⏱ 22 min read
Event-Driven Architecture for Cloud Platforms: Principles, Patterns, and Best Practices enterprise cloud architecture patterns
Explore event-driven architecture for cloud platforms, including core principles, design patterns, scalability benefits, integration strategies, and implementation best practices for modern distributed systems. hybrid cloud architecture
event-driven architecture, cloud platforms, cloud architecture, distributed systems, event-driven systems, microservices, asynchronous communication, event streaming, message brokers, cloud-native architecture, scalable systems, real-time processing, architecture patterns, system integration, enterprise architecture free Sparx EA maturity assessment
Introduction
Event-Driven Architecture (EDA) has become a core pattern for cloud platforms because it reflects how distributed systems actually operate. Services scale independently. Failures are often partial rather than total. Business change moves across many applications, teams, and platforms at different speeds. Instead of coordinating every interaction through synchronous request-response calls, EDA organizes systems around events: records of facts that have already occurred, such as PaymentAuthorized, UserRegistered, or OrderConfirmed. Producers publish those facts, and consumers react asynchronously.
That distinction matters in modern cloud environments, where enterprise platforms rarely consist of a few isolated applications. They span microservices, managed cloud services, SaaS platforms, data pipelines, analytics platforms, mobile and edge channels, and increasingly machine learning or AI components. When these parts are tied together primarily through direct synchronous calls, dependencies multiply quickly. A change in one service can delay another team’s release, expose brittle runtime assumptions, or trigger cascading failure. Event-driven interaction reduces that coupling by allowing producers to publish business or technical facts without knowing which systems will consume them later. multi-cloud architecture strategy
For enterprise architecture, the benefit is not only technical. It is organizational. Teams can own services, schemas, and processing logic within clear boundaries while still participating in shared business processes. Identity, billing, order management, fraud, and observability domains can exchange information continuously without depending on one another’s immediate availability. In one IAM modernization program, for example, the identity domain published UserProvisioned and AccessRevoked events. HR systems, directory services, and SaaS onboarding automations subscribed independently, which eliminated a large set of fragile point-to-point integrations and reduced onboarding changes from weeks to days.
EDA is not, however, a matter of installing a broker and declaring success. A workable cloud platform depends on deliberate choices about event ownership, event types, delivery guarantees, schema evolution, security boundaries, retention, replay, and observability. Architects need to distinguish between queues used for work distribution, topics used for pub/sub integration, and streams used as durable event history. They also need to design for realities that synchronous systems often hide: duplicate delivery, backlog growth, partial failure, lag, replay, and eventual consistency. integration architecture diagram
Handled well, EDA becomes more than an integration style. It becomes a platform capability that helps enterprises scale services independently, evolve systems safely, and respond to business change in near real time. The sections that follow examine the concepts, patterns, design practices, operating controls, and governance disciplines required to make event-driven cloud platforms reliable at enterprise scale.
Principles and Core Concepts
At the center of EDA is a simple idea: systems should react to facts rather than coordinate constantly through commands. An event describes something that has already happened. A command asks for something to happen. The distinction sounds small, but it has major architectural consequences. When teams use event channels as disguised remote procedure calls, they reproduce the same tight coupling EDA is supposed to eliminate.
The first principle, then, is loose coupling across time, location, and implementation. Producers and consumers should not need to be active at the same moment, know one another’s addresses, or share internal design assumptions. That separation allows services to scale unevenly, tolerate transient outages, and evolve without synchronized releases. In cloud platforms, this is one of the main reasons event-driven interaction is so effective.
A second principle is clear event semantics. Events should be named in business language and should represent meaningful state changes. InvoiceIssued, SubscriptionCancelled, and ShipmentDelivered are useful because they describe facts that other domains can understand. By contrast, names such as RowUpdated or WorkflowStep3Completed expose implementation details. Consumers that depend on those details constrain the producer’s ability to change its internal design.
A third core concept is the difference between event notification and event-carried state transfer. With notification, the producer signals that something changed and consumers retrieve additional data separately if needed. With event-carried state transfer, the event includes enough context for consumers to act without a follow-up call. Notification keeps messages small, but it often reintroduces synchronous dependency. Event-carried state gives consumers more autonomy, but it requires stronger schema discipline and clearer data governance. This trade-off appears repeatedly in enterprise EDA design.
