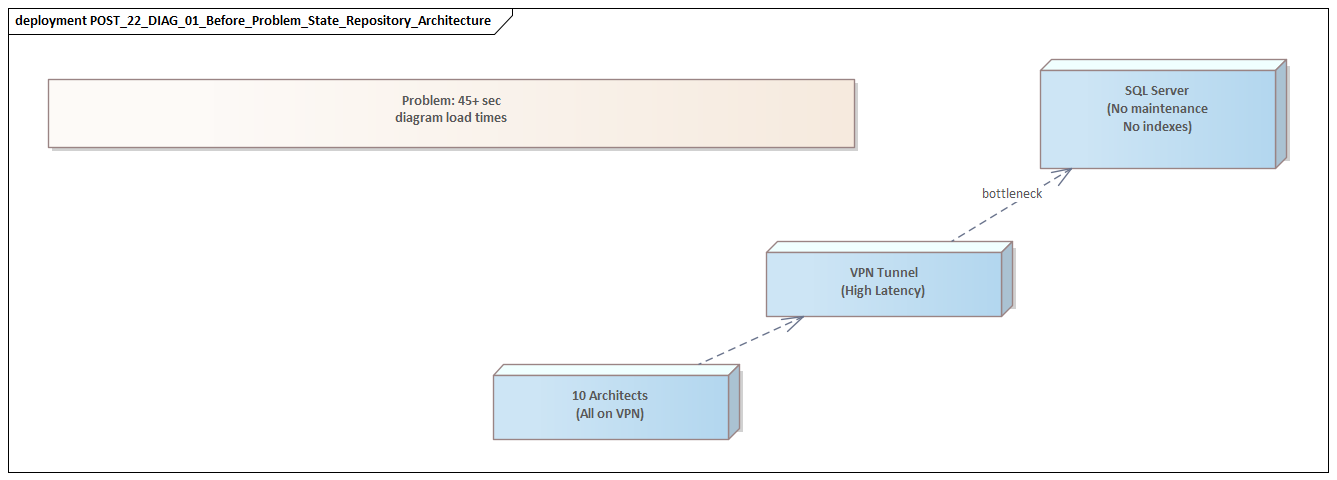
The program operated in a demanding government environment with multiple delivery streams, federated stakeholders, and a strong expectation that architecture evidence would support governance and formal assurance. Sparx EA was no longer a tool used by a small architecture team to produce static outputs. It had become a live repository for solution architectures, integration models, business processes, security viewpoints, transition states, and governance decisions. Different groups depended on the same platform, but they used it differently and expected different levels of responsiveness.
By the time concerns became difficult to ignore, the repository had grown into a large shared estate containing years of accumulated material. It held active project packages, standards libraries, reference models, reusable patterns, legacy artefacts, and archived content retained for traceability. User numbers had expanded as well. Named access now covered architects, analysts, project teams, governance participants, and delivery partners. Peak concurrency was driven less by average daily use than by governance cycles, design reviews, and release planning windows. In effect, the repository was being treated as a live operational platform, even though many support arrangements still belonged to a much smaller deployment.
Access routes were equally varied. Some users connected through thick clients on managed desktops inside restricted networks. Others relied on browser-based access or services exposed through Pro Cloud Server. Automated extracts, scripted queries, and document generation jobs added intermittent but significant load. That mattered because the user experience depended on the full transaction path, not just one component. A delay visible in the client could be rooted in network traversal, service-tier behavior, database execution, model structure, or rendering overhead. Treating everything as a database issue would have missed much of the real problem.
At first, the symptoms seemed inconsistent. Users reported delays when opening diagrams, expanding package hierarchies, running searches, moving between related elements, and generating documentation. Baseline operations and package comparisons were especially problematic during busy periods. Some actions completed eventually, but slowly enough to disrupt workshops and review boards. Others ended in timeouts, apparent client freezes, or repeated retries that only added to the load.
