⏱ 24 min read
Enterprise Cloud Architecture Patterns Explained | Scalable Design Guide hybrid cloud architecture
Explore enterprise cloud architecture patterns, including microservices, event-driven design, hybrid cloud, and resiliency strategies for scalable, secure systems. multi-cloud architecture strategy
enterprise cloud architecture, cloud architecture patterns, enterprise architecture, microservices architecture, event-driven architecture, hybrid cloud architecture, scalable cloud design, cloud resiliency, secure cloud architecture, distributed systems design Sparx EA guide
Introduction
Enterprise cloud architecture patterns turn recurring design problems into repeatable decisions. In large organizations, cloud adoption is rarely a single migration from a data center to a provider. It is a continuing shift in how applications are built, platforms are operated, security is enforced, and cost is managed. Patterns bring order to that shift. They give architects, platform teams, and delivery teams a shared way to handle familiar concerns such as environment design, integration, resilience, governance, and modernization.
At enterprise scale, cloud architecture extends well beyond infrastructure choices. It includes identity federation, network segmentation, telemetry, data protection, operating models, and the division of responsibility between central platform teams and application teams. Those choices tend to persist. A network model that is too centralized slows delivery. A security model that is too decentralized raises risk. A migration strategy that ignores business value can consume budget without improving outcomes.
Most enterprises are not designing on a blank sheet. They are working through a mix of legacy systems, packaged applications, cloud-native services, compliance obligations, and inherited integration approaches. For that reason, architecture patterns are not ideal templates. They are practical models that must be tested against operational maturity, migration complexity, vendor dependency, and team capability. A pattern may look sound on a diagram and still be the wrong fit for the organization that has to run it.
A useful way to frame enterprise cloud architecture is by layer. Foundational patterns establish the baseline environment: landing zones, identity, networking, observability, and cost controls. Application patterns shape how systems are built and connected: multi-tier design, APIs, microservices, and event-driven messaging. Cross-cutting patterns keep the estate safe and sustainable at scale: resilience, security, governance, and operational control. Strong architecture ties these layers together so workload decisions remain aligned with platform standards and business goals.
This article treats cloud architecture patterns as decision frameworks, not fixed blueprints. For each pattern, the key questions are straightforward: when does it fit, what trade-offs does it introduce, and what capabilities must already exist for it to work well? The sections that follow build on a few core ideas: standardized landing zones, federated identity, shared observability, governed autonomy, and tiered operational controls. Used well, these patterns help enterprises create cloud environments that remain scalable, secure, resilient, and manageable over time.
Foundations of Enterprise Cloud Architecture
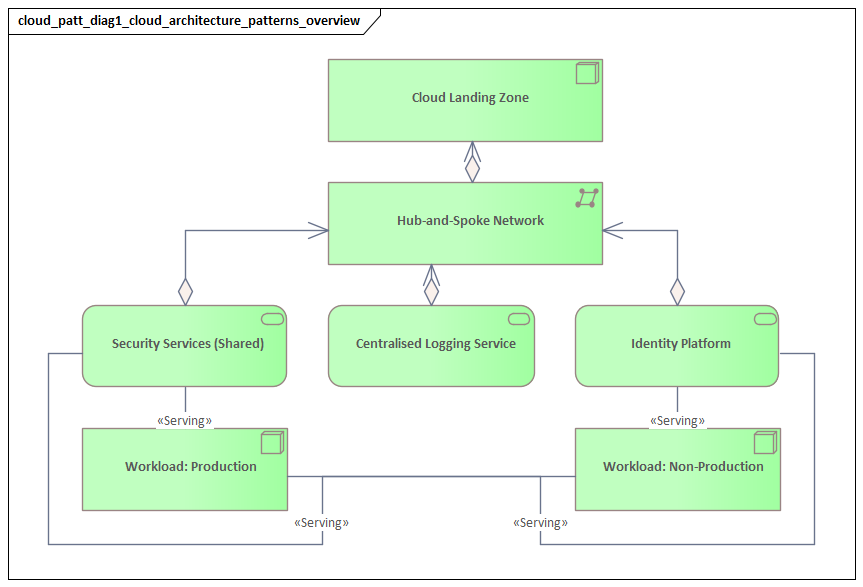
Enterprise cloud architecture begins with standardization. Before teams can move quickly, the organization needs a repeatable baseline for how environments are created, secured, connected, and operated. In most enterprises, that baseline is a landing zone: a preconfigured cloud environment that defines account or subscription structure, identity integration, network topology, logging, encryption defaults, and policy controls. A landing zone is more than an infrastructure template. It is the mechanism that turns enterprise standards into something deployable and enforceable.