EDA also changes how architects think about delivery and ordering. In most cloud platforms, delivery is at least once, not exactly once across the whole system. Duplicates are normal. Ordering is usually guaranteed only within a partition or key, not across all events globally. Consumers therefore need to be idempotent, partition strategies need to be chosen carefully, and ordering guarantees must be applied only where they are genuinely required.
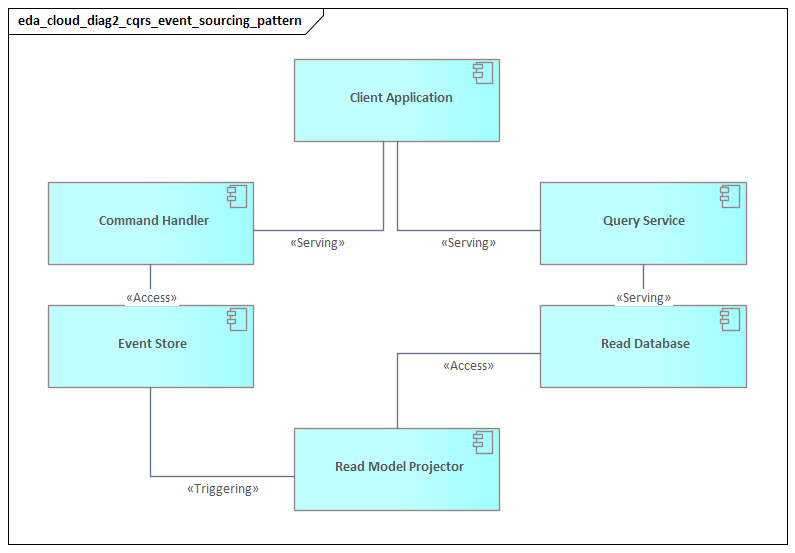
Another important concept is replayability. Some event platforms retain history so that new consumers can bootstrap from earlier events, failed consumers can recover, and analytics or audit functions can reconstruct business activity. Replay is powerful, but it is not free. It requires retention rules, schema compatibility, and controls to prevent reprocessing from causing unintended side effects. A finance platform, for instance, may replay InvoiceIssued events into a new reporting service, but it must ensure those same events do not accidentally trigger duplicate customer notifications or downstream settlement steps.
EDA also benefits from an explicit event taxonomy. In enterprise environments, it is useful to distinguish among:
- Domain events, which describe facts meaningful within a bounded business context
- Integration events, which expose selected facts for cross-domain use
- Technical or system events, which describe platform conditions such as deployment changes, policy violations, or infrastructure failures
This classification clarifies ownership and reduces event sprawl. It also supports cataloging and governance. In one architecture review, a team was permitted to keep detailed RoleAssignmentChanged events inside the identity domain, while external consumers received only a simplified AccessChanged integration event. The decision preserved internal flexibility without denying the enterprise a usable business signal.
Finally, EDA introduces a different view of consistency and process flow. Rather than assuming that a single synchronous transaction completes an entire business process, architects model processes as a sequence of observable state transitions. Consistency across services is often eventual rather than immediate. Long-running processes may require sagas, compensating actions, or explicit orchestration. That does not make systems less reliable. It makes their coordination model more realistic for distributed cloud environments.
Taken together, these ideas—facts over commands, loose coupling, clear semantics, delivery realities, replay, taxonomy, and eventual consistency—form the foundation for every later design choice in an event-driven cloud platform.
Architectural Patterns and Platform Components
Once the fundamentals are clear, the next task is selecting patterns that fit the business flow and operating model. Strong event-driven platforms rarely rely on a single messaging style. In practice, they combine several patterns, each suited to a different kind of interaction.
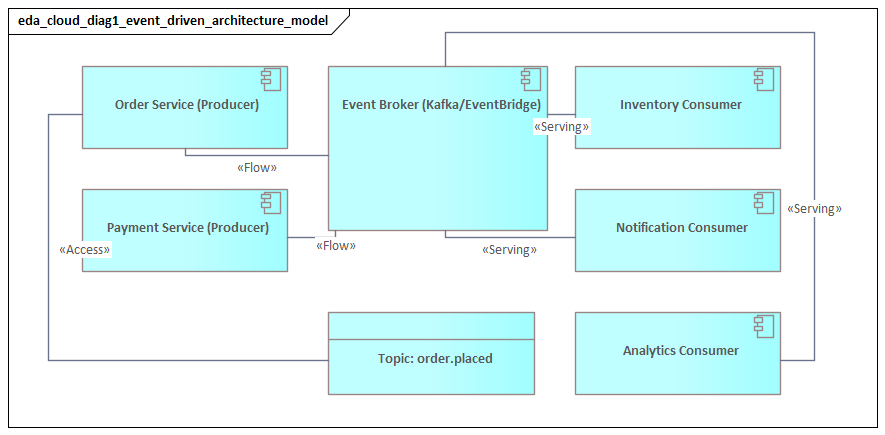
Pub/Sub for broad distribution
The most familiar pattern is publish/subscribe. A producer emits an event to a topic or event bus, and multiple consumers subscribe independently. This works well when the same business fact should trigger several reactions. A CustomerRegistered event, for example, might initiate profile creation, fraud checks, consent preference setup, and analytics updates.