Not every part of the model behaved the same way. Some packages remained responsive, while others were predictably slow. That unevenness turned out to be important. It suggested that performance was being shaped not only by repository size or infrastructure capacity, but also by the way the model itself had evolved. Deep package nesting, very large diagrams, heavily connected elements, broad cross-package references, and weak archival discipline can all create localized hotspots. One IAM modernization package, for example, had accumulated current-state identity flows, target-state role models, privileged access controls, and legacy directory mappings in the same heavily linked structure. Routine navigation through that area had become expensive.
A similar pattern appeared in the integration domain. The program’s event architecture package combined Kafka topics, producers, consumers, schema definitions, environment mappings, operational controls, and support notes in one broad package tree. That view was rich and analytically useful, but it was costly to traverse interactively. In another area, technology lifecycle governance mixed current standards, exception approvals, and retired platform records in the same user path, which increased search noise and made it harder for teams to find the live position quickly. These were not dramatic design mistakes. They were ordinary accretions that became problematic at scale.
There was also a clear behavioral warning sign: teams had started working around the platform. Architects prepared diagrams in advance because live navigation in meetings felt too risky. Analysts exported lists to spreadsheets instead of relying on repository searches. Some project teams kept local records and uploaded material only when governance checkpoints required it. Those workarounds relieved immediate pressure, but they introduced duplication, delayed updates, and weakened trust in the repository as the authoritative source.
Taken together, the signs pointed to a service performance issue affecting a critical information asset. The repository had outgrown the assumptions under which it had originally been designed and operated. That became the working frame for the investigation: identify where latency was accumulating across the end-to-end service, and distinguish structural causes from incidental ones.
2. Root Cause Analysis Across EA, Database, and Infrastructure Layers
We began with one deliberate decision: not to assume that database tuning was the whole answer. In mature Sparx EA environments, the latency users experience is usually the result of several smaller inefficiencies stacking up across the client, Pro Cloud Server, the database engine, the network path, and the repository structure. Looking at one layer in isolation may improve a metric without materially improving the user experience. We therefore treated diagnosis as an end-to-end service analysis.
The first step was to classify issues by interaction type rather than by user complaint. Opening a diagram, expanding a package tree, running a search, generating a document, and comparing a baseline can all be described as “EA is slow,” but they rely on different behaviors. Some interactions are dominated by metadata retrieval. Others depend on relationship traversal, rendering, large result sets, or write-intensive comparison operations. Once we separated them in that way, patterns emerged. Some slow interactions were tied to particular model areas, while others aligned more closely with concurrency or infrastructure conditions.
At the application and repository layer, we found that model design choices were having a direct runtime effect. Certain areas had evolved into very large packages containing many diagrams, extensive relationships, and broad cross-package references. Those structures raised the cost of navigation and search because the platform had to resolve more metadata and associations than most users realized. We also found searches and scripts designed for convenience rather than efficiency. They returned larger result sets than necessary and imposed avoidable load during peak periods.
A practical example came from a service transition package used by both delivery teams and governance reviewers. It contained target-state designs, transition dependencies, RAID references, implementation notes, and approval history in one structure because that made sense from a document assembly perspective. Operationally, however, common navigation actions were forcing the platform to traverse far more content than most users needed. A user trying to open one transition roadmap was effectively pulling context from a much broader package than intended.
Pro Cloud Server emerged as the second major factor. It was not failing, but it had become a concentration point for traffic from desktop clients, web access, and integrations. Under load, inefficiencies elsewhere were amplified because expensive queries, retries, and broad package requests all moved through the same service tier. Connection behavior, request concurrency, and service configuration mattered far more than had previously been recognized. Pro Cloud Server was acting as a critical mediation layer, not simply a passive gateway.
At the database layer, the issue was cumulative query cost rather than a single dramatic bottleneck. Repository growth had changed table sizes and access patterns. Some operations were scanning more data than expected, and index usage no longer matched the way the repository was actually being used. Fragmentation, stale statistics, and uneven maintenance practices all contributed to inconsistent response times, particularly for search-heavy and comparison-heavy actions. The database was not slow across the board. It was slow for particular access patterns generated by specific user journeys. That distinction mattered because it shifted remediation away from generic server scaling and toward workload-aware tuning.
