⏱ 25 min read
Integration Architecture Patterns from Real Enterprise Projects | Practical Enterprise Integration Guide Sparx EA guide
Explore proven integration architecture patterns from real enterprise projects, including API-led connectivity, event-driven architecture, ESB modernization, hybrid integration, and system interoperability best practices. Sparx EA best practices
integration architecture patterns, enterprise integration, API-led connectivity, event-driven architecture, enterprise architecture, ESB modernization, hybrid integration, system interoperability, real enterprise projects, integration design patterns, application integration, distributed systems architecture, middleware strategy, legacy system integration, technical architecture how architecture review boards use Sparx EA
Introduction
Integration architecture is where enterprise ambition meets operational reality. Most organizations run a mixed estate of ERP platforms, SaaS products, legacy applications, data platforms, partner interfaces, and custom services. Each may perform well in isolation, but business value appears only when information and processes move reliably across those boundaries. Integration is therefore not just a technical concern. It affects agility, compliance, customer experience, resilience, and the cost of change.
In active transformation programs, integration decisions are rarely made under ideal conditions. Architects inherit overlapping platforms, inconsistent data definitions, fragmented ownership, and years of point-to-point interfaces. A pattern that looks elegant in a workshop can become fragile in production once it encounters transaction spikes, regulatory controls, vendor API limits, poor data quality, or weak operational support. In practice, sound integration architecture depends less on fashion and more on selecting patterns that fit business intent, organizational maturity, and long-term maintainability. free Sparx EA maturity assessment
It is more useful to think of enterprise integration as a portfolio of patterns than as a single standard. Synchronous APIs, asynchronous messaging, event-driven flows, batch movement, file exchange, and data replication all have legitimate roles. Customer-facing interactions may require low-latency APIs. Financial reconciliation is often better served by controlled batch processing. Operational notifications frequently fit event publication. Mature enterprises do not force every use case into one model; they apply the pattern that best fits the job.
Non-functional concerns are just as important as interface design. Security boundaries, observability, idempotency, versioning, replay, schema evolution, and support ownership often determine whether an integration remains viable over time. An interface can be technically correct and still become an enterprise liability if it is difficult to monitor, expensive to scale, or fragile when upstream systems change.
This article examines integration architecture through the lens of delivery rather than theory alone. It begins with the strategic role integration plays in transformation, then moves through the patterns architects encounter most often in practice: legacy integration styles, API-led connectivity, event-driven architecture, data integration, and hybrid or multi-cloud connectivity. It closes with a practical framework for choosing patterns based on trade-offs, governance, and delivery realities. The aim is not to offer a universal blueprint, but to provide a structured basis for making better decisions in complex enterprise environments.
The Strategic Role of Integration Architecture in Enterprise Transformation
Enterprise transformation is usually described in business terms: improve customer experience, simplify operations, modernize platforms, reduce cost, or respond faster to regulation. Beneath those goals sits a familiar dependency. Systems must exchange information and coordinate behavior across organizational and technical boundaries. Integration architecture becomes strategic because it determines whether transformation can happen safely and incrementally, or whether every change becomes a risky replacement exercise.
Few enterprises transform from a blank slate. Core systems remain in place for sound reasons: regulatory certification, embedded business rules, operational familiarity, or the sheer cost of migration. New capabilities are usually introduced around those systems rather than replacing everything at once. Integration architecture makes that coexistence possible. It allows legacy capabilities to be exposed through stable interfaces, digital services to connect to core transaction engines, and business processes to evolve without requiring a single disruptive cutover. Sparx EA training
That makes integration a control point for change. Deliberate interface design separates business consumption from implementation detail. A capability such as pricing, onboarding, order status, or product availability can be exposed through a defined contract even while the underlying application changes. This is why enterprises need a portfolio of patterns rather than a single style. The architecture must support both the target state and the untidy transition toward it.
