⏱ 24 min read
Architecture Modeling for Event-Driven Platforms: Principles, Patterns, and Best Practices Sparx EA best practices
Learn how architecture modeling supports event-driven platforms with proven patterns, scalable design principles, and best practices for integration, governance, and resilience.
architecture modeling, event-driven platforms, event-driven architecture, EDA, platform architecture, architectural patterns, system integration, scalable systems, asynchronous messaging, event streaming, microservices architecture, enterprise architecture, solution design, architecture governance, distributed systems Sparx EA guide
Introduction
Event-driven platforms have become a defining pattern in modern enterprise architecture because they reflect how the business actually changes: orders are placed, payments settle, devices emit telemetry, shipments slip, customers change preferences, and compliance rules trigger action. In that environment, architecture modeling is not just an inventory of brokers, topics, queues, and consumers. It is a way to show how the enterprise detects change, shares meaning, coordinates response, and governs outcomes across systems and teams.
That creates a different modeling challenge from traditional request-response architecture. In synchronous systems, dependencies are usually visible in interfaces and call chains. In event-driven systems, they are often indirect, delayed, and distributed across producers and consumers that never interact directly. This hidden coupling is one of the main reasons modeling matters. A useful architecture model must show not only what is connected, but also what has been intentionally decoupled, what relies on eventual consistency, and where business or operational risk appears if events are delayed, duplicated, reordered, or misinterpreted.
To do that well, architects need a set of connected views. At the business level, the model should identify the events that matter, the capabilities they influence, and the outcomes expected when they occur. At the application and data levels, it should clarify event ownership, contract boundaries, processing responsibilities, and state management. At the technology and operations levels, it should show runtime services, resilience patterns, observability controls, security enforcement points, and deployment topology. Without those linked views, organizations often end up with event platforms that function technically but are difficult to govern, expensive to evolve, and only loosely connected to business priorities.
A practical architecture approach treats modeling as a decision tool rather than a static document. The model should help answer concrete questions: which domain owns a business event, which consumers are critical, where replay is required, what latency and retention commitments apply, and how security or compliance controls are enforced. For example, an architecture board may decide that PaymentSettled is an enterprise event owned only by the payments domain, with schema changes subject to review because finance, fraud, and customer communications all depend on it. That decision shapes platform design, team responsibilities, and investment choices.
At its best, modeling makes the invisible visible. It exposes hidden dependency in asynchronous systems, reveals weak ownership of meaning, and gives domain teams, platform engineers, architects, operations, and risk stakeholders a shared language. The sections that follow build that view step by step: foundations first, then core modeling views, followed by design, governance, runtime, and evolution concerns involved in scaling an event-driven platform as an enterprise capability.
1. Foundations of Event-Driven Platform Architecture
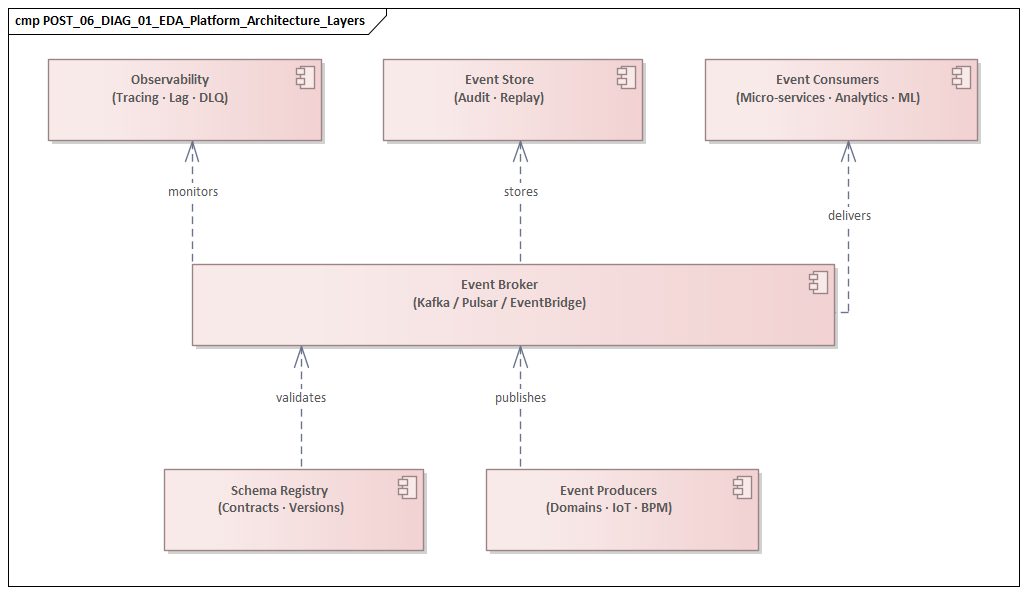
The foundation of an event-driven platform is not the messaging product. It is the architectural contract that defines how events are created, interpreted, transported, and governed. A platform becomes strategically useful when it gives domains consistent rules for interaction while preserving local autonomy. For that reason, architects should model the platform as a combination of domain semantics, interaction patterns, state boundaries, operational expectations, and organizational responsibilities.