Infrastructure analysis completed the picture. Network latency between managed desktops, segmented hosting zones, and service components was not severe in isolation, but it compounded application and database delays. Security controls such as traffic inspection and constrained routing added small overheads that became visible during chatty interactions. We also found fragmented operational ownership: desktop, server, database, and network teams each monitored their own domain, but no one owned the end-to-end repository experience. As a result, there was no single operational view capable of connecting backend contention with user complaints.
The root cause was architectural misalignment. The repository had grown into a shared enterprise platform, but its service design, operating model, and stewardship had not evolved with it. What users experienced as inconsistent slowness and unreliable behavior was the visible symptom of that mismatch. The service was carrying enterprise-level demand on foundations still being managed like a departmental tool.
That conclusion shaped the rest of the work. Lasting improvement would require coordinated changes across repository structure, service configuration, database behavior, and operational accountability. A fix in only one layer was never going to be enough.
3. Governance, Usage Patterns, and Modeling Practices That Amplified the Problem
The technical findings explained where latency was occurring. They did not fully explain why the repository had become so vulnerable to it. That answer lay in governance, usage patterns, and modeling discipline. Performance had deteriorated not because a single component failed, but because the repository had been allowed to grow without equally mature controls over how content was created, organized, retained, and consumed.
One major factor was the absence of explicit repository architecture standards. The program was clear about what information should be captured in EA, but far less clear about how that information should be structured for long-term use. Different teams developed their own conventions for package decomposition, element granularity, naming, diagram density, and traceability depth. Those choices were often reasonable in local context. A project team might want all release artefacts together in one place; a domain architect might want extensive relationship mapping for assurance. Across a shared repository, however, the cumulative effect was uneven structure that was hard to navigate and expensive to query.
A related issue was the tendency to equate completeness with value. In government settings, architecture teams are often under pressure to preserve evidence for audit, assurance, and compliance. That can lead to a “keep everything live” mindset, where superseded designs, duplicate reference content, low-value working artefacts, and historical material all remain in active repository paths long after their practical value has passed. As the previous section showed, size alone was not the real problem. The deeper issue was that active and inactive content were often mixed together in ways that increased search noise, broadened navigation paths, and made optimization harder.
Usage patterns made the situation worse. Governance forums, portfolio reviews, and design checkpoints created synchronized access to the same model areas at predictable times. Instead of smooth concurrency, the service experienced bursts of concentrated demand. Many users also approached the repository in a browse-heavy way, expanding package trees and traversing relationships interactively to work out what was relevant. In a complex program, that behavior is understandable. Operationally, though, it is expensive when the repository lacks curated viewpoints, focused searches, or clear navigation paths. Users were compensating for weak information design by doing more exploratory retrieval.
Modeling practices added further strain. Some teams built very dense diagrams intended to serve several audiences at once: governance boards, delivery teams, security reviewers, and external partners. That may seem efficient from a document-production perspective, but it is inefficient in operation. Large mixed-purpose views require more rendering, more relationship resolution, and more manipulation than smaller views designed for a specific audience. Traceability was also sometimes implemented with maximal enthusiasm rather than selective intent. Creating every conceivable relationship can look rigorous, but indiscriminate linkage increases maintenance effort and traversal overhead without necessarily improving decision quality.
One security architecture package illustrated the point well. A single diagram attempted to show user journeys, trust boundaries, token flows, control ownership, privileged admin paths, and exception notes for an API gateway pattern. It was useful as a one-stop reference for a specialist reviewer, but far too dense for routine use. Opening it during a design authority session was slow enough that teams began exporting screenshots into slide packs instead of navigating the live model.
Ownership ambiguity allowed these issues to persist. Tool administrators looked after platform availability. Database teams maintained the underlying service. Architecture leads focused on content quality. But no single role was accountable for repository performance as an ongoing architectural concern. Activities such as package refactoring, archival, search optimization, and model simplification were treated as occasional clean-up exercises rather than part of normal service stewardship.