Pub/sub is attractive because it preserves loose coupling. New consumers can be added without changing the producer. The same flexibility, though, creates governance pressure. Architects need to decide who may subscribe, which events are internal versus enterprise-wide, and how schemas are validated. Without those controls, pub/sub can become an unmanaged dependency network.
Queues for work distribution
A second pattern is queue-based competing consumers, where messages represent units of work rather than shared business facts. This is common in document processing, image transformation, batch enrichment, and fulfillment tasks. The queue smooths demand and supports horizontal scaling of workers.
In cloud environments, this pattern is particularly useful because compute can scale with backlog. It also introduces operational concerns: visibility timeouts, retry behavior, poison messages, and dead-letter handling. A document ingestion service that receives 50,000 files after month-end close may scale workers rapidly, but if malformed files are retried indefinitely, the queue becomes a source of operational instability rather than resilience.
Streams for durable history
A third pattern is the event streaming backbone. Here, events are stored in ordered logs and consumed at different speeds by operational services, analytics platforms, and downstream data products. This pattern matters when history is as important as notification. It supports replay, state reconstruction, stream processing, and near-real-time integration with data platforms.
A common enterprise example is Kafka used as the shared backbone for order, payment, and customer lifecycle streams, with separate consumers for operational services, fraud analytics, and lakehouse ingestion. Because these platforms retain history, they also require stronger controls for retention, replay, and schema compatibility.
Transactional publishing patterns
One of the most practical problems in EDA is ensuring that business state changes and event publication remain consistent. The standard answer is the transactional outbox pattern. A service writes its business update and an outbound event record in the same local transaction, and publication happens asynchronously afterward. This avoids the classic failure case in which the database commits but the event never leaves the service.
In more mature environments, change data capture may externalize outbox records into streams automatically. The implementation choice varies by platform, tooling, and audit requirement. The architectural objective stays the same: reliable event publication without distributed transactions.
Choreography and orchestration
For multi-step business processes, architects typically choose between choreography and orchestration.
- In choreography, services react to one another’s events without a central controller.
- In orchestration, a workflow engine or coordinator tracks state and directs the next step.
Choreography preserves domain autonomy and works well when services can respond independently. Orchestration is better suited to long-running processes, deadline-driven flows, or scenarios with strict traceability and compensation rules. Most enterprises use both. What matters is making process ownership explicit rather than hiding orchestration logic inside a web of consumers.
Core platform components
These patterns depend on a broader set of platform capabilities:
- Event broker, bus, or streaming platform
- Schema registry
- Event catalog
- Dead-letter channels
- Observability stack
- Access control and encryption services
- Optional stream processors, event gateways, and connectors
These are not optional accessories. They are part of the platform itself. If every project assembles them differently, consistency and governance erode quickly. Standardized platform services make it far easier for teams to apply event-driven practices safely and repeatedly.
Designing Event Flows, Schemas, and Integration Boundaries
If patterns define how events move, design discipline determines what those events mean. Poor event design recreates the same coupling problems found in poor API design, only less visibly and often later in production.
Event flow mapping
The first step is to map where events originate, who owns them, and which ones should cross domain boundaries. Not every internal state change deserves to become an enterprise event. A useful rule is that boundary-crossing events should represent business-significant facts that other domains can rely on without understanding the producer’s internal workflow.
For example, OrderValidated may be an internal milestone within order processing, while OrderConfirmed is a more appropriate integration event for billing, fulfillment, and customer communication. The difference is not cosmetic. The first leaks workflow mechanics; the second communicates a fact with stable business meaning.
Designing schemas that support autonomy
Schemas should be understandable outside the producer team and stable enough to support independent consumer evolution. They should carry enough context for downstream use, but they should not become replicas of the producer’s internal data model.