The point becomes sharper when transformation roadmaps move from slides to delivery. Describing a future-state architecture is relatively easy; getting there without interrupting operations is not. In practice, integration enables coexistence between old and new master data sources, dual-running during migration, event capture from legacy platforms, and façade services that shield consumers from backend replacement. In one insurance program, the architecture board approved a policy administration replacement only after channel traffic was first moved to a stable policy API. Web and broker channels were therefore insulated from the core migration, and release risk dropped materially.
There is also a financial dimension. Poorly governed interfaces create hidden costs: duplicated logic, brittle dependencies, repeated remediation, and fragmented support. A well-structured integration layer lowers the marginal cost of future change. Reusable contracts, shared security patterns, common observability, and clear ownership improve delivery efficiency across programs. Over time, that value compounds. Each integration becomes more than a project artifact; it becomes part of the enterprise’s capacity to adapt.
Real programs also show that integration exposes governance weaknesses quickly. Data ownership disputes, inconsistent definitions, unclear accountability for services, and fragmented support models often surface first at integration boundaries. For that reason, architects should treat integration not only as a technical discipline, but also as a mechanism for enterprise alignment. Decisions about ownership, latency expectations, contract stewardship, and failure handling are closely tied to the operating model.
In the end, integration architecture matters strategically because it shapes resilience as much as change. Enterprises dealing with mergers, policy shifts, partner onboarding, or new digital channels need an architecture that can absorb structural change without widespread redesign. Patterns built around explicit contracts, traceability, and controlled evolution make that possible. In that sense, integration architecture is not just part of transformation delivery; it is one of the main ways strategy becomes executable.
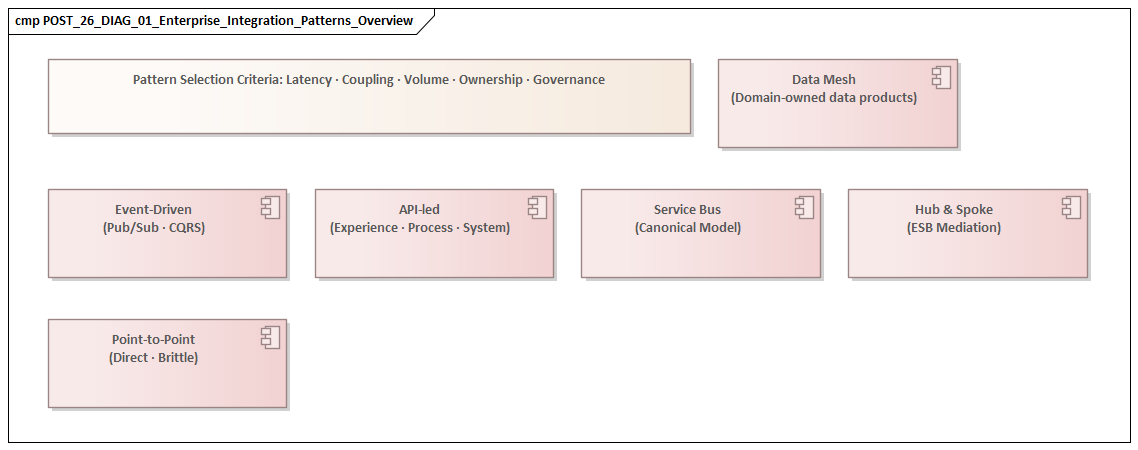
Legacy Integration Patterns: Point-to-Point, Hub-and-Spoke, and ESB
One of the clearest ways to understand enterprise integration maturity is to examine how patterns have evolved. In many legacy estates, integration began with point-to-point connections built to solve immediate business needs. A warehouse system needed product updates from ERP. A billing platform needed customer data from CRM. A reporting tool required extracts from finance. These interfaces were often quick to implement and easy to justify in isolation. The problem appeared later, when dozens or hundreds of direct connections produced a tightly coupled estate in which any system change carried broad regression risk.