This matters because the repository had not slowed down simply because of technical scale. It had slowed down because governance and modeling practices were generating unnecessary runtime cost. That changed the remediation approach. If we improved the technology but left those practices untouched, performance would deteriorate again.
The practical lesson is clear: repository performance cannot be separated from repository governance. If EA is expected to operate as a shared enterprise capability, then standards for structure, lifecycle, traceability, and usage need to be designed with operational behavior in mind. Good performance does not come only from tuning servers. It also comes from curating the repository around the way people actually use architecture information.
4. Remediation Strategy: Repository Restructuring, Database Tuning, and Configuration Changes
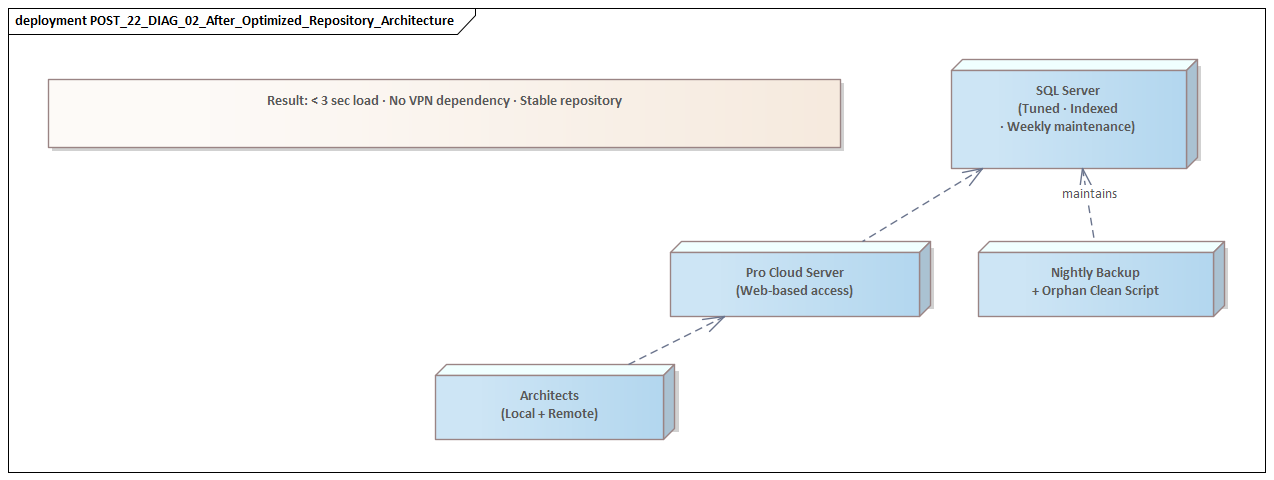
Because the causes were spread across several layers, the remediation had to be coordinated in the same way. We did not approach the problem as a string of isolated fixes. Instead, we established three parallel workstreams: repository restructuring, database tuning, and EA/Pro Cloud Server configuration changes. The goal was not only to improve response times in the short term, but to create a sustainable service baseline aligned with the repository’s actual role in the program.
4.1 Repository restructuring
The first workstream focused on repository structure and directly addressed the modeling and governance issues already described. We identified the model areas that were heavily used and treated them differently from low-value historical content. Rather than attempt a disruptive wholesale redesign, we carried out targeted refactoring where high usage and high inefficiency overlapped.
Large mixed-purpose packages were broken down into clearer domains. Archive content was separated from active working areas. Overly dense diagram sets were rationalized into smaller, audience-specific viewpoints. In practice, that meant separating live architecture board decision records from supporting discussion artefacts, splitting IAM target-state models from legacy directory mappings, and isolating Kafka event catalogues from implementation-level troubleshooting views. That reduced the amount of metadata and relationship traversal needed for common actions such as expanding packages, opening diagrams, and running focused searches.
