⏱ 22 min read
Structuring Large Enterprise Architecture Models with ArchiMate | Best Practices ArchiMate training
Learn how to structure large enterprise architecture models with ArchiMate using scalable viewpoints, layering, decomposition, and governance best practices for clarity and maintainability. ArchiMate tutorial for enterprise architects
Structuring enterprise architecture models, ArchiMate, large ArchiMate models, enterprise architecture modeling, ArchiMate best practices, architecture viewpoints, model decomposition, architecture governance, scalable architecture models, EA repository management ArchiMate layers explained
Introduction
As enterprise architecture practices mature, ArchiMate repositories rarely remain small. What starts as a handful of focused diagrams often expands into a broad model spanning strategy, business, applications, data, technology, security, and change. At that point, the challenge is no longer how to draw the notation correctly. The harder problem is how to shape the repository so it stays understandable, governable, and useful as the enterprise and its change portfolio grow. ArchiMate relationship types
Large enterprises are not tidy systems. They consist of business units, regions, shared platforms, legacy estates, regulatory obligations, and multiple transformation efforts moving at different speeds. A repository that works at small scale often begins to fail when those realities are added without a clear organizing logic. Show every stakeholder the same level of detail and the model becomes too generic to support decisions. Let each domain team model independently and the repository fragments into inconsistent semantics, duplicate elements, and disconnected views. Structure is therefore not cosmetic. It is what makes enterprise modeling viable in practice.
A well-structured ArchiMate model should help answer practical questions quickly. Which applications support a capability? What business services depend on a platform scheduled for retirement? Where do ownership boundaries sit? Which initiatives are competing for the same data or integration assets? In large repositories, those answers depend less on the presence of individual elements than on how the model is partitioned, related, named, and governed. The repository becomes genuinely useful when architects can move through it logically rather than reconstructing meaning diagram by diagram. ArchiMate modeling best practices
Structure matters for another reason: enterprise architecture is collaborative. Business architects, domain architects, solution architects, platform teams, and governance bodies all contribute different knowledge at different times. Without clear rules for abstraction, reuse, naming, and ownership, confidence in the repository declines. Content becomes uneven, semantics drift, and stakeholders stop using the model as a basis for analysis or planning.
This article examines the discipline required to organize large ArchiMate repositories. It explains why large-scale models become difficult to manage, then sets out principles for structuring them around navigability, abstraction, canonical anchors, and federated ownership. From there, it applies those principles to layering, viewpoints, modularization, governance, tooling, and scaling patterns. The central argument is simple: a large ArchiMate repository should be treated as a shared architectural knowledge system. Its purpose is not merely to document the enterprise, but to support impact analysis, roadmap planning, governance, and coordinated change.
Why Large-Scale ArchiMate Models Become Difficult to Manage
Large ArchiMate repositories usually become difficult to manage because structure and operating discipline fail to keep pace with growth. The notation is not the limiting factor. ArchiMate can represent strategy, business, applications, technology, and change perfectly well. Problems appear when the repository expands faster than the conventions needed to manage abstraction, semantics, reuse, and ownership.
One recurring issue is inconsistent abstraction. Different architects naturally model at different levels of detail depending on their role and immediate purpose. A business architect may work at enterprise level, describing capabilities and value streams. A solution architect may model interfaces and deployments for a specific initiative. Both views are legitimate. Trouble starts when they are mixed without clear rules. The repository becomes uneven: one domain looks fully traceable, another is little more than placeholders. Cross-domain analysis then becomes unreliable because missing detail may reflect inconsistent modeling rather than actual gaps in the enterprise.
Semantic drift is another common source of decay. Terms such as service, platform, product, function, and application often mean different things to different teams. Without active control, the repository fills with elements that are structurally valid but conceptually incompatible. Two teams may both create business services, for example, while one uses them for customer-facing offerings and the other for internal support. Once that happens, reporting and impact analysis lose precision because similar-looking elements no longer mean the same thing.
A familiar micro-example appears in identity modernization. One team models “Authentication” as a shared platform service consumed by many applications. Another models the same concept as a business-facing application used only by workforce systems. Both diagrams may look reasonable in isolation, yet enterprise-level analysis becomes misleading because the repository is no longer speaking one language.