A practical schema structure separates:
- Business payload: the domain fact being communicated
- Metadata: event ID, type, source, timestamp, correlation ID, causation ID, schema version, and classification
This metadata is not decorative. It supports tracing, replay control, auditability, and operational diagnosis. At enterprise scale, missing metadata becomes a recurring source of ambiguity during incidents and audits.
Schema evolution
Because consumers move at different speeds, schema change must be managed carefully. In most cases, additive and backward-compatible change is the safest path. Removing fields, changing meanings, or reusing event names for different semantics creates hidden breakage in asynchronous systems.
A mature platform supports schema evolution through:
- Registry-based validation
- Compatibility rules
- Contract testing
- Lifecycle states such as draft, approved, deprecated, and retired
The purpose of this governance is not to slow delivery. It is to let teams change safely without coordinated releases.
Integration boundaries
One of the most important architectural choices is deciding what a domain publishes externally. Events should expose a domain’s published business facts, not its database structure, exception details, or transient internal states. If a team emits events that mirror table updates, consumers become coupled to implementation details and data model churn.
A better approach is to define a published event model aligned to bounded contexts and business language. That often requires translation between internal events and external integration events, but the translation preserves long-term autonomy. It also allows internal processing to evolve without breaking enterprise consumers.
Enrichment strategy
Architects also need to decide where enrichment should occur. If every consumer must call the producer for reference data, the system drifts back toward synchronous dependency. If the producer embeds every possible downstream attribute, the event becomes bloated and unstable.
A practical middle path is to publish the minimum shared business context in the core event, then perform specialized enrichment through stream processors or mediation services where there is a clear need. A retail platform might publish OrderConfirmed with customer ID, order value, and fulfillment method, while a downstream loyalty stream enriches it with tier status for campaign processing. The core event stays stable; the specialized view remains local to the consumer use case.
Control boundaries
Event design should define not only data boundaries but also control boundaries. Some events are authoritative and may trigger automated business action. Others are advisory, informational, or intended only for analytics. If those distinctions are not explicit, teams may build critical processing on signals that were never intended to carry operational commitment.
Effective event design therefore connects semantics, ownership, and usage policy. Without that alignment, the platform may move data efficiently while still failing as an enterprise integration model.
Scalability, Resilience, and Operational Excellence
The earlier sections explain why EDA creates decoupling and how event flows should be designed. In production, however, success depends on how the platform behaves under load, fault, and change.
Scalability as backlog management
In event-driven systems, scalability is not simply a matter of adding consumers. It is a matter of managing backlog, latency, and burst behavior. Buffers absorb spikes, but they are not infinite. Architects should define acceptable thresholds for queue depth, lag, event age, and processing time for each flow.
Fraud screening may require near-real-time processing, while downstream reporting can tolerate delay. Those business differences should shape partitioning, consumer concurrency, and autoscaling rules. CPU and memory are not enough as scaling signals. Event-native indicators such as lag, oldest unprocessed message, retry rate, and throughput per partition are often more meaningful.
Partition strategy and hot spots
As noted earlier, ordering is usually guaranteed only within a partition or key. That makes partition design critical. Poor key selection can create hot partitions and throughput bottlenecks. Tenant IDs, timestamps, or skewed business identifiers often look sensible early on and then produce uneven load in production.
Architects should evaluate partition strategy early, balancing ordering requirements against throughput distribution. In some cases, composite keys or controlled randomization are needed. A Kafka-based order platform, for example, may partition by orderId to preserve per-order sequencing while avoiding a single hot customer account key that would otherwise throttle the stream.
Failure containment
Failures in EDA often appear as growing lag, retry storms, blocked partitions, or dead-letter accumulation rather than as immediate outages. That makes failure containment essential. Consumer groups should be isolated where appropriate. Retry policies should be bounded. External calls inside consumers should use timeouts and circuit breakers.
Dead-letter channels deserve particular attention. They are not merely storage for bad messages. They require ownership, triage procedures, alerting, and replay controls. Otherwise, they become a quiet form of data loss.
Idempotency and duplicate handling
Because at-least-once delivery is common, consumers must tolerate duplicates. Idempotency should therefore be treated as a standard design requirement rather than an optimization. Depending on the use case, that may involve deduplication keys, state checks, version comparisons, or business-safe update patterns.