That foundation also requires a clear operating model. In most cases, a central cloud platform or engineering team provides shared services and guardrails, while product or application teams remain responsible for workload design and day-to-day delivery. The balance matters. If control is too centralized, teams wait on approvals or work around standards. If it is too decentralized, security and operations fragment. The objective is governed autonomy: central teams define the paved road, and application teams move quickly within it. For example, a platform team may provide a standard ingress pattern based on managed gateways and web application firewall policies, while requiring formal review before any internal API is exposed directly to the internet.
Identity should be treated as the control plane of the cloud estate. Enterprise environments are usually strongest when they rely on federated identity, role-based access, and short-lived credentials rather than shared, long-lived accounts. The security benefit is obvious, but the operational benefit is just as important. When access is automated through enterprise identity systems, onboarding is faster, permissions are more consistent, and auditability improves. A common modernization step is replacing local application accounts and standing administrator access with single sign-on, conditional access, privileged access workflows, and workload identities for automation. TOGAF certified training
Network design is another decision with a long shelf life. Many enterprises carry on-premises assumptions into the cloud and end up with overly complex routing, broad address dependencies, and centralized choke points. A better approach is to decide where centralized connectivity is actually needed and where local autonomy is acceptable. Shared transit, private connectivity to data centers, segmented environments, and controlled ingress and egress should all fit within one coherent model. This becomes even more important in the hybrid and multi-cloud scenarios discussed later.
Observability and cost visibility belong in the foundation, not on a future roadmap. Logging, metrics, tracing, asset inventory, configuration monitoring, and alerting should be built into the platform from the start. Otherwise, the estate grows faster than the organization’s ability to understand it. The same applies to financial management. Tagging standards, ownership metadata, and account structures are much easier to define early than to retrofit after sprawl has set in. TOGAF roadmap template
In practical terms, foundational architecture reduces future decision load. Teams should not have to redesign encryption, backups, provisioning logic, or deployment controls for every new workload. Those concerns should be encoded in reusable modules, platform services, and automated policies. The strongest foundation is not the most elaborate. It is the one that makes the preferred path the easiest path to follow.
Pattern 1: Rehost, Replatform, and Refactor Strategies
One of the earliest cloud decisions is how much to change an application during migration. Rehost, replatform, and refactor are often presented as simple options, but in practice they represent very different levels of architectural change, investment, and operational impact. The right choice depends less on technical fashion than on business value, delivery risk, and platform maturity.
Rehost
Rehosting moves an application to the cloud with minimal architectural change, usually by replicating existing virtual machine or infrastructure configurations. It is useful when speed matters more than optimization. In many cases, it reduces dependence on physical data centers and creates a starting point for later modernization.
Its limitations are equally clear. Rehosting preserves many inherited problems: scaling limits, patching effort, brittle dependencies, and inefficient resource usage often remain in place. In some cases, costs even rise because workloads are moved into always-on cloud environments without being redesigned. For that reason, rehosting is usually best treated as a transitional pattern rather than a modernization strategy in its own right.
Rehosting fits best when:
- the system is stable and low in strategic value
- the workload is nearing retirement
- the organization needs to exit a facility quickly
- there is not enough time or capacity for deeper redesign
A realistic example is a legacy document archive used only for compliance retrieval. If the business plans to retire it in two years, a lift-and-shift move to cloud virtual machines may be entirely reasonable. Refactoring it into cloud-native services would add cost and risk with little return.