A third difficulty arises when the repository is shaped around projects instead of the enterprise itself. This happens often because transformation programs, modernization efforts, and regulatory initiatives fund the modeling work. The result is a skewed landscape: areas in motion are modeled in detail while stable but strategically important shared assets remain thinly represented. The repository becomes a map of current activity rather than a map of enduring enterprise structure.
Tool usage can amplify the problem. In large repositories, teams often slip into copy-and-modify habits, local diagram ownership, and view-centric modeling. If canonical elements are not reused, duplicates spread quickly. If relationships are added only to make a single view readable, the underlying model loses integrity. A diagram may appear complete while the repository beneath it remains logically weak.
Scale also exposes governance weaknesses. Informal consistency may work in a small architecture team, but it rarely survives in a federated community. Naming standards are applied unevenly. Domain ownership becomes blurred. Stale content sits beside current material with no clear distinction. Before long, stakeholders stop treating the repository as a reliable source for decision-making.
Consider a payments domain in a global bank. The European team models “Card Authorization Service” as a business service linked to customer channels. The North American team models the same concept as an application service exposed by a switching platform. Meanwhile, a fraud program creates a third version inside its project folder because it cannot find either of the first two. The issue is not notation; it is the absence of shared structure and governance.
All of these issues point to the same conclusion: a large ArchiMate repository is a shared operational knowledge system. If it is going to scale successfully, it must be designed so that growth produces insight rather than confusion. That requires explicit structuring principles.
Core Principles for Structuring Enterprise Architecture Models
The strongest large repositories are usually guided by a small number of clear principles. Those principles shape how the model is partitioned, how relationships are used, and how contributions are governed.
1. Design for navigability, not just completeness
At enterprise scale, it matters less whether everything is modeled than whether the repository is easy to move through. Stakeholders should be able to start from a capability, application, product, platform, or initiative and follow meaningful paths to related concepts. That is where practical value emerges: the repository supports analysis instead of serving as static documentation.
2. Separate abstraction levels while preserving traceability
Large enterprises need strategic, domain, and implementation-oriented models, but those levels should not be blended indiscriminately. High-level concepts such as capabilities, target states, and strategic platforms should remain readable and relatively stable. More detailed material—interfaces, process steps, deployments, environment-specific dependencies—should sit beneath them in controlled layers of detail. The aim is not isolation; it is traceability with discipline.
3. Organize around enduring enterprise concepts before temporary change constructs
Programs, projects, and work packages matter, but they should be attached to a model organized around the enterprise itself: capabilities, products, applications, data domains, platforms, and organizational responsibilities. If project logic becomes the main organizing principle, the repository becomes unstable because its structure shifts with funding priorities. Enduring concepts provide continuity; change constructs show how those concepts evolve.
4. Establish canonical model anchors
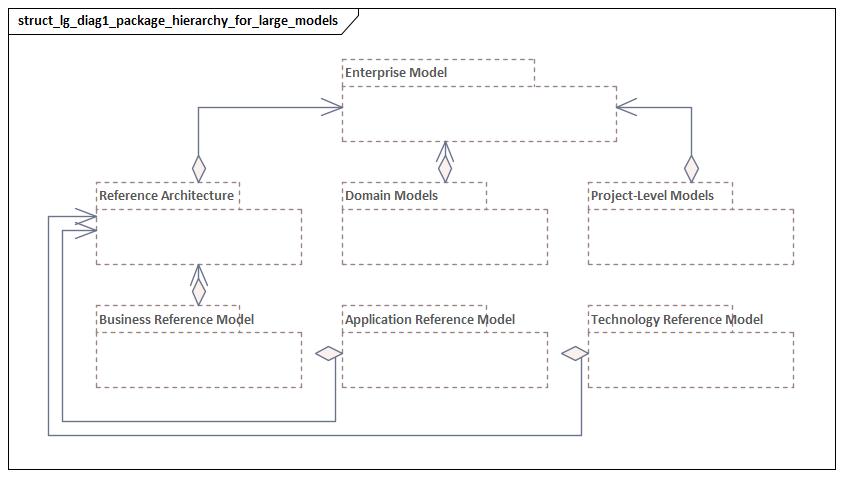
Some elements serve as reference points across the repository. Typical anchors include business capabilities, application components, major data objects, organizational units, and shared technology platforms. These need careful curation, consistent naming, and broad reuse. They form the backbone of the model, and later decisions about modularization, governance, and tooling should protect them.