Point-to-point integration is not inherently poor design. Direct integration can be entirely appropriate when there are only a few stable dependencies, especially where latency matters and the interaction is simple. The lesson from enterprise programs is that the pattern becomes hazardous when it grows without architectural limits. Each direct connection tends to embed assumptions about data structure, timing, ownership, and error handling. As those assumptions drift apart, visibility declines, impact analysis slows, and support teams become dependent on tribal knowledge.
Hub-and-spoke models emerged as a response to that complexity. Instead of every application connecting directly to every other one, systems integrated through a central broker or integration hub. This reduced the number of physical connections and created a place to standardize routing, transformation, protocol mediation, and monitoring. In many enterprises, the hub marked the first serious attempt to treat integration as an enterprise capability rather than a collection of project-specific scripts.
Its main advantage was control. Architects could define onboarding standards, centralize message tracking, and simplify partner connectivity. The hub also allowed legacy applications with limited integration capabilities to participate in broader flows through centrally managed adapters. The trade-off, however, was equally real. The hub could become both an operational bottleneck and an organizational one. When every integration required central team involvement, delivery slowed, knowledge concentrated in a few specialists, and the platform itself became a monopoly dependency.
The enterprise service bus extended that model. ESBs were positioned not only as transport brokers, but as strategic middleware for transformation, orchestration, mediation, and policy enforcement. In heterogeneous estates, they often delivered real value by providing a consistent runtime layer across packaged applications, legacy systems, and emerging services. ArchiMate modeling guide
The strongest lesson from ESB-heavy environments is that centralization must be handled carefully. In many organizations, too much business logic migrated into the bus: complex transformations, routing rules tied to organizational structure, and process logic that belonged elsewhere. The result was a powerful but opaque middleware layer that was difficult to test, document, and change. In one manufacturing estate, a central ESB ended up holding plant-specific routing rules for orders, inventory reservations, and shipment notifications. When a new distribution center opened, three teams had to untangle bus logic no one fully owned. The pattern had delivered standardization, but at the cost of transparency.
The enduring principle is simple: the integration layer should mediate and expose capabilities, not become the hidden home of enterprise process behavior.
Taken together, these legacy patterns reflect different balances of speed, control, and coupling. Point-to-point favors speed at small scale. Hub-and-spoke improves manageability. ESB adds broad mediation and standardization. In modernization work, the architect’s task is not to dismiss these patterns outright, but to decide which existing integrations still serve their purpose, which should be simplified, and which should be decomposed into clearer API- or event-based models.
API-Led Connectivity: Reuse, Governance, and Scale
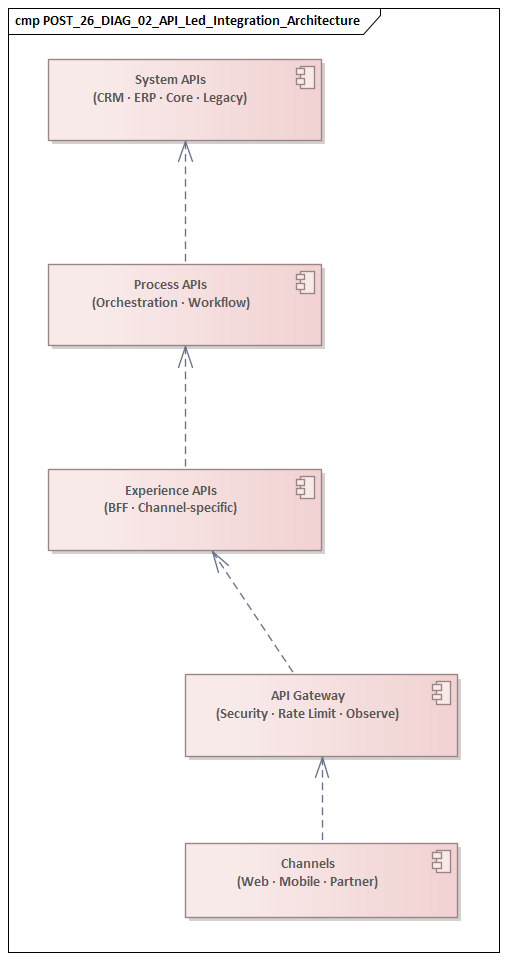
API-led connectivity gained traction in large enterprises because it offered a more disciplined way to expose business capabilities across complex delivery landscapes. Its value is not simply that systems can call each other over HTTP. More importantly, it creates a contract layer that separates consumers from backend complexity, supports reuse across channels, and gives architects a manageable way to scale integration.