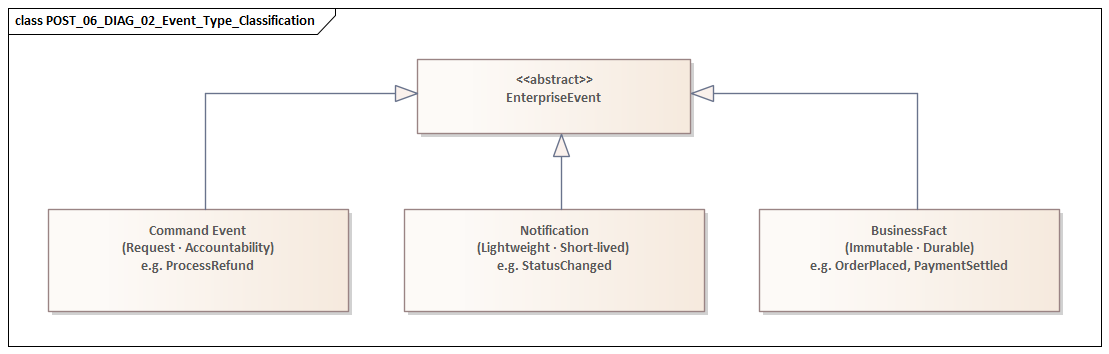
A good starting point is to distinguish the main interaction types. Some events are immutable business facts such as OrderPlaced or PaymentSettled. Others are notifications that something changed. Others behave more like commands that request action. The distinction matters because it affects ownership, replay value, delivery expectations, and failure handling. Facts are usually durable and reusable. Notifications may be lightweight and short-lived. Commands typically require tighter accountability and clearer processing guarantees. The architecture model should make these categories explicit because later design choices depend on them.
Domain ownership is the next foundation. Events are most valuable when they come from bounded contexts with clear authority. If several teams publish overlapping versions of the same business occurrence, the platform quickly becomes noisy and hard to trust. Architects should therefore model which domain is authoritative for asserting that a customer exists, a payment is settled, or inventory is reserved. In practice, many platform failures have less to do with transport than with weak ownership of meaning.
A common example appears in retail order management. The ecommerce platform may emit OrderSubmitted, the OMS may publish OrderAccepted, and the warehouse system may later send OrderReleased. All three are legitimate events, but only one domain should be authoritative for the commercial fact that the order exists. Without that distinction, downstream teams often build duplicate logic and inconsistent reporting.
Channel design is another core concern. Not every event should be visible everywhere, and not every consumer should connect directly to every producer. The model should show where domain-local streams are sufficient, where enterprise-wide distribution is justified, and where mediation through gateways, stream processors, or integration hubs is needed. A Kafka-based event backbone might expose operational events broadly, while customer identity events are routed through a governed integration layer with masking and approval controls. That limits blast radius, protects sensitive data, and keeps lineage understandable.
State also needs to be modeled explicitly. Event-driven platforms distribute change, but business outcomes still depend on coherent state. Architects need to show where authoritative state lives, where derived state is materialized, and how downstream discrepancies are repaired. Some services reconstruct state from event history; others maintain cached or materialized views; some use event sourcing, many do not. What matters is that state assumptions are visible so teams do not mistake asynchronous distribution for guaranteed consistency.