5. Model relationships deliberately
In a large repository, analytical value depends on trustworthy relationships. Links should carry architectural meaning, not simply make a diagram look complete. A smaller set of dependable relationships is far more useful than a larger set of ambiguous ones. This is especially important when defining module interfaces, quality checks, and published viewpoints.
For example, if an architecture board is deciding whether to retire a legacy integration broker, it must be able to trust the modeled dependencies between business services, application interfaces, and the integration platform. If those links were added casually for presentation purposes, the decision will rest on weak evidence.
6. Use federated ownership with central coherence
Architecture knowledge is distributed, so maintenance must be distributed too. Domain teams should own the accuracy of their content, while central governance defines metamodel usage, naming rules, quality expectations, and the reuse of canonical anchors. That balance allows the repository to scale without losing coherence.
These principles underpin the rest of the article. Layering, viewpoints, modularization, governance, and tooling are simply practical ways of applying them.
Layering, Viewpoints, and Abstraction in ArchiMate
A large ArchiMate repository becomes much easier to use when three ideas are kept distinct: layering, viewpoints, and abstraction. They are related, but they solve different problems.
Layering as structural backbone
Layering organizes the enterprise into broad architectural domains such as business, application, and technology. That gives the repository a stable backbone. Business architecture can focus on capabilities, products, services, and processes. Application architecture can focus on components, services, interfaces, and data usage. Technology architecture can focus on platforms, infrastructure services, nodes, and deployments.
The point, however, is not to create silos. Layers become useful when traceability runs across them. A capability supported by business processes, enabled by application services, and hosted on shared platforms is far more valuable than a set of layer-specific diagrams that never connect.
Viewpoints as purpose-specific representations
Viewpoints are not merely visual formats. They are selective representations of the repository designed to address a stakeholder concern. An executive roadmap view, a capability map, an application cooperation view, and a platform dependency view may all draw from the same model while emphasizing different relationships and suppressing different levels of detail.
That distinction matters in large enterprises. Business leaders rarely need deployment detail. Infrastructure teams rarely need the full strategic capability landscape. By defining viewpoints deliberately, architects can maintain one coherent repository while presenting different slices of it to different audiences. It also reduces the temptation to create disconnected one-off diagrams.
Abstraction as control of detail
Abstraction determines how much detail is shown and what kind of question the model can answer. Even within the same layer and viewpoint, models may exist at enterprise, domain, and solution levels. High abstraction should describe enduring structure and intent. Lower abstraction can show interfaces, integrations, and implementation constraints.
The discipline lies in making those boundaries explicit. If strategic views are overloaded with detail, decision-makers lose the signal. If strategic models cannot be traced downward, they become detached from delivery reality.
A practical tier model
Many enterprises benefit from defining standard model tiers, for example:
- Enterprise overview tier: capabilities, major products, application domains, strategic platforms, target states
- Domain architecture tier: business processes, applications, data objects, platform dependencies within a bounded domain
- Solution realization tier: interfaces, deployments, environment-specific components, implementation dependencies
Each tier can have expected viewpoints, approved relationship patterns, and different governance thresholds. That creates consistency without forcing every stakeholder into the same level of detail.
Why this matters operationally
Take a platform replacement. Layering identifies the affected technology services, applications, and business services. Viewpoints make it possible to represent the issue differently for platform teams, governance boards, and business stakeholders. Abstraction allows the conversation to begin at platform level and then trace down to specific systems and migration work.
A realistic example is an event-streaming modernization. At enterprise tier, the model may show “Real-Time Customer Event Distribution” as a strategic integration capability supported by a shared event platform. At domain tier, retail banking and collections each show their dependence on customer and account events. At solution tier, one view adds Kafka topics, producers, consumers, and resilience constraints for the mobile banking program. The tiers are connected, but not collapsed into one diagram.
Without these distinctions, the repository either becomes too technical for enterprise decisions or too vague for implementation planning.
Modularization Strategies for Large Enterprise Architecture Repositories
Once the repository has clear abstraction rules and a coherent viewpoint strategy, the next challenge is modularization: dividing the model into manageable architectural units.
Modularize around stable boundaries
The most effective modules are usually based on stable architectural boundaries rather than temporary projects or reporting lines. Examples include business domains, product families, application portfolios, data domains, regional operating models, and shared platforms. These boundaries tend to reflect real ownership and dependency patterns, which makes them suitable for long-term maintenance.