A common enterprise model organizes APIs into layers with distinct responsibilities. System APIs provide controlled access to core applications or data stores, shielding consumers from proprietary protocols and unstable backend schemas. Process APIs coordinate multiple interactions around a business activity such as onboarding, fulfillment, or claims handling. Experience APIs tailor those capabilities for specific channels such as web, mobile, partner, or internal operations. This layered approach works because it creates a clear reuse boundary: backend access is implemented once, while channel-specific variation is handled closer to the point of use.
That structure is especially useful during platform change. If a backend application is replaced, upstream consumers can often remain stable while the system API changes behind the contract. Likewise, a new channel can reuse existing process logic instead of duplicating orchestration. The architecture does not remove coupling altogether, but it localizes change and makes dependencies more intentional.
Reuse in API programs is often misunderstood. Not every API should be designed for universal use. Over-generalization leads to bloated contracts, awkward versioning, and interfaces that serve no consumer particularly well. In practice, reusable APIs emerge where business capability boundaries, ownership, and semantics are already clear. A better principle is purposeful reuse: expose stable capabilities where multiple consumers genuinely share the same need, and avoid abstraction for its own sake.
Governance is where many API programs succeed or fail. At scale, the problem is usually not too few APIs, but too many with too little control. Without governance, enterprises accumulate duplicate services, inconsistent naming, incompatible security models, and undocumented dependencies. Effective governance includes design standards, lifecycle rules, discoverability through a catalog, versioning policy, and explicit ownership for both runtime support and semantic stewardship.
Security modernization often becomes the forcing function for that discipline. In one IAM program, an enterprise replaced application-specific service accounts with OAuth2 and centralized token validation at the API gateway. That removed duplicated authentication logic from dozens of services, reduced audit findings, and gave the architecture board a clear standard for new integrations. The technology change mattered, but the architectural gain came from standardization and enforceable policy.
At runtime, API-led architecture must deal with scale in more than one sense. Rate limits, token propagation, timeout strategy, caching, and protection against cascading failure all belong in the design. Many API problems in large enterprises come not from poor contract design, but from weak resilience engineering. A well-structured API portfolio can still fail under peak load if call chains become too deep, synchronous dependencies are overused, or tracing does not reveal latency hotspots across domains.
The strongest API-led programs align APIs with business capabilities rather than organizational charts or application menus. When that alignment is in place, APIs become more than technical endpoints. They form a stable contract layer through which enterprises can modernize systems, support multiple channels, and onboard partners without recreating the hidden coupling that older integration models often produced.
Event-Driven Architecture in Practice
Event-driven architecture becomes valuable when the business needs systems to react to change without being tightly bound to one another at runtime. Instead of one application calling another directly for every downstream action, a source publishes an event that something meaningful has happened: an order was placed, a payment failed, an address changed, or a shipment was dispatched. Other systems subscribe and respond according to their own responsibilities. The model shifts integration away from direct command-style interaction and toward asynchronous propagation of business state changes.
The advantage is not limited to runtime decoupling. It also creates organizational decoupling. As long as event contracts remain compatible, teams can evolve consumers independently. New subscribers can often be added without changing the publisher. That makes event-driven patterns especially useful in high-change domains such as customer activity, order lifecycle, logistics status, and operational monitoring.