Replatform
Replatforming changes selected components while leaving the core application largely intact. Typical examples include moving from a self-managed database to a managed service, deploying on containers instead of manually administered virtual machines, or replacing scheduled file transfers with cloud messaging.
For many enterprises, this offers the best balance between benefit and disruption. It reduces undifferentiated operational work and aligns workloads with shared platform standards such as managed backups, built-in observability, and policy-based security controls. Even so, it still demands care. Managed services introduce new limits, new failure modes, and different backup, upgrade, or access patterns. Standardization only creates value when teams understand the operational consequences.
A common enterprise case is a customer portal that remains functionally unchanged but moves from self-managed middleware and database clusters onto managed database services and container orchestration. The application team avoids a major rewrite, yet support effort drops and operational consistency improves.
Refactor
Refactoring changes the application architecture itself so it can take better advantage of cloud capabilities. That may involve service decomposition, API boundaries, event-driven integration, redesigned state management, or other cloud-native approaches. Refactoring can unlock significant gains in agility and scalability, but it also brings the highest delivery risk and depends heavily on engineering maturity.
Enterprises should reserve refactoring for systems where the expected business return justifies the effort. Not every application benefits from distributed design. If the organization lacks strong testing practices, platform engineering, and observability, refactoring can introduce more complexity than value.
A useful example is an order management platform that must support new digital channels, near-real-time inventory visibility, and frequent pricing changes. In that case, decomposing tightly coupled functions into well-defined services may support faster delivery and more flexible scaling. By contrast, a stable back-office ledger may gain very little from the same treatment.
A Portfolio Decision, Not a Doctrine
These strategies are not mutually exclusive. A workload might be rehosted to meet a near-term exit deadline, replatformed later to reduce support burden, and refactored only when it becomes strategically important. The most effective enterprise approach is portfolio-based: assess each application by business criticality, rate of change, technical debt, integration complexity, compliance sensitivity, and expected lifespan.
An architecture review might, for instance, approve rehosting for a payroll archive system, replatform a customer portal onto managed databases and containers, and reserve refactoring for an order platform that must support new digital channels. That kind of differentiated decision-making usually produces better outcomes than a single modernization doctrine applied across the estate.
This pattern also connects directly to later sections. Refactoring often leads toward API-first, microservices, or event-driven models. Replatforming frequently depends on the resilience and governance patterns discussed later. All three strategies work better when the foundation already provides identity, observability, and deployment guardrails.
Pattern 2: Multi-Tier and API-First Application Architecture
Multi-tier architecture remains one of the most durable enterprise patterns because it separates presentation, business logic, and data responsibilities. That separation still matters in cloud environments. It creates clear trust boundaries, supports independent scaling decisions, and improves accountability across teams.
In practice, multi-tier architecture should not be reduced to a rigid three-server model. The presentation tier may include web front ends, mobile back ends, content delivery services, and identity-aware gateways. The logic tier may run on containers, managed platforms, or serverless functions. The data tier may include transactional databases, caches, object storage, and analytical platforms. What matters is not the exact technology stack but disciplined separation of concerns.
That separation creates practical benefits:
- internet-facing components can be isolated from internal processing services
- stateless logic layers can scale independently from stateful data services
- teams can change user-facing components without directly altering systems of record
- resilience can be designed differently for each tier based on business importance
API-first architecture extends this model by making interfaces a primary design concern. Rather than embedding business logic separately across channels and integrations, organizations define reusable APIs that expose stable business capabilities. This becomes especially valuable when multiple applications, teams, or partners need consistent access to the same functions.
The value of API-first design is not just reuse. It is control. APIs create explicit boundaries for authentication, authorization, throttling, monitoring, and versioning. They allow internal implementation to change while preserving a stable contract for consumers. In complex enterprise environments, that stability is often more important than the interface technology itself.
Consider a retail enterprise modernizing its customer domain. Mobile apps, e-commerce channels, in-store kiosks, and partner loyalty systems may all need customer profile and entitlement data. An API-first approach lets the organization expose those capabilities through governed interfaces rather than through direct database access or duplicated integration logic. The internal implementation can evolve, but consumer contracts remain stable.