A simple banking example illustrates the point. A CardBlocked event may be consumed by fraud, mobile banking, and customer notification services. The fraud service may treat the event as a durable fact, while the mobile app cache updates a read model that can lag briefly. If the architecture model does not show that distinction, support teams may assume all channels reflect the same state at the same time when they do not.
Non-functional expectations belong in the foundation as well. Throughput, ordering, replay, idempotency, retention, auditability, and recovery objectives shape the architecture as much as functional flows do. A payment stream and a marketing stream may share infrastructure, but they should not automatically share the same resilience model or operating expectations. how architecture review boards use Sparx EA
These foundational concepts—interaction type, ownership, channel design, state, and non-functional intent—anchor the rest of the architecture. The modeling views in the next section should build on them rather than reintroduce them inconsistently.
2. Core Modeling Views and Architectural Abstractions
The foundations define what must be made explicit. The next step is to represent those concerns through a small set of complementary views. No single diagram can usefully show business meaning, producer-consumer dependency, state handling, deployment topology, and governance all at once. In practice, a workable architecture model uses several abstractions together.
2.1 Event Landscape View
The event landscape view shows the major event types, their originating domains, and the business areas they influence. It should reflect ownership principles rather than collapse into a broker inventory. Its purpose is to reveal which business moments are architecturally important, where authoritative event sources exist, and where semantic overlap appears across domains.
This view is especially useful for spotting duplication, such as several teams emitting slightly different customer or order events. It also helps distinguish local events from enterprise event assets that deserve stronger stewardship.
2.2 Producer-Consumer Dependency View
Asynchronous systems hide coupling. The dependency view makes that coupling visible by showing which consumers rely on which events, with what criticality and service expectations. It should include not only direct consumers but also downstream processors, derived consumers, schema registries, dead-letter services, and other runtime dependencies. ArchiMate modeling best practices
In many environments, this view reveals that a supposedly decoupled platform still concentrates business risk around a small number of shared streams. It should distinguish optional consumers from mandatory business-processing consumers, because the impact of failure is very different.
A realistic example comes from insurance claims. A ClaimRegistered event may feed customer communications, fraud screening, document assembly, and case assignment. Those consumers are not equally critical. If customer email processing lags for fifteen minutes, the business may tolerate it. If fraud screening lags by the same amount, claims may move forward without required controls. The dependency view should make that difference obvious.
2.3 Event Contract View
Building on the distinction between facts, notifications, and commands, the contract view defines payload boundaries, metadata standards, versioning rules, compatibility expectations, identity fields, correlation keys, and sensitive-data classification. More importantly, it captures semantic meaning: whether an event is complete or partial, whether values represent a historical fact or a current-state projection, and what repeated delivery means.
This is one of the strongest safeguards against semantic drift. Reliable transport does little good if different teams interpret the same event in different ways.
2.4 Processing and State View
The processing and state view shows how events produce outcomes. It covers filtering, enrichment, aggregation, choreography, orchestration, materialized views, compensation, and correlation. It also identifies where state is transient, where it is persisted, and where time-based logic applies.
This view is often where hidden complexity becomes obvious. A flow that looks elegant as a stream of events may depend on fragile joins, expensive replay, or cross-domain state reconstruction that is difficult to recover.
2.5 Deployment and Runtime View
The deployment and runtime view maps the logical design onto actual platform components: brokers, clusters, regions, gateways, execution environments, partitioning schemes, resilience mechanisms, and observability instrumentation. It should also show trust boundaries and control points for encryption, access management, and audit capture.
This is the view where abstract design is tested against non-functional expectations such as latency, sovereignty, recovery, and throughput.