As with APIs, contract quality determines whether the pattern succeeds. A common failure mode is publishing low-level technical messages that expose internal table changes or processing steps rather than meaningful business facts. Those events force consumers to understand the publisher’s internal design and create brittle dependencies. Stronger models define events around durable business significance. “Customer contact details updated” is usually a better enterprise contract than a message that exposes every field mutation in a CRM table.
Event-driven integration also changes the consistency problem rather than removing it. Architects need to be explicit about where immediate consistency is required and where eventual consistency is acceptable. Inventory reservation during checkout may still require synchronous confirmation. Notifications, analytics, compliance reporting, and downstream enrichment may not. Trouble starts when event-driven designs are applied to processes that still depend on immediate global agreement, or when stakeholders assume asynchronous flows will behave like transactions.
Operational design matters just as much. Event brokers can absorb spikes and isolate temporary outages, but only if consumers are built for replay, idempotency, duplicate handling, and poison-message management. Delayed delivery, duplicate messages, and out-of-order arrival are normal conditions in enterprise messaging, not rare edge cases. Architects therefore need retention policies, dead-letter handling, correlation identifiers, durable subscriptions, and end-to-end observability from publisher to consumer.
A retail platform offers a typical example. Teams used Kafka to publish OrderPlaced and StockAdjusted events across commerce, warehouse, and analytics domains. The architecture board approved Kafka as a production backbone only after schema registry controls, compatibility checks, and replay testing were made mandatory. That decision prevented teams from treating the broker as an informal data pipe and forced them to manage event contracts as enterprise assets.
Ownership is equally important. Every event should have a clear producer accountable for schema evolution, publication quality, and semantic clarity. Consumers should own their own state and avoid hidden assumptions about timing or sequencing. Once multiple domains start publishing at scale, event catalogs, schema registries, and compatibility rules become essential. They play much the same role for event-driven architecture that API governance mechanisms play for service-based integration.
Used well, event-driven architecture increases agility without requiring central orchestration of every interaction. It is particularly effective for business notifications, distributed workflow progression, extensibility around core transactions, and operational intelligence. It is not, however, a universal answer. Like APIs, it works best when used deliberately, with clear semantic boundaries and operational discipline.
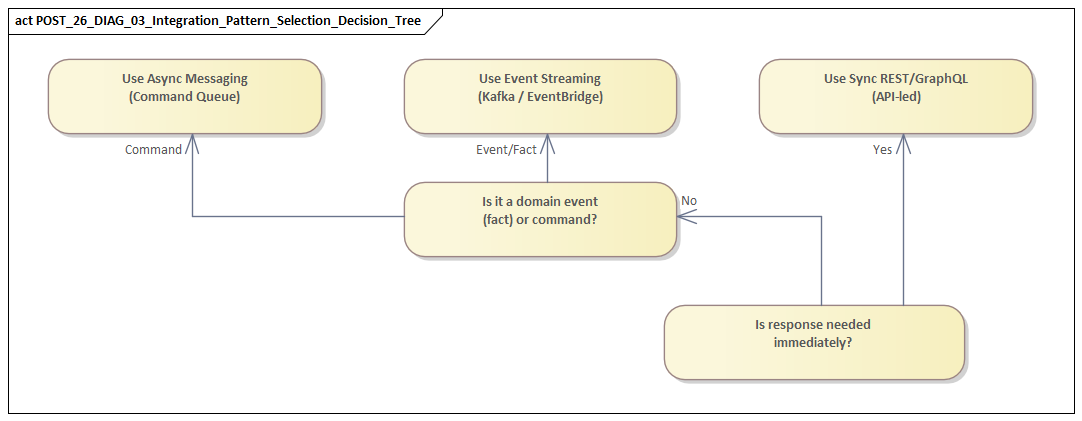
Data Integration Across Operational and Analytical Platforms
Data integration presents a different challenge from application integration, even though some patterns overlap. Operational systems are built for transaction integrity, process control, and accurate current state. Analytical platforms are built for historical analysis, cross-domain aggregation, and decision support. The issue is not simply how to move data between them, but how to do so in a way that creates analytical value without destabilizing operational systems or reproducing source-system confusion downstream.