API-first does not mean exposing everything. Without governance, enterprises accumulate redundant endpoints, unclear ownership, inconsistent naming, and unmanaged version sprawl. To avoid that, they need standards for:
- contract design
- security classification
- documentation quality
- lifecycle management
- backward compatibility
- retirement procedures
This section builds directly on the foundation established earlier. APIs rely on federated identity for access control, centralized observability for monitoring, and landing zone guardrails for secure deployment. They also set up later patterns. Microservices usually need API discipline to avoid service sprawl. Hybrid and multi-cloud models often use APIs to reduce direct dependency on underlying platforms. Governance programs rely on API boundaries to apply policy consistently.
A practical enterprise approach is to use multi-tier design internally and API-first design externally. The application keeps a clean internal structure, while consumers interact through intentional interfaces rather than shared databases or ad hoc integrations. This approach is particularly useful in modernization programs, where APIs create a controlled boundary around older systems and allow gradual transformation behind that boundary.
Not every system needs a broad API product model. But when capabilities must serve multiple channels, business units, or ecosystem partners, API-first architecture provides durable structure. It standardizes access, reduces duplication, and supports controlled evolution across a complex application landscape.
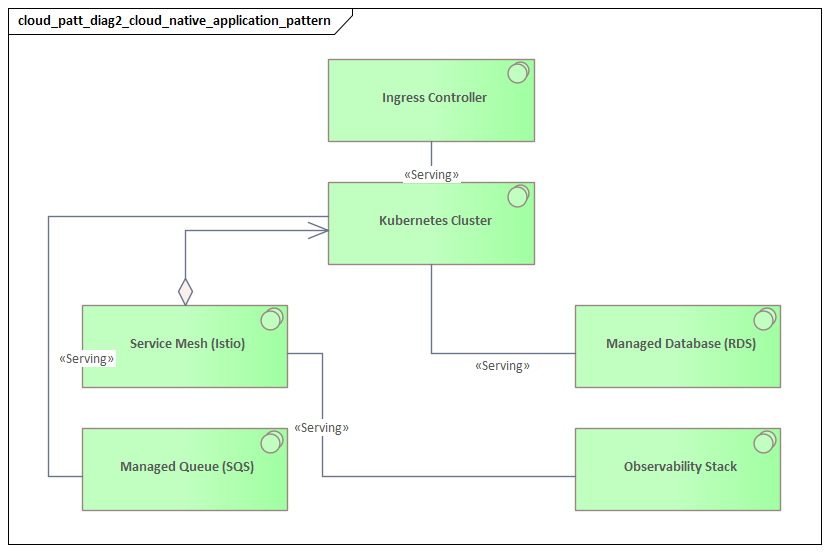
Pattern 3: Microservices and Event-Driven Architecture
Microservices and event-driven architecture are often presented as the natural destination of cloud modernization. In practice, they are specialized patterns for managing complexity in large, fast-changing systems. They are most useful when the enterprise needs independent team ownership, frequent change, and flexible integration across business domains. The real question is not whether these patterns are modern. It is whether they solve the problem the organization actually has.
Microservices
Microservices break an application into smaller services aligned to business capabilities. Each service owns its own logic and interface, and often its own data boundary. The main benefit is organizational as much as technical: teams can release independently, scale selectively, and reduce the coordination burden that comes with large shared codebases.
Microservices do not remove complexity; they redistribute it. In-process calls become network calls. Transactions become distributed. Security becomes more granular. Troubleshooting requires tracing across services rather than inspecting a single stack. Without strong shared capabilities for identity, observability, deployment, and policy enforcement, microservices can create fragmentation instead of agility.
That is why the foundational concepts introduced earlier matter so much. Federated identity supports service-to-service authentication. Landing zones standardize runtime and logging controls. Governed autonomy allows teams to own services without drifting away from enterprise standards.
A bank, for example, may separate customer onboarding, document verification, risk scoring, and account provisioning into distinct services because those capabilities change at different rates and are owned by different teams. That split can improve delivery speed, but only if the bank also provides shared tracing, secrets management, release pipelines, and operational standards.