Project-based modularization can look attractive because funding and delivery structures are easy to see. In practice, it usually produces a repository that has to be reorganized every time priorities shift. Stable enterprise boundaries provide continuity.
Common modularization patterns
Several patterns can be combined:
- Domain-based modularization: each business or technology domain maintains its own capabilities, processes, applications, data objects, and dependencies
- Platform-centric modularization: shared assets such as identity, integration, cloud foundation, ERP, or data platforms are modeled as dedicated modules
- Transformation overlays: initiatives, roadmaps, and work packages are modeled as overlays linked back to stable domain and platform modules
This combination works well because it preserves enterprise structure while still making change visible.
Shared integration points
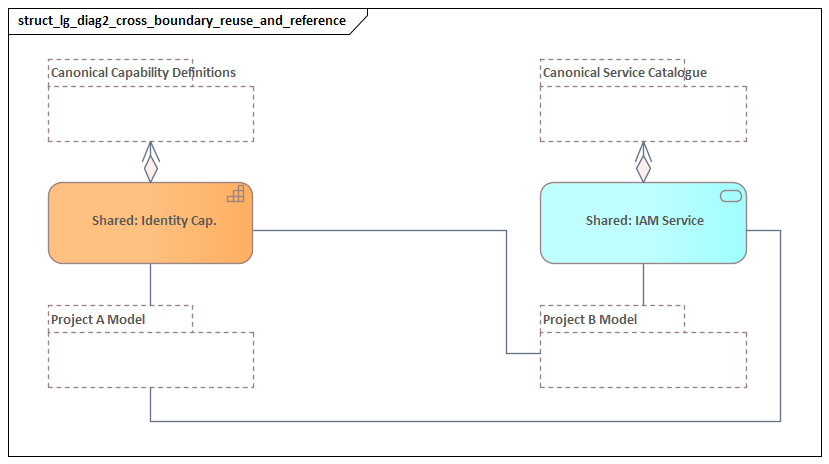
Modules should not become isolated mini-repositories. Each one needs shared integration points built on canonical anchors. These might include enterprise capabilities, major data entities, standard application services, common organizational units, or strategic platforms. Such references allow modules to connect without duplicating internal detail.
This is where relationship discipline becomes critical. Cross-module links should be intentional and meaningful, not ad hoc. Otherwise modularization may reduce local complexity while undermining enterprise-level analysis.
Define module interfaces
A practical way to connect modules is to define what each one publishes for enterprise use. For example:
- A business domain may expose the capabilities and products it owns
- An application domain may expose major application services, owned data, and dependencies on shared platforms
- A platform module may expose technology services, consumption patterns, and compliance constraints
This effectively creates a modeling contract between modules. Other teams can rely on what is published without needing to understand every internal detail.
A good example is an IAM module. It may publish identity services, trust boundaries, onboarding patterns, and dependencies on HR and directory sources. Consumer domains do not need to model the internals of federation, policy engines, or privileged access workflows unless those details are directly relevant to their own architecture decisions.
Govern modules in tiers
Modularization works best when governance is tiered. Domain or platform owners maintain semantic quality and lifecycle status within their modules. Central architecture governance maintains cross-module standards: naming conventions, metadata, relationship patterns, and canonical anchors.
The test of good modularization
A repository is well modularized when one domain can be updated without destabilizing unrelated areas, while architects can still assemble enterprise-wide views for cost, risk, impact, and transformation analysis. If modularization prevents that composition, it has become fragmentation rather than structure.
Governance, Naming Standards, and Model Quality Control
Modularization alone will not keep a repository coherent. Over time, consistency depends on governance, naming standards, and quality controls.
Clarify ownership, stewardship, and assurance
Governance should distinguish between three responsibilities:
- Ownership: accountability for the accuracy of a domain or module
- Stewardship: maintenance of content according to repository standards and lifecycle rules
- Assurance: review of whether the model is fit for enterprise use
These roles may sit with different people or groups. The distinction matters because being closest to the content does not automatically mean being best placed to judge enterprise coherence.
Treat naming as a structural concern
In large repositories, naming is not cosmetic. It affects search, reuse, interpretation, and reporting. Names should make clear what an element represents, how specific it is, and whether it is canonical or contextual. Capabilities should be expressed as stable business abilities. Applications should be recognizable enterprise systems. Technology services should, where possible, be named as consumable services rather than vendor products.