The most traditional pattern is scheduled batch extraction. Data is copied at defined intervals into a warehouse, lakehouse, or reporting platform. This remains effective for finance, regulatory reporting, and management dashboards where periodic refresh is acceptable and reconciliation control matters. Its strengths are predictability and auditability. Its weakness is latency.
To reduce that delay, many organizations introduce incremental movement through change data capture. Instead of repeatedly extracting full datasets, the architecture propagates inserts, updates, and deletes as they occur. CDC improves timeliness and reduces reporting load on source systems. It is especially useful where core applications cannot tolerate heavy analytical queries or where several downstream consumers need consistent feeds.
CDC should not be mistaken for semantic integration. Like low-level events, CDC often reflects source-system structure rather than business meaning. If it is used without downstream modeling, quality controls, and business harmonization, it simply copies operational complexity into analytical platforms. That is one of the most common mistakes in enterprise data integration.
Another pattern is mediated integration through an operational data store or a shared integration layer. This can be useful when multiple operational sources need to be combined before analytics can consume them, or when reporting teams need a stable, cleansed view insulated from volatile application schemas. The advantage is better control over harmonization, reference data alignment, and survivorship rules. The risk is that the intermediate layer becomes yet another platform with no clear purpose or owner. It works best when it is defined as a specific integration asset for agreed use cases, not as a vague “single source of truth.”
Modern enterprises increasingly add streaming ingestion for time-sensitive insight. Event- or log-based feeds can push operational changes into analytical platforms within seconds or minutes, enabling fraud detection, supply chain visibility, near-real-time monitoring, and behavioral analysis. But fast pipelines demand more operational discipline than many programs expect. Late-arriving data, schema drift, reconciliation between streaming views and curated history, and continuous pipeline support all require active design.
A banking example illustrates the point. One institution introduced CDC from its payments platform into a cloud analytics environment to support fraud scoring within minutes rather than overnight. The pipeline succeeded technically, but the first release produced conflicting transaction counts because downstream teams had treated operational updates as final business events. Only after reconciliation rules and conformed payment states were introduced did the feed become reliable for enterprise use.
Across all of these patterns, the central principle is that data integration should be designed around information products, not just pipelines. Downstream consumers may need raw replicated data, conformed business entities, curated metrics, or regulatory-grade reconciled outputs. Different needs justify different patterns and different levels of control. A machine learning team may accept rapidly landed raw data, while finance may require lineage, balancing, and strict auditability.
This reinforces a broader point seen throughout the article: ownership and semantics matter as much as transport. Successful data integration depends on explicit decisions about source ownership, refresh expectations, transformation accountability, and enterprise meaning across domains. When those decisions are unclear, organizations accumulate duplicated pipelines and conflicting reports. When they are clear, operational and analytical platforms can evolve separately while still supporting a coherent information landscape.
Hybrid and Multi-Cloud Integration
Hybrid and multi-cloud integration has become a defining feature of enterprise architecture. Core systems may remain on-premises, customer engagement may run on SaaS platforms, analytics may span multiple cloud providers, and operational technology may process data at the edge. The challenge is not just connectivity. It is coordination across environments with different trust models, latency characteristics, operational controls, and vendor constraints.
A recurring lesson from enterprise projects is that hybrid integration should not be designed as though all endpoints are equally reachable or equally governable. SaaS platforms come with API quotas, release schedules, and access constraints. On-premises systems may depend on private networks, maintenance windows, and legacy protocols. Edge environments may have intermittent connectivity and local processing requirements. Architects who treat those differences as secondary details usually end up with brittle integrations.