Event-Driven Architecture
Event-driven architecture addresses how systems exchange information without being tightly coupled in time or implementation. Rather than relying mainly on synchronous requests, systems publish events when meaningful business actions occur. Other systems subscribe and react independently.
This pattern is especially useful in integration-heavy enterprises. It reduces point-to-point sprawl, supports asynchronous processing, and allows new consumers to be added without changing the original producer. It can also improve resilience by buffering spikes and decoupling failures, which connects directly to the resilience patterns discussed later.
A realistic example is an order platform publishing OrderCreated events to Kafka so billing, fulfillment, fraud detection, and analytics services can consume them independently rather than through custom point-to-point integrations. The producer emits a business fact once; downstream systems react according to their own timelines and responsibilities.
The challenge is discipline. Event-driven environments require careful handling of:
- event schema governance
- idempotency
- retries and replay
- ordering assumptions
- dead-letter handling
- message visibility and tracing
Without that discipline, loosely coupled systems can become difficult to understand and even harder to trust.
Use Them Selectively
Microservices and event-driven integration often work well together, but they should not be applied everywhere. Some domains need immediate validation, strong consistency, or simpler transactional behavior. In those cases, a modular monolith or multi-tier application with clear APIs may be the better fit.
A practical enterprise approach starts with domain boundaries, not technology choices. Services should map to business capabilities and ownership models. Events should represent business facts that other systems genuinely need, not internal implementation details.
The best adoption pattern is incremental. Start where there is high change frequency, clear ownership, and obvious integration friction. Prove that the organization can operate distributed systems well before replicating the model more broadly. In many enterprises, the strongest outcome is mixed: some capabilities remain in larger application units, while others are separated into services and connected through events where decoupling offers a clear advantage.
Pattern 4: Hybrid and Multi-Cloud Architecture Models
Hybrid and multi-cloud architecture reflect a common enterprise reality: not all workloads will run in a single cloud environment. Some systems remain on-premises because of latency, regulatory constraints, equipment dependencies, or migration cost. Others are spread across multiple cloud providers because of regional reach, specialized services, merger outcomes, or concentration-risk concerns.
Hybrid Cloud
Hybrid architecture combines cloud platforms and on-premises infrastructure in a coordinated operating model. The key challenge is not connectivity alone. It is consistency of control across environments. Identity, policy enforcement, logging, encryption, and incident response need to work across both sides.
When hybrid architecture is treated as little more than a network extension, the result is usually fragmentation. Systems can communicate, but governance and operations become inconsistent. This is where the foundational patterns matter again. Federated identity, centralized observability, and codified policy guardrails provide the shared control plane that makes hybrid architecture manageable.
A typical example is a manufacturing enterprise that keeps plant-floor systems on-premises because of latency and equipment integration requirements, while moving analytics, reporting, and supplier collaboration workloads to the cloud. The architecture succeeds only if access control, telemetry, and operational processes remain coherent across both environments.
Multi-Cloud
Multi-cloud introduces a different set of concerns. It may improve resilience or strategic leverage, but it also increases variation. Networking models differ. Identity and access models differ. Managed services behave differently. Tooling becomes more complex. Enterprises often pursue multi-cloud for portability, only to discover that full portability is expensive and rarely necessary.
A more useful distinction is between:
- multi-cloud by design: intentional workload placement with clear governance
- multi-cloud by accumulation: the unplanned result of decentralized decisions or inherited estates
The first can be architected. The second usually creates duplication, inconsistent controls, and avoidable cost.
Practical Enterprise Patterns
One useful pattern in both hybrid and multi-cloud environments is separating control plane from data plane. Workloads may run in different places, while governance capabilities such as identity federation, secrets management, security monitoring, asset inventory, and policy reporting remain standardized. That does not eliminate platform differences, but it reduces fragmentation where risk and operational consistency matter most.