We also introduced explicit repository design rules. These covered package depth, naming consistency, expected diagram scope, and disciplined use of cross-package relationships. The aim was not methodological rigidity. It was to create predictable boundaries so that new hotspots were less likely to emerge. Archival criteria were formalized as well, allowing superseded material to remain available for traceability without continuing to burden active navigation paths.
A useful change in practice was the introduction of “operational views” for high-traffic areas. Instead of asking users to browse through full domain structures, we created curated entry points for common tasks. In the case management domain, for example, governance reviewers could access current-state service interfaces, target-state dependencies, and open decision records through a small set of maintained views rather than through a deep package hierarchy containing every historical iteration.
4.2 Database tuning
The second workstream focused on the database, but in a targeted and workload-aware way. We reviewed indexing and maintenance against actual repository access patterns rather than relying on generic defaults. Statistics refresh, fragmentation management, and housekeeping routines were tightened so that database behavior remained more consistent over time.
These changes produced meaningful gains because they were aimed at the interactions that mattered most: package expansion, search execution, relationship lookup, and comparison-heavy activity. We also aligned maintenance windows with known usage cycles, which avoided situations where intensive housekeeping competed with governance peaks. In one case, a recurring document generation batch had been overlapping with pre-board preparation periods; rescheduling it removed a predictable source of contention without any infrastructure uplift.
The lesson was straightforward: enterprise repositories benefit more from workload-aware tuning than from broad, undifferentiated infrastructure uplift.
4.3 EA and Pro Cloud Server configuration
The third workstream focused on service and client behavior. We adjusted Pro Cloud Server settings to better support concurrent access and reduce avoidable request accumulation under load. Integrations were reviewed to ensure that automated extracts and scripted activities were not competing directly with interactive users during the busiest periods. Where needed, jobs were rescheduled, constrained, or rewritten to be less disruptive.
Client-side practices also needed attention. Default behaviors that encouraged broad retrieval were reviewed, and users were guided toward narrower searches, curated views, and more efficient navigation paths. That mattered because some of the repository load had been created by users compensating for weak information design. Better structure and better usage guidance had to reinforce each other.
4.4 Incremental delivery and measurement
One important architectural decision was to implement changes incrementally and measure the effect of each wave. In a controlled government environment, that reduced delivery risk and made it easier to separate genuine improvement from anecdotal impressions. It also built confidence. Platform teams could see the effect of service and database changes, while architects could see the benefit of repository refactoring in real user journeys.
The overall result was not a repository that became instantly fast in every scenario. Large shared architecture estates will always include heavier operations. What changed was consistency and predictability. The service became more responsive where it mattered most, and users could rely on it again for business-critical interactions. That is the standard enterprise architects should aim for: not perfect speed everywhere, but dependable performance aligned with decision-making and governance needs.
5. Implementation in a Government Environment: Controls, Constraints, and Change Management
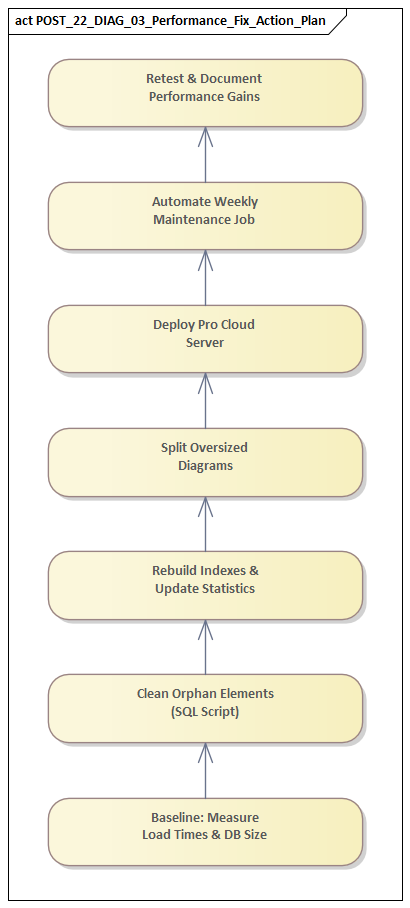
Designing the remediation was only half the challenge. Implementing it in a government program demanded equal attention to controls, assurance, and change management. Even a technically sound solution would have limited value if it could not be approved, scheduled, or supported within the operational environment.