This follows directly from the delivery model described earlier. A platform that assumes perfect delivery will fail unpredictably under normal cloud conditions.
Graceful degradation
Not all consumers are equally critical. Some delays are acceptable; others are not. Architects should classify event flows by business criticality and define fallback modes. Recommendation updates may be delayed with limited impact. Fraud decisions, payment events, or identity revocation signals usually require stronger guarantees and faster recovery.
That classification informs resource isolation, failover design, and incident response. In mature platforms, high-priority event paths are protected from lower-value analytics or notification workloads to reduce contention.
Observability for asynchronous systems
Traditional request tracing is not enough in asynchronous environments. Operators need to reconstruct flows across brokers, stream processors, serverless functions, and long-running consumers. That requires standardized correlation IDs, causation tracking, and lineage metadata.
Useful dashboards should show:
- Events published versus processed
- Consumer lag
- Time to consume
- Retry and dead-letter rates
- Replay counts
- Compensation activity for long-running flows
These metrics reveal silent failures that API-centric monitoring often misses.
Progressive delivery and runtime controls
Changes to producers, schemas, and consumers should be introduced gradually. Canary releases, compatibility checks, synthetic event testing, and shadow consumers reduce the risk of asynchronous defects surfacing late. Runtime governance should also enforce quotas, retention rules, access policies, and encryption defaults.
Operational excellence in EDA comes from treating the event platform as a product with service objectives, support processes, and continuous improvement loops. Brokers alone do not create resilience.
Security, Governance, and Compliance
Events are durable integration assets, not transient implementation details. That makes security and governance central concerns rather than afterthoughts.
Access control beyond the API mindset
In synchronous systems, control is often concentrated at API gateways. In EDA, the control surface is broader. Producers, topics, queues, stream processors, archives, and replay tools all matter. Topic-level permissions are necessary but often insufficient, particularly when multiple event types with different sensitivity levels share infrastructure.
Architects should combine identity-based controls with data classification and least-privilege access. Highly sensitive event flows may need dedicated channels. Shared infrastructure should not imply shared trust. This is especially relevant in IAM modernization, where access events may contain role, entitlement, or privileged account information that should not be broadly replayable.
Data protection and minimization
Encryption in transit and at rest is only the baseline. Event design must also support payload minimization, field-level protection, and the avoidance of embedded secrets. Sensitive personal or financial data should appear in events only when there is a clear business need and an approved retention model.
A common pattern is to publish broadly usable reference identifiers in shared events while restricting full sensitive context to tightly controlled services. This aligns with the earlier trade-off between notification and event-carried state transfer: more payload increases consumer autonomy, but it also increases governance burden.
Ownership and stewardship
Every enterprise event should have a named owner responsible for schema quality, classification, retention, and consumer communication. Without ownership, event catalogs turn into passive inventories rather than governance tools.
A lightweight governance workflow should require new events to declare:
- Business purpose
- Data classification
- Authoritative source
- Retention period
- Cross-domain usage expectations
This becomes particularly important when events are reused for analytics, AI training, or partner integration beyond their original operational purpose.
Retention and replay policy
Replay is one of the major advantages of event platforms. It is also a governance challenge. Some events must be retained for audit or regulatory evidence. Others should expire quickly to reduce privacy exposure and legal liability. Replay rights should be controlled carefully: which event classes are replayable, by whom, under what approval, and with what masking or filtering.
Technology lifecycle governance also matters here. An architecture board may allow a legacy broker to remain only for noncritical workloads, while requiring all new replay-dependent integrations to use the strategic streaming platform with managed retention and audit controls.
Traceability and auditability
Enterprises increasingly need to prove not only that controls exist, but how a business fact moved through the platform. Event metadata should therefore support lineage, producer identity, timestamps, classification, and jurisdiction where relevant. Logs from brokers, registries, and stream processors should feed centralized audit models.
This traceability supports compliance, incident response, and forensic investigation. It also shows where operational and governance concerns intersect.
Governance as platform capability
The most effective governance is built into the platform itself: policy-as-code, schema validation gates, automated classification checks, key management integration, and environment guardrails. The goal is not to centralize every approval. It is to create governed self-service.
In cloud-scale EDA, security and compliance are strongest when they are embedded in platform defaults rather than left to project-by-project interpretation.
Adoption Strategy, Organizational Impact, and Common Pitfalls
EDA adoption usually fails when it is treated as a one-time technology rollout. It succeeds when introduced incrementally around business flows that benefit clearly from asynchronous interaction.