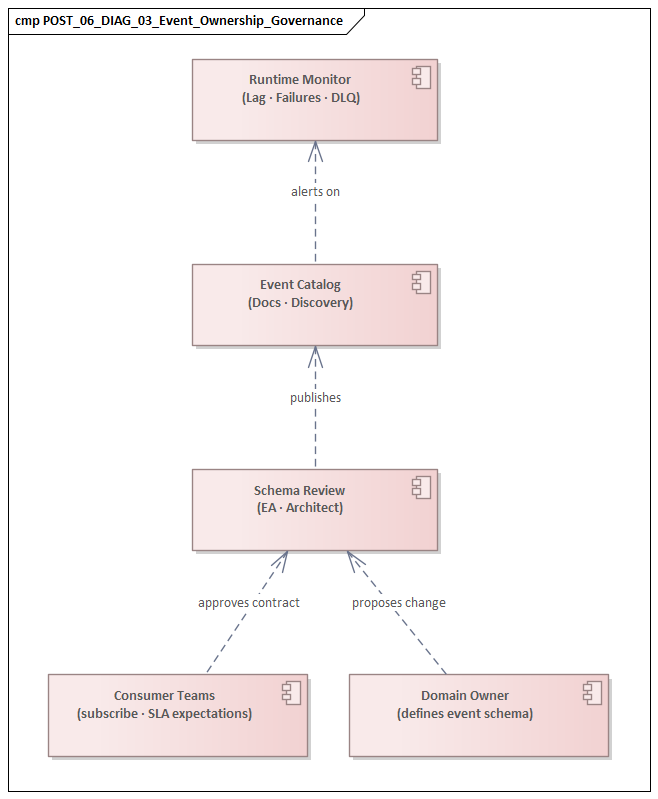
2.6 Governance and Accountability View
Finally, the model needs a governance and accountability view. Event-driven platforms often fail when ownership is unclear: who owns the event, who approves schema changes, who is responsible for service levels, and who resolves incidents when cross-team flows fail. This view turns architecture from a conceptual map into an operating model. A realistic example is an architecture board assigning the IAM team as owner of identity events, the platform team as owner of Kafka tenancy and policy enforcement, and the risk office as approver for any new consumer of privileged-access events.
Taken together, these views provide a practical way to model the foundations established earlier. They also create the frame of reference for the design choices discussed in the next sections.
3. Event Flow Design, Contracts, and Interaction Patterns
Once the core views are in place, architects can model event flow more precisely. This is where the platform moves from static structure to operational behavior.
A practical first step is to name the interaction pattern instead of treating all exchange as generic publish-subscribe. Some flows distribute business facts to many independent consumers. Some form sequential processing chains. Some support long-running business processes that require correlation over time. Others are analytical streams intended mainly for aggregation. These patterns may share infrastructure, but they should not be modeled as if they have identical latency, ordering, or reliability requirements.
Architects should also distinguish whether a flow is broadcast, routed, partitioned, or mediated. Broadcast supports reuse but can create uncontrolled downstream dependency. Routed flows improve control but depend on routing logic. Partitioned flows support scale and parallelism, but they also define the practical limit of ordering guarantees. Mediated flows can shield domains from unnecessary exposure, although too much mediation can create hidden integration bottlenecks. These choices should be explicit in the model because they shape both technical behavior and organizational coupling.
Contracts remain central here, but the emphasis shifts to behavioral meaning. A contract should tell consumers whether the event is complete or partial, whether fields may be absent, whether values are authoritative, and whether duplicate delivery is possible. The contract view introduced earlier should therefore be referenced directly during flow design. A schema alone is not enough if usage rules remain implicit.
Timing is another architectural property that must be modeled deliberately. Asynchronous exchange changes the form of dependency; it does not remove dependency. If a consumer must react within seconds to prevent financial or customer harm, the event flow still carries a near-real-time commitment. If another consumer can process within hours, the design can tolerate buffering and back-pressure. Those timing classes influence topic design, scaling, retries, and support expectations.
Failure semantics deserve the same level of clarity. For each important flow, architects should define what happens when processing fails, when consumers fall behind, when duplicates occur, or when downstream actions partially succeed. This is where patterns such as idempotent consumption, dead-letter routing, replay, compensating events, and saga coordination become architectural concerns rather than implementation details. In a Kafka-based order pipeline, for example, the board may require OrderPlaced consumers to be idempotent and support replay for seven days, while SendPromotionalEmail remains best-effort with no replay guarantee.
Another useful micro-example comes from airline operations. A FlightDelayed event may trigger gate reallocation, customer notification, crew scheduling checks, and onward connection analysis. Those consumers need different timing and failure rules. Gate operations may require sub-minute updates, while customer messaging can tolerate a short delay if duplicate notifications are suppressed. Modeling them as one generic fan-out flow hides the real architecture.