Poor naming directly undermines navigability and reuse. If architects cannot find existing anchors, they will create duplicates.
Control vocabulary and semantics
A short modeling glossary is often more useful than extensive style guidance. Terms such as service, product, interface, domain, and platform need explicit interpretation within the repository. Without that, semantic drift returns even when notation usage is technically correct. Governance should therefore define not only which element types are allowed, but also what they mean in enterprise practice.
Use both structural and architectural quality checks
Quality control needs to happen at two levels.
Structural checks can often be automated:
- required metadata present
- naming rules followed
- duplicate candidates flagged
- invalid or discouraged relationship patterns identified
- missing ownership or lifecycle status detected
Architectural checks require judgment:
- Is the abstraction level appropriate?
- Are canonical anchors reused?
- Do the relationships tell a coherent story?
- Is the content sufficient for the intended analysis?
- Are cross-module dependencies represented at the right level?
A repository can pass syntax checks and still fail as architecture. Both forms of quality control are necessary.
Manage lifecycle visibly
Elements and views should carry statuses such as draft, approved, active, transitional, and retired. Review dates and responsible owners should also be visible. Without that, stale content becomes indistinguishable from current architecture, and trust starts to erode.
Visible lifecycle status also supports roadmapping. When baseline, transition, and target states are represented clearly, stakeholders can see not only what the enterprise looks like now, but how it is expected to change.
For instance, a technology review board may decide that an on-premises Oracle integration hub is “tolerate until Q4 2026,” while a legacy MQ-based notification product is “eliminate in new solutions immediately.” If those statuses are visible in the repository, downstream roadmaps and impact assessments become much easier to manage.
Keep governance lightweight but enforceable
Too little governance leads to entropy. Too much pushes architects back into local documents and slideware. Effective repository governance defines a small set of mandatory controls, embeds them in the tool workflow, and concentrates review effort where enterprise impact is greatest.
Tooling, Collaboration, and Lifecycle Management for ArchiMate Models
The structure described so far will only last if tooling and collaboration practices reinforce it. Tools influence contributor behavior, shape reuse, and determine whether lifecycle and governance controls can be applied consistently.
Choose tools for repository operation, not just notation support
Many tools can draw ArchiMate diagrams. Far fewer can support a large shared repository with object reuse, metadata governance, versioning, workflow, and controlled publishing. For enterprise use, the key question is not whether the tool supports the notation, but whether it supports a model base rather than a collection of pictures.
Capabilities that matter most typically include:
- object reuse across views
- relationship integrity validation
- metadata and taxonomy management
- role-based access
- approval workflows
- version and change history
- publishing to stakeholder-friendly portals
- integration with adjacent sources such as CMDB, portfolio, or lifecycle data
These capabilities directly support navigability, canonical anchors, and federated ownership.
Balance central discipline with distributed contribution
Large enterprises need domain teams to maintain their own content. A central modeling team cannot keep pace with every change. But unrestricted editing quickly damages quality. Effective tooling should therefore support delegated ownership, role-based permissions, review workflows, and publishing controls.
That allows contributors to work directly in the repository while protecting the integrity of canonical elements and cross-domain structures.
Separate authoring from consumption
Most stakeholders should not need the full modeling environment. Architects and stewards can work in the authoring tool, while business leaders, product managers, risk teams, and delivery leads consume curated views through portals, dashboards, or lightweight reports. This reduces friction and helps the repository play a real part in governance and planning.
It also reinforces the distinction between model and viewpoint: one shared model can support many published representations.
Treat lifecycle management as a core capability
Repository content changes constantly. Applications are modernized, ownership shifts, platforms are retired, and target states evolve. Tooling should support baseline, transition, target, and retirement states in a way that is both visible and manageable. Otherwise historical content piles up and current-state analysis becomes unreliable.
Manage versions carefully
Simple file versioning is not enough for large repositories with many contributors. Architects need to know what changed, why it changed, who approved it, and which views or reports are affected. Controlled change sets are often more practical than widespread branching. Excessive branching creates parallel versions of reality that are difficult to reconcile. In most enterprises, a stable core repository with governed updates works better.
Connect the repository to enterprise processes
Even a well-maintained repository becomes stale if it is disconnected from decision-making. It should be linked to architecture review, investment planning, technology lifecycle management, risk assessment, and solution governance. In a mature practice, changes in the enterprise trigger changes in the repository, and the repository in turn informs enterprise decisions.