The first implementation principle was to frame the work as a controlled service change rather than a tool enhancement. That mattered because infrastructure teams, security authorities, and change boards were more willing to support interventions expressed in terms of user impact, service resilience, rollback planning, and measurable outcomes than in terms of product-specific tuning. Positioning the repository as a critical service created a stronger basis for governance approval.
The second principle was sequencing. In tightly governed environments, large bundled changes increase both approval complexity and diagnostic risk. We therefore grouped the remediation into logical waves: low-risk configuration updates, improved database maintenance, targeted repository refactoring, and then changes affecting integrations or scheduled jobs. Each wave had a clear hypothesis, an expected outcome, and a validation method. That made implementation safer and gave stakeholders confidence that progress could be assessed in manageable increments.
Controls also affected how we handled repository restructuring. Architecture content in government programs is often linked to approval records, assurance evidence, and audit trails. Moving or archiving packages therefore has business implications, not just technical ones. We had to preserve traceability, maintain integrity where necessary, and ensure that users could still find authoritative artefacts after structural changes. In practice, that meant defining migration rules, validating revised navigation paths, and confirming that governance workflows still operated correctly against the new structure.
Stakeholder management was just as important. Different groups experienced the repository differently and judged the remediation through different lenses. Platform teams prioritized stability. Database teams focused on workload predictability. Security teams cared about configuration compliance. Architecture practitioners cared about usability and continuity. To avoid fragmentation, we established a small cross-functional decision forum with enough authority to resolve trade-offs quickly. Without that, the effort would likely have stalled between teams that each owned part of the environment but not the end-to-end outcome.
A practical example involved an architecture board package that mixed live decision records, supporting assessment notes, and historical options analysis. Governance users wanted faster access to current decisions during meetings. Assurance stakeholders wanted the full context preserved. The compromise was to create a lean operational path for current board use while retaining the detailed evidential material in a linked but less frequently traversed archive structure. That pattern proved useful elsewhere.
User change management also needed deliberate attention. Performance initiatives often disappoint because users continue the habits they developed under degraded conditions. If teams remain accustomed to exporting content, avoiding live access, or relying on old package paths, technical improvements alone will not restore the repository’s role. We therefore paired technical changes with practical usage guidance: what had changed, where active and archived content now lived, which searches were preferred, and how to access information more efficiently. This was not abstract training. It was adoption support tied directly to the redesigned service.
Another lesson was the importance of evidence. In controlled environments, anecdotal claims that something “feels faster” are not enough. We needed measurable before-and-after indicators tied to the business-critical interactions identified earlier. That evidence was essential for gaining approval, validating success, and securing support for further refinement. It also helped establish a more mature operational baseline for ongoing stewardship.
The broader architectural point is that non-functional improvement has to be governed like any other architectural change. Performance, usability, and operational sustainability are service qualities, and in government settings they have to be delivered through controlled transition. The implementation succeeded not because controls were relaxed, but because the remediation was designed to work within them.
6. Results, Lessons Learned, and a Repeatable Performance Playbook
The most immediate result was not simply a faster repository. It was a repository dependable enough to use confidently in live governance and delivery settings again. Users could open key diagrams, navigate priority model areas, and run common searches with much greater consistency during normal working periods. Peak-time behavior improved as well. Governance boards and architecture review sessions no longer had to assume that live repository access was risky, which reduced dependence on pre-generated extracts and offline workarounds.
A second result was improved operational predictability. Before the intervention, performance complaints were difficult to interpret because each support team saw only part of the problem. Afterward, the service had clearer baselines, clearer ownership boundaries, and a better shared understanding of which interactions generated disproportionate load. That made triage easier and created a stronger foundation for ongoing service management.
Several lessons stood out.