Event flow design also has to account for change over time. New consumers appear, event meanings evolve, and business processes shift. Robust platforms support additive change, compatibility validation, staged deprecation, and controlled versioning rather than disruptive redesign. This is where governance and accountability become essential: evolution remains sustainable only when ownership and approval responsibilities are clear.
In short, flow design works best when interaction type, contract semantics, timing, failure handling, and evolution are modeled together.
4. Governance, Observability, and Operational Control
The earlier sections established ownership, dependency, contracts, and runtime structure. Governance and observability are what make those design choices workable in production.
In an event-driven platform, governance has to go beyond standards and approval processes into measurable runtime control. Naming conventions, schema rules, and topic policies matter, but they are not enough if the enterprise cannot observe whether they are being followed or detect when deviations create business risk. Governance becomes effective when it is tied to platform telemetry.
For each critical flow identified in the dependency and flow views, architects should define the operational signals that indicate health and control. These typically include publication rate, consumer lag, processing latency, retry volume, dead-letter volume, schema validation failures, replay frequency, and unauthorized access attempts. These are not merely technical metrics; they are indicators of architectural fitness. Rising lag on a settlement stream may point to a scaling issue, but it may also reveal poor partition design, weak consumer implementation, or unclear operational ownership.
Observability should be modeled at three layers:
- Platform observability: brokers, clusters, storage, throughput, and availability.
- Flow observability: individual event paths, consumer groups, transformation stages, and failure points.
- Business outcome observability: operational consequences such as delayed fulfillment, duplicate notifications, or missed compliance actions.
This layered model matters because many incidents first appear as business anomalies rather than infrastructure alarms. Linking technical flow telemetry to business outcomes enables faster diagnosis and better prioritization.
Lineage is another first-class concern. Teams often know what they publish and consume, but not how events are transformed, enriched, or redistributed later. For regulated or business-critical flows, the model should capture source systems, transformation steps, downstream propagation paths, retention locations, and replay boundaries. Without lineage, incident response slows, auditability weakens, and hidden dependency accumulates.
Operational control also depends on visible policy enforcement. Not all channels should have the same openness or retention profile. Some streams permit broad internal subscription; others require explicit approval, masking, encryption, or geographic restriction. These controls should appear in the model as enforcement points, not just policy statements. Architects should show where access is authorized, where schemas are validated, where payload inspection occurs, and where retention or deletion rules are applied. In IAM modernization, for instance, identity lifecycle events such as UserProvisioned or PrivilegeGranted may be published to the platform, but subscription is restricted to approved security, audit, and HR services through centralized policy enforcement.
The same principle applies in healthcare. A LabResultAvailable event may be useful to scheduling, patient communications, and analytics, but only some consumers should receive the full payload. Others may receive a masked derivative event that preserves workflow value without exposing clinical detail. If the model does not show where masking occurs and who owns the derivative contract, governance remains theoretical.
Observability also has to connect to response responsibility. Who investigates lag? Who approves replay? Who can quarantine a faulty producer? Who communicates business impact? The governance and accountability view should answer these questions in operational terms, especially because corrective actions in event-driven systems often have wide downstream effects.
Governance, observability, and operational control together form the runtime discipline that makes asynchronous architecture trustworthy at enterprise scale.
5. Scalability, Resilience, and Performance Architecture
Scalability, resilience, and performance should be modeled as connected concerns. A platform may scale in raw throughput and still fail under operational stress because partitioning is poorly aligned, consumer recovery is weak, or low-latency traffic competes with bulk replay. The architecture model therefore needs to show not only how the platform grows, but how it behaves under pressure.
A practical starting point is load shape rather than load volume. Event-driven systems rarely experience uniform demand. They deal with bursts, seasonal peaks, fan-out amplification, replay surges, and skewed partitions. Architects should model expected traffic patterns by event class: steady telemetry, spiky customer interactions, batch-originated floods, and high-value transactional streams. This helps identify hot partitions and choose better keys, sharding strategies, and isolation boundaries.
Resilience modeling should also move beyond generic availability targets. Failures in event-driven systems often propagate indirectly. A broker outage is obvious, but a poisoned message, a blocked downstream dependency, or a state-store failure can be just as damaging. Architects should model failure modes by layer: transport, processing, dependency, state, and control plane. Each layer may require different response patterns such as retry with backoff, dead-letter diversion, checkpoint rollback, workload shedding, or circuit isolation.