Another strong pattern is workload placement by criteria rather than preference. Applications should be assigned to cloud, on-premises, or a specific provider based on measurable factors such as:
- latency sensitivity
- compliance requirements
- dependency locality
- resilience targets
- service fit
- cost and operational supportability
This section also connects directly to earlier and later patterns. APIs can reduce direct coupling across environments. Event-driven integration can decouple timing between hybrid components. Resilience design must account for cross-environment dependencies. Governance must distinguish between what should be standardized everywhere and what can remain provider-specific.
The strongest enterprise principle is not “run everything everywhere.” It is “run each workload in the most appropriate place under a consistent operating model.” That keeps hybrid and multi-cloud architecture grounded in business and operational reality.
Pattern 5: Resilience, Scalability, and High Availability
Resilience, scalability, and high availability are related, but they are not interchangeable. High availability is about reducing downtime. Scalability addresses growth in demand or data volume. Resilience is broader: the ability to continue operating, or to recover acceptably, when components fail or conditions change unexpectedly. In enterprise cloud architecture, these qualities need to be designed deliberately rather than assumed from provider infrastructure.
A common mistake is to treat cloud as automatically resilient. Providers offer redundant building blocks, but workloads still fail because of poor dependency design, untested failover, shared bottlenecks, or weak operational visibility. That is why the observability foundation described earlier matters so much: resilience depends not only on architecture, but also on the ability to detect degradation and respond quickly.
Failure Isolation
One of the strongest resilience patterns is failure isolation. Architects should define boundaries that contain faults rather than allowing them to cascade. That can include:
- separating workloads across zones or accounts
- isolating noisy neighbors from shared resources
- segmenting message flows
- using timeouts, retries with backoff, circuit breakers, and graceful degradation
The goal is not to eliminate all failure. It is to keep failure local and manageable.
A practical example is a claims processing platform where document ingestion, policy lookup, payment authorization, and notification services are isolated so that a backlog in one area does not halt the entire claims lifecycle. Customers may experience delay in one function, but the broader service remains available.
Scalability
Scalability requires more than enabling autoscaling. Enterprises need to distinguish between stateless and stateful components, burst demand and predictable growth, and front-end traffic scaling versus back-end processing scaling. Stateless services usually scale more easily. Databases, caches, and transactional systems often become the real constraint.
For that reason, scalable architecture often depends on patterns such as partitioning, read replicas, caching, asynchronous processing, and queue-based buffering. These patterns reinforce a lesson from the event-driven section: decoupling can improve not just integration flexibility, but demand absorption as well.
High Availability
High availability should match business need, not be applied uniformly. Some services justify active-active deployment across zones or regions. Others are adequately protected by active-passive recovery. The right choice depends on recovery time objective, recovery point objective, transaction criticality, and the operational complexity the organization can realistically support.
A design is not truly highly available if failover exists only in architecture diagrams. It has to be tested and rehearsed. This is where governance and operational control, covered in the next section, become essential.
Data Resilience
Data is often the deciding factor. Compute can usually be recreated. Data loss or corruption carries deeper business impact. Enterprise patterns here include immutable backups, replication, point-in-time recovery, and explicit data classification. Just as important is knowing which systems are systems of record and which can be rebuilt from source events or upstream data.
The strongest enterprise approach is tiered resilience. Availability, scaling, and recovery mechanisms should be aligned to business importance, technical constraints, and demonstrated operational readiness. Overprotecting low-value workloads wastes budget. Underprotecting critical services creates risk.
Pattern 6: Security, Governance, and Operational Control
Security, governance, and operational control determine whether cloud adoption remains sustainable at scale. In small environments, manual reviews and one-off checks may appear sufficient. In enterprise environments, they do not scale. The stronger pattern is policy-driven control embedded in the platform, the delivery lifecycle, and day-to-day operations.
A useful way to frame this is as a shift from manual oversight to continuous control enforcement. Because cloud resources are created and changed dynamically, governance has to operate through codified policies, preventive guardrails, and detective controls. Examples include:
- mandatory encryption
- restrictions on public exposure
- approved regions and service classes
- baseline logging requirements
- automated drift detection
- ownership and tagging enforcement
The goal is to make unsafe states difficult to create and easy to detect.