Common Pitfalls and Practical Patterns for Scaling ArchiMate in the Enterprise
Even with sound structure and governance, large-scale ArchiMate practice tends to fail in predictable ways. Most of the common pitfalls are simply failures to apply the earlier principles consistently.
Pitfall 1: building a diagram estate instead of a model estate
Teams often produce large numbers of views for workshops and governance reviews, but fail to maintain the underlying objects as reusable assets. The result is visible activity without a dependable model base.
Practical pattern: create or update canonical elements first, then assemble viewpoints from them. Diagrams should present the model, not replace it.
Pitfall 2: over-modeling local complexity
As teams become more comfortable with ArchiMate, they may begin to model every interface variation, deployment nuance, or exception. That can overwhelm the shared repository and make enterprise-level reasoning harder rather than easier.
Practical pattern: use progressive elaboration. Keep the shared core at the level needed for enterprise decisions, and place fine-grained detail in bounded domain or solution areas.
Pitfall 3: false standardization
Some organizations respond to inconsistency by imposing rigid templates that force unlike situations into the same shape. The result is formal consistency without real clarity.
Practical pattern: standardize only the essentials—core element usage, naming, metadata, relationship conventions, and canonical anchors. Allow controlled variation in viewpoints and emphasis.
Pitfall 4: weak treatment of cross-cutting concerns
Security, resilience, integration, compliance, and data governance are often either modeled everywhere, creating clutter, or barely modeled at all, making them invisible.
Practical pattern: represent cross-cutting concerns through focused reference structures linked to affected domains, applications, services, and platforms. For example, model Kafka as a shared event backbone once, then connect consuming domains through published event services and dependency relationships rather than duplicating the platform in every domain view.
Pitfall 5: relying on a specialist modeling community only
If only a small specialist group understands or maintains the repository, it will not scale with enterprise change.
Practical pattern: use layered participation. Specialists maintain metamodel integrity, domain architects curate content, and broader stakeholders contribute through structured inputs, review workflows, and published views.
Pitfall 6: modeling without anchoring on enterprise questions
Repositories often grow into documentation stores rather than decision-support tools.
Practical pattern: shape the model around recurring questions such as:
- Which capabilities depend on end-of-life technology?
- Where are critical applications concentrated on shared platforms?
- Which initiatives are affecting the same data domain?
- What business services would be disrupted by a platform change?
When the repository is designed to answer questions like these, decisions about abstraction, canonical anchors, and traceability become much easier.
Conclusion
Structuring a large ArchiMate repository is not primarily a diagramming problem. It is an enterprise design problem: how to create a shared architectural knowledge system that remains navigable, coherent, and trustworthy as complexity grows.
The disciplines are consistent throughout. Start with explicit principles: design for navigability, separate abstraction levels, organize around enduring enterprise concepts, establish canonical anchors, model relationships deliberately, and balance federated ownership with central coherence. Then apply those principles through layering, viewpoints, modularization, governance, tooling, and practical scaling patterns.
A mature repository is not defined by the number of diagrams it contains. It is defined by whether stakeholders can rely on it to answer real questions about dependency, impact, lifecycle, investment, and transformation. If the model allows architects and decision-makers to move from strategic intent to implementation consequences without rebuilding the logic each time, then its structure is doing its job.
In the end, trust is the real outcome of good structure. When stakeholders believe the repository is current, semantically consistent, and connected to enterprise processes, it becomes part of how change is governed. When they do not, it becomes passive documentation.
So the goal is not to model everything. It is to model the enterprise in a way that remains intelligible, governable, and actionable at scale.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business operations, information systems, and technology infrastructure. It provides a structured framework for understanding how an enterprise works today, where it needs to go, and how to manage the transition.
How is ArchiMate used in enterprise architecture practice?
ArchiMate is used as the standard modeling language in enterprise architecture practice. It enables architects to create consistent, layered models covering business capabilities, application services, data flows, and technology infrastructure — all traceable from strategic goals to implementation.
What tools are used for enterprise architecture modeling?
Common enterprise architecture modeling tools include Sparx Enterprise Architect (Sparx EA), Archi, BiZZdesign Enterprise Studio, LeanIX, and Orbus iServer. Sparx EA is widely used for its ArchiMate, UML, BPMN and SysML support combined with powerful automation and scripting capabilities.