Start with event-worthy domains
Good starting points are domains with frequent state changes, multiple downstream consumers, and independent scaling needs: order lifecycle, customer onboarding, billing status, fraud signals, or operational telemetry. Not every interaction belongs in EDA. Some capabilities still require synchronous APIs for immediate validation or confirmation.
EDA is part of an interaction portfolio, not a universal replacement for APIs.
Build platform capability early
Teams should not have to invent event conventions from scratch. A reusable platform should provide standard event templates, schema lifecycle controls, publishing patterns, observability defaults, and reference implementations for outbox publishing, dead-letter handling, and replay.
This is where platform services become organizational accelerators. Standardization reduces accidental diversity and allows domain teams to focus on business semantics rather than infrastructure assembly.
Redefine ownership
EDA changes accountability. Producer teams do not stop at publishing an event; they own a long-lived contract. Consumer teams cannot assume perfect timing or uniqueness; they must build resilient processing. Integration assets become products, with version discipline and support expectations.
This organizational shift is often harder than the technology shift. It requires stronger product thinking around schemas, compatibility, and downstream impact.
Adapt governance and operating models
Architecture review processes may need to assess event taxonomy, schema evolution, and ownership boundaries alongside API design. Service management may need lag thresholds, replay approvals, and dead-letter remediation workflows. Funding models may need to recognize shared event infrastructure as platform investment rather than application expense.
In practice, this often leads to concrete architecture board decisions: approve Kafka as the strategic event backbone, require schema registry use for enterprise topics, and set retirement dates for unsupported messaging products under technology lifecycle governance.
Without these changes, enterprises often deploy event technology without the operating model needed to sustain it.
Common pitfalls
Several failure patterns appear repeatedly:
- Broker-first architecture: deploying messaging technology without event design, ownership, or governance
- Event overload: publishing every internal state change, creating noisy and low-value streams
- Hidden coupling: consumers depending on upstream internal models or timing assumptions
- Under-specified events: consumers forced into side calls or tribal knowledge
- Misapplied asynchrony: forcing event-driven interaction where synchronous confirmation is actually required
A sound adoption path includes a few mandatory disciplines: event review before publication, schema compatibility enforcement, consumer production-readiness checks, and service-level objectives for critical flows.
Define when not to use EDA
This is one of the most overlooked architectural decisions. If a use case requires immediate validation, simple request-response behavior, or strict transactional consistency, EDA may add complexity without enough return. Mature architecture is not about maximizing event usage. It is about choosing the right interaction style for each need.
Conclusion
Event-Driven Architecture gives cloud platforms a practical way to align system design with the realities of distributed enterprise change: independent teams, variable demand, partial failure, and expanding integration ecosystems. Its value lies not merely in asynchronous messaging, but in a platform model where business facts can be propagated, processed, observed, and governed without forcing every dependency into synchronous coordination.
Successful EDA depends on more than brokers and topics. It requires clear event semantics, disciplined schema and boundary design, fit-for-purpose patterns, strong operational controls, and governance built into the platform itself. When those elements come together, events become durable enterprise assets rather than transient technical messages.
EDA also works best as part of a broader interaction strategy. APIs remain essential for synchronous confirmation. Workflows continue to matter for explicit coordination. Streams are valuable where history, replay, and analytics are required. Architectural maturity comes from combining these modes deliberately.
For enterprises building cloud platforms, EDA is therefore less a messaging choice than a strategic capability. Done well, it enables faster change, stronger resilience, and a more adaptable digital ecosystem.
Frequently Asked Questions
How is ArchiMate used in cloud architecture?
ArchiMate models cloud architecture using the Technology layer — cloud platforms appear as Technology Services, virtual machines and containers as Technology Nodes, and networks as Communication Networks. The Application layer shows how workloads depend on cloud infrastructure, enabling migration impact analysis.
What is the difference between hybrid cloud and multi-cloud architecture?
Hybrid cloud combines private on-premises infrastructure with public cloud services, typically connected through dedicated networking. Multi-cloud uses services from multiple public cloud providers (AWS, Azure, GCP) to avoid vendor lock-in and optimise workload placement.
How do you model microservices in enterprise architecture?
Microservices are modeled in ArchiMate as Application Components in the Application layer, each exposing Application Services through interfaces. Dependencies between services are shown as Serving relationships, and deployment to containers or cloud platforms is modeled through Assignment to Technology Nodes.