This pattern builds directly on the foundation introduced earlier. Landing zones provide the enforcement point. Federated identity governs access. Centralized observability supports audit and incident response. Cost and asset metadata support accountability. Governance is not a separate layer added later; it is the operational expression of the foundational architecture.
Security architecture also changes in the cloud. Instead of acting only as an approval gate, security should be integrated into platform engineering and delivery pipelines. Controls become reusable building blocks: hardened images, approved identity patterns, secrets handling, monitored deployment modules, and policy-tested infrastructure code. That reduces friction for teams while improving consistency.
Governance extends beyond security. It also includes lifecycle management, resource ownership, data handling, change traceability, and financial accountability. A cloud estate becomes difficult to manage when assets have unclear owners or inconsistent classification. Mature governance therefore depends on metadata standards, automated inventory, and clear alignment between technical structures and business responsibility.
For example, a technology lifecycle policy may classify Kubernetes versions, database engines, and messaging platforms as adopt, tolerate, or retire, with deadlines for remediation and board review of exceptions. That kind of policy gives engineering teams room to plan while keeping risk visible and time-bounded.
Operational control matters just as much. Enterprises need clear patterns for introducing change, escalating incidents, and handling exceptions. Standard changes should run through tested pipelines, not manual console activity. Privileged access should be time-bound and auditable. Exceptions should be documented, reviewed, and eventually retired rather than becoming permanent hidden deviations.
The strongest enterprise pattern is governed autonomy. Teams should be able to deploy and operate quickly within clearly defined boundaries, using preapproved building blocks and automated controls. Architects should focus standardization on the areas where enterprise risk is highest—identity, logging, key management, network exposure, and compliance evidence—while allowing selective variation elsewhere.
Governance quality should be measured by outcomes, not by the number of policies written. The pattern succeeds when teams can move quickly while the organization maintains visibility, accountability, and risk discipline.
Conclusion
Enterprise cloud architecture patterns are most useful when treated as decision tools rather than fixed blueprints. No single pattern fits every enterprise. The right architecture depends on business priorities, regulatory obligations, operational maturity, and the realities of the existing technology estate.
The strongest enterprises connect patterns instead of applying them in isolation. Migration strategy depends on the platform foundation. API-first design supports controlled modernization. Microservices and event-driven models require strong identity, observability, and governance. Hybrid and multi-cloud environments work best under a consistent control model. Resilience depends as much on operational readiness as on infrastructure design. Security and governance succeed when they are built into the architecture itself.
A practical architecture perspective is to evaluate patterns as part of an operating model. A microservices strategy without platform engineering, a multi-cloud strategy without placement discipline, or a resilience strategy without testing will create complexity faster than value. The objective is alignment: structure, process, and accountability working in the same direction.
Enterprise cloud architecture is never finished. Patterns that make sense during initial migration may later become constraints. Others become viable only as the organization gains maturity. For that reason, reference architectures, landing zones, and standards should evolve based on operational evidence, cost data, incidents, and changing business demand.
In the end, strong enterprise cloud architecture is less about technical novelty than about creating an environment where teams can build, run, and improve systems safely at scale. The best patterns are the ones that reduce unnecessary complexity, support accountable autonomy, and help the enterprise change with confidence.
Frequently Asked Questions
How is ArchiMate used in cloud architecture?
ArchiMate models cloud architecture using the Technology layer — cloud platforms appear as Technology Services, virtual machines and containers as Technology Nodes, and networks as Communication Networks. The Application layer shows how workloads depend on cloud infrastructure, enabling migration impact analysis.
What is the difference between hybrid cloud and multi-cloud architecture?
Hybrid cloud combines private on-premises infrastructure with public cloud services, typically connected through dedicated networking. Multi-cloud uses services from multiple public cloud providers (AWS, Azure, GCP) to avoid vendor lock-in and optimise workload placement.
How do you model microservices in enterprise architecture?
Microservices are modeled in ArchiMate as Application Components in the Application layer, each exposing Application Services through interfaces. Dependencies between services are shown as Serving relationships, and deployment to containers or cloud platforms is modeled through Assignment to Technology Nodes.