First, repository performance is a lagging indicator of architectural discipline. By the time users experience serious latency, the underlying causes usually include years of accumulated structural complexity, weak lifecycle management, and unmanaged consumption patterns. Performance optimization should not be treated as a one-off recovery exercise. It needs to be part of normal repository stewardship.
Second, optimization is most effective when it is tied to user journeys rather than technical components. The most useful questions were not “Is the server healthy?” or “Is the database large enough?” but “Can an architect retrieve the evidence needed for a review quickly enough?” and “Can a governance forum move from principle to solution impact without delay?” Those questions connect technical work directly to decision-making effectiveness.
Third, active and retained content need to be separated deliberately. Traceability does not require every historical artefact to remain in the most heavily traversed paths. The repository worked better once current operational use and long-term evidential retention were treated as related but distinct concerns.
Fourth, repository governance and technical operations have to be linked. Poor structure and weak usage discipline create avoidable runtime cost. The reverse is also true: good standards, lifecycle controls, and curated navigation improve performance just as surely as tuning does.
From this work, we developed a repeatable playbook for other large Sparx EA environments: Sparx EA guide
- Define business-critical interactions. Identify the user journeys that matter most, such as opening governance diagrams, running key searches, generating review evidence, or navigating traceability paths.
- Measure those interactions end to end. Look across client, service, database, network, and repository structure rather than isolating one layer.
- Find hotspots by usage value. Focus first on areas that are both heavily used and structurally inefficient.
- Separate active from retained content. Preserve traceability without forcing archived material to remain in active operational paths.
- Tune against observed workload. Adjust indexing, maintenance, and service settings based on actual access patterns rather than generic defaults.
- Control integration load. Ensure scripts, extracts, and automated jobs support rather than compete with interactive use.
- Establish clear ownership. Assign accountability for repository performance as a service, covering both technical and information architecture dimensions.
- Sustain the gains. Review model growth, usage behavior, and service baselines regularly so that performance management becomes continuous.
The broader lesson is that EA repositories should be run as enterprise information platforms. Their effectiveness depends on the interaction of content design, platform engineering, and operational governance. When those disciplines are aligned, performance improves as a by-product of good architecture. When they are disconnected, slowness is often the first visible symptom of a deeper design problem.
Conclusion
This experience reinforced a simple point: once a Sparx EA repository becomes embedded in governance and delivery, it is no longer just a modeling tool. It becomes critical shared infrastructure. At that stage, performance cannot be managed reactively through occasional tuning or ad hoc clean-up. It has to be designed into the repository’s structure, operating model, and ownership.
What made the remediation successful was not any single technical adjustment. It was the decision to manage the repository as a governed service. That perspective brought together platform engineering, information architecture, usage behavior, and change control into one coherent operating model. The program gained not only better response times, but also stronger traceability, more reliable governance, and clearer stewardship.
For enterprise architects, the practical message is direct: treat repository performance as an indicator of architectural health. Design for high-value user journeys, separate active and retained content, tune based on real usage, and assign explicit accountability across architecture and platform teams. In government programs especially, that discipline is essential if architecture is to remain usable, trusted, and operational at scale.
Frequently Asked Questions
Why does a large Sparx EA repository get slow?
Large Sparx EA repositories slow down due to a combination of relationship density, unbalanced package structures, oversized diagrams, customisation overhead (add-ins, scripts, event handlers), and infrastructure limits. The problem is rarely the database alone — it is the interaction of model size, topology, and workload.
How do you fix Sparx EA performance problems?
Start with diagnosis: classify which user journeys are slow, measure response times as a baseline, and identify hotspot packages and diagrams. Then address root causes: split large packages, refactor oversized diagrams, audit and prune add-ins, tune database indexes, and review Pro Cloud Server configuration.
What is the ideal Sparx EA repository architecture for large enterprises?
For large enterprises, the recommended setup is a centralised SQL Server or PostgreSQL database, deployed behind a Sparx Pro Cloud Server instance, with a domain-driven package hierarchy, explicit ownership per domain, defined package-level security, and a scheduled maintenance routine for index optimisation and archive management.