A more durable approach is to classify integration paths by network reliability, security boundary, throughput pattern, and ownership model. This is the hybrid version of the same principle used throughout the article: start with business and operational constraints, then choose the integration style.
One common model uses a cloud-based integration layer to connect SaaS applications with enterprise services while keeping sensitive internal systems behind controlled ingress points. APIs, brokers, or managed integration services may run in the cloud, while access to internal platforms is mediated through gateways, connectors, or relay components. This supports policy enforcement, credential isolation, and traffic inspection. It also creates a manageable control point for support and audit. The trade-off is potential dependence on proprietary connectors or cloud-specific services that may be difficult to unwind later.
Multi-cloud adds another layer of complexity. Enterprises often spread workloads across providers to reduce concentration risk, but unmanaged multi-cloud can simply recreate fragmentation in a different form. Identity models differ. Network patterns differ. Managed messaging services differ. Observability becomes inconsistent unless it is designed deliberately. In practice, a workable architecture usually defines a small set of cross-cloud standards: identity federation, encryption principles, portable interface contracts, centralized integration metadata, and trace correlation that survives provider boundaries.
Edge integration raises a different set of concerns. In sectors such as manufacturing, retail, logistics, healthcare, and field operations, data often has to be processed locally because latency, bandwidth, or resilience requirements make constant cloud dependency impractical. The integration pattern typically combines local event handling or store-and-forward mechanisms with periodic synchronization to central systems. The key design question is what must happen locally and what can wait for central consolidation. Safety actions, local inventory updates, or device control may require immediate local processing, while enterprise analytics and reconciliation can happen later.
Operational accountability also changes in hybrid landscapes. Incidents may involve enterprise teams, SaaS vendors, cloud providers, and network services at the same time. Traditional support boundaries break down quickly in that environment. Mature architectures therefore include end-to-end monitoring across managed and self-hosted components, cross-environment runbooks, and service-level definitions based on the weakest dependency in the chain rather than the strongest.
The broader lesson is straightforward: hybrid and multi-cloud integration is not a temporary exception. For most enterprises, it is the long-term operating model. The goal is not to make every environment identical, but to apply consistent principles for trust, connectivity, observability, and change across a diverse landscape.
Choosing the Right Pattern: Trade-Offs, Governance, and Delivery
Choosing an integration pattern is rarely a matter of selecting the technically purest option. The better question is which pattern creates the right balance between business responsiveness, delivery risk, operational supportability, and long-term adaptability. In practice, the wrong choice is often not a bad technology in itself, but a pattern whose assumptions do not match the business need or the organization’s ability to operate it.
A practical evaluation starts with a small set of architectural dimensions. First, interaction criticality: does the business process require immediate confirmation, or can it tolerate delay? Second, change frequency: are the systems stable, or are they evolving across multiple teams and vendors? Third, transaction coupling: must several steps succeed together, or can downstream actions be separated safely? Fourth, operational burden: can the organization realistically support replay, monitoring, contract management, and failure recovery for the chosen model?
These questions usually narrow the options faster than product comparisons. Synchronous APIs may look straightforward, but they can create deep runtime dependency chains and increase the risk of cascading failure. Event-driven integration improves decoupling, but it demands stronger semantic discipline and greater operational maturity. Batch integration may seem less modern, yet it is often the most controllable and auditable option for reconciled, high-volume workloads. File exchange also remains valid in regulated or partner-heavy contexts where scheduled handoff and contractual traceability matter more than low latency.
Governance should vary by pattern. Centralized approval may be justified for external partner interfaces, regulated exchanges, or enterprise event standards where inconsistency creates high risk. Internal domain APIs or team-owned event streams often benefit more from federated governance, where standards are set centrally but lifecycle decisions remain with accountable product teams. The principle is proportional governance: enough control to prevent fragmentation, but not so much that teams work around it.