Performance class separation is especially important. Low-latency operational streams, high-throughput analytical feeds, and long-retention audit streams often have conflicting behavior. The model should therefore identify which workloads can safely coexist and which need logical or physical isolation through dedicated clusters, topic classes, consumer pools, storage policies, or network paths. This directly reflects the non-functional distinctions introduced in the foundation section.
Capacity planning must also treat replay and recovery as first-class loads. Many platforms are sized for live traffic but not for reprocessing after defects, outages, or onboarding of new consumers. Replay often creates very different traffic patterns from normal operation, especially when historical streams are consumed at maximum speed by stateful processors. Architects should model replay windows, throttling controls, and recovery priorities explicitly.
Geographic distribution adds another layer of complexity. Cross-region or cross-cloud flows can improve continuity and locality, but they complicate ordering, duplication control, failover, and sovereignty. The model should show which streams remain local, which replicate asynchronously, and which use active-active or active-passive patterns.
A practical logistics example makes this concrete. Warehouse scan events may remain local to each region for low-latency operations, while ShipmentDispatched replicates globally for customer visibility and customs processing. If architects apply the same replication pattern to both, they may either over-engineer local operations or under-serve global tracking needs.
Most importantly, performance objectives should be defined per flow, not as platform-wide slogans. End-to-end latency, acceptable backlog, recovery time, and throughput headroom should be specified according to business criticality. Event-driven architecture is valuable not because it is uniformly fast, but because it allows trade-offs to be made explicit and managed deliberately.
6. Security, Compliance, and Risk Management
Security in an event-driven platform has to be modeled differently from security in a purely synchronous environment. Events are easy to copy, persist, replay, and redistribute, often long after their first publication. The architecture problem is therefore broader than protecting an API or a database. Architects must show who can publish, subscribe, discover, retain, transform, and act on event data.
A strong model begins by classifying flows according to data sensitivity, actionability, and propagation risk. Some events carry low-risk operational telemetry. Others expose personal, financial, health, or security-relevant information. Some are merely informative; others can trigger fulfillment, pricing, account action, or regulatory reporting. These differences should translate into security tiers with corresponding controls for encryption, masking, tokenization, retention, and subscription approval.
Trust also needs to be modeled explicitly. In event-driven systems, trust is often transitive: one service consumes an event, enriches it, and republishes a derivative event that others may treat as authoritative. Architects should therefore identify which producers are trusted to assert business facts, which intermediaries may transform or redact payloads, and which consumers may act autonomously versus those that require additional validation. This builds directly on the domain authority concepts introduced in the foundation section.
Compliance architecture is more complex because event platforms preserve and distribute history. Obligations such as data minimization, consent enforcement, retention limits, legal hold, auditability, and right-to-erasure can conflict with durability and replay. The model should identify where regulated data is stored, whether downstream materializations inherit the same obligations, and how deletion, redaction, or tombstoning is handled across replicas, caches, and analytical sinks. Compliance in event-driven systems depends on lineage-aware control, not just perimeter security.
Risk management must also account for event misuse and semantic fraud. An event may be structurally valid yet still be operationally dangerous: duplicated settlement events, forged status changes, replayed commands, or out-of-sequence updates can all cause business harm. For high-impact flows, the architecture should include controls such as schema enforcement, authenticity checks, anti-replay protection, sequence validation, and business rule verification at critical consumption points. In some cases, receipt of an event should be clearly separated from authorization to act.
The most effective models show security and compliance as embedded controls along the flow, not as external review gates. They identify where sensitive fields are removed before broad distribution, where confidential streams are isolated, where policy decisions are enforced automatically, and where evidence is captured for audit. They also clarify who can approve emergency access, suspend a compromised producer, assess downstream exposure after schema changes, or authorize replay across compliance boundaries.
In an event-driven platform, security and compliance are ultimately about the distribution of trust and liability. The more reusable the platform becomes, the more deliberately those controls must be modeled.
7. Aligning Architecture Modeling with Business Capability and Platform Evolution
Architecture modeling becomes most valuable when it is tied directly to business capability rather than treated only as a technical description. Enterprises invest in event-driven platforms to improve responsiveness, coordination, automation, insight, and adaptability. The model should therefore show how event-driven mechanisms strengthen capabilities such as order management, fraud detection, claims handling, pricing, customer engagement, or regulatory monitoring.
A practical approach is to map event flows to capability outcomes rather than only to applications. For example, a customer notification capability may depend on billing, fulfillment, consent, and preference events. A risk monitoring capability may combine transactional events, behavioral signals, and external alerts. This makes it easier to see where capability performance depends on event quality and timeliness, and where platform investment will produce measurable business value. fixing Sparx EA performance problems
This perspective becomes especially important as organizations move from isolated event use cases to a broader platform strategy. Early adoption often starts with local integration needs. Over time, some event streams become strategic assets used across multiple capabilities. The model should distinguish between solution-specific flows and platform-level event assets. The former may justify lighter governance; the latter require stronger contracts, longer-term stewardship, and clearer ownership.
Platform evolution should also reflect maturity differences across domains. Not every team is ready to publish high-quality business events with stable contracts. Some domains can act as authoritative producers; others still depend on integration events derived from legacy systems. A useful enterprise model makes this visible rather than assuming uniform readiness. It can show which domains are mature event producers, which need mediation or translation, and which are candidates for modernization.
This maturity view supports investment and sequencing decisions. Architects should be able to answer questions such as: which capabilities improve most if event latency is reduced; which domains should be prioritized for canonical event ownership; where contract stabilization creates the greatest reuse benefit; and which legacy integration patterns should be retired first. The same logic applies to technology lifecycle governance: an architecture board may decide to retire a legacy MQ integration layer over 24 months, standardize new event publishing on Kafka, and keep only a small set of sanctioned bridge patterns for systems that cannot yet be modernized.
Platform evolution is also organizational. As adoption grows, responsibilities often shift from central integration teams toward federated domain teams supported by shared platform services. The model should show where self-service publishing is appropriate, where central review remains necessary, and how capability ownership aligns with event ownership. Without that, the platform may scale technically while governance remains trapped in outdated operating structures.
When architecture modeling is aligned with business capability and platform evolution, it becomes a planning instrument for enterprise change rather than a static technical artifact.
Conclusion
Architecture modeling for event-driven platforms is the discipline of making distributed change understandable, governable, and sustainable. The challenge is not simply to represent asynchronous technology, but to expose the consequences of delayed events, shifting meaning, unclear ownership, hidden dependency, and uneven operational control.
A strong model starts with foundations: event type, domain authority, channel design, state boundaries, and non-functional intent. It then expresses those foundations through a set of linked views covering event landscape, dependency, contracts, processing and state, runtime deployment, and governance. From there, architects can reason more effectively about flow design, observability, scalability, resilience, security, and business alignment.
The value of this work compounds over time. Architecture models become a strategic asset for impact analysis, modernization planning, control assurance, and investment prioritization. When a new consumer is proposed, when a domain wants to publish a new business event, when IAM is modernized through identity lifecycle events, or when technology standards shift toward Kafka and away from aging middleware, the model should help teams assess consequences quickly rather than forcing them to rediscover the platform through incident and rework.
The most effective enterprise architects treat event-driven models as living decision frameworks. They connect design intent to runtime evidence, align federated teams around shared meaning and accountability, and help the organization evolve from isolated messaging use cases into a durable event-driven capability. That is what turns an event platform from technical plumbing into enterprise architecture.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business processes, information systems, and technology. It provides a structured approach to understanding the current state, defining the target state, and managing the transition — using frameworks like TOGAF and modeling languages like ArchiMate.
How does ArchiMate support enterprise transformation?
ArchiMate supports transformation by modeling baseline and target architectures across business, application, and technology layers. The Implementation and Migration layer enables architects to define transition plateaus, work packages, and migration events — creating a traceable roadmap from strategy through to implementation.
What tools are used for enterprise architecture modeling?
The most widely used tools are Sparx Enterprise Architect (ArchiMate, UML, BPMN, SysML), Archi (ArchiMate-only, free), and BiZZdesign Enterprise Studio. Sparx EA is the most feature-rich — supporting concurrent repositories, automated reporting, scripting, and integration with delivery tools like Jira and Azure DevOps.