Many enterprises now aim for a platform-and-guardrails model. Central architecture or integration teams provide shared capabilities such as gateways, brokers, schema tooling, security patterns, reference designs, and observability standards. Delivery teams then build within those constraints rather than depending on a central team for every implementation. This works best when guardrails are clear, automatable, and measurable. Standards that exist only in documents tend to erode quickly.
Technology lifecycle governance belongs in this discussion as well. Integration platforms have a habit of lingering long after strategic decisions have moved on. An enterprise may standardize on modern APIs and event brokers while still carrying unsupported file gateways, aging ESB runtimes, or custom adapters that no one wants to retire because they continue to function. In one global logistics firm, the architecture board introduced a simple lifecycle model—strategic, tolerated, containment, and retire—for integration technologies. That gave delivery teams a practical basis for investment decisions and stopped “temporary” middleware from becoming permanent by default.
Delivery realities should shape pattern selection just as much as architecture diagrams do. Architects need to consider how an integration will be tested across environments, how contract changes will be introduced, how rollback will work, and who will own incidents in production. Many failures begin not in the design itself, but in release sequencing, missing test data, unclear support transitions, or underestimated coordination across teams.
The most effective pattern choices are documented as explicit architectural decisions. That means recording why a pattern fits the use case, which trade-offs were accepted, what level of governance applies, and which operational capabilities are required. An architecture board may approve Kafka for domain events but reject its use for request-response integration, or allow a legacy file transfer to remain in place for a regulated partner feed until both controls and retirement dates are defined. This creates consistency without turning architecture into dogma.
Conclusion
Integration architecture is one of the clearest indicators of whether an enterprise can change with control or only through disruption. The central lesson from real projects is not that one pattern always wins, but that different patterns succeed in different contexts when they are applied deliberately and supported properly.
Across legacy modernization, API-led connectivity, event-driven integration, data movement, and hybrid connectivity, the same theme recurs: integration choices must be tied to business purpose, ownership, and operational reality. Poorly designed integrations hide coupling, spread inconsistency, and turn every transformation step into a negotiation. Well-designed integrations reduce the impact of change, support coexistence, and make future substitution or expansion possible.
Integration architecture is also inseparable from the operating model. Interface ownership, semantic stewardship, support boundaries, and funding for shared platforms shape outcomes just as much as protocols or middleware do. Enterprises that treat integration as a product capability, with lifecycle management and measurable controls, are consistently more resilient than those that treat it as project plumbing. The same is true of technology lifecycle governance: teams need clear rules for when integration products are introduced, standardized, contained, or retired, rather than allowing obsolete gateways, brokers, and adapters to persist indefinitely.
The goal is not architectural purity. It is to build an integration landscape that remains understandable, governable, and adaptable under real business pressure. For enterprise architects, that means making trade-offs explicit, designing for transition as well as target state, and ensuring that every chosen pattern is backed by the controls required to run it in production. In that sense, integration architecture is not just about connecting systems. It is about enabling the enterprise to evolve without losing coherence.
Frequently Asked Questions
What are the main enterprise integration architecture patterns?
The main patterns are: API-led integration (Experience, Process, System API tiers), event-driven integration (publish-subscribe via a broker like Kafka), request-reply for synchronous transactions, batch/bulk transfer for high-volume data, and point-to-point for simple or legacy cases. Choosing the right pattern depends on latency, coupling, reliability, and volume requirements.
How is integration architecture modeled in ArchiMate?
In ArchiMate, Application Components represent integrated systems, Application Services represent exposed capabilities, Application Interfaces represent endpoints, and Serving relationships show which components provide services to which consumers. Technology interfaces model the underlying protocols and middleware.
Why is integration architecture important in enterprise EA?
Integration is where most enterprise complexity and risk concentrates. Poorly governed integrations create brittle dependencies, data quality problems, and cascading failures. Modeling the integration landscape enables impact analysis before changes are made and makes hidden dependencies visible to governance and delivery teams.