⏱ 25 min read
Scaling ArchiMate Models in Large Enterprises: Governance, Reuse, and Repository Strategy ArchiMate training
Learn how to scale ArchiMate models in large enterprises with practical strategies for governance, model reuse, repository management, stakeholder views, and architecture consistency. ArchiMate tutorial for enterprise architects
Scaling ArchiMate models, ArchiMate in large enterprises, enterprise architecture governance, ArchiMate repository strategy, ArchiMate model management, architecture model reuse, ArchiMate best practices, enterprise architecture at scale, ArchiMate stakeholder views, architecture consistency, EA repository management, large-scale architecture modeling ArchiMate layers explained
Introduction
In large enterprises, ArchiMate is not just a notation for drawing architecture diagrams. Used well, it becomes a practical way to connect strategy, operating model design, solution delivery, risk oversight, and technology change. As organizations grow through acquisition, regional expansion, product diversification, and platform modernization, isolated diagrams and team-specific views stop being enough. The challenge is not producing more models. It is keeping them useful, credible, and relevant across different decisions and time horizons. ArchiMate relationship types
Scaling ArchiMate is therefore not about filling a repository with more content. It is about building a modeling practice that can absorb complexity without collapsing into duplication, inconsistency, or excessive detail. Enterprise architects face a familiar tension. Stakeholders want stronger traceability from strategic objectives to capabilities, processes, applications, and technology platforms. At the same time, too much detail creates model fatigue and undermines confidence in the repository. A scalable practice manages that tension deliberately. ArchiMate modeling best practices
Different audiences need different levels of abstraction. Executives need concise views that show impact, dependency, cost, and risk. Domain architects need models that clarify ownership boundaries, service relationships, and transition states. Delivery teams need enough context to align implementation choices with enterprise standards and target-state direction. Consider an architecture board reviewing a proposed regional CRM variant. It needs a short view of capability impact, integration consequences, and target-state fit, not a repository dump with every related application and interface. A scalable ArchiMate practice supports those needs without forcing every stakeholder into the same level of detail. That requires disciplined layering, purposeful viewpoints, and conventions that help each model answer a specific question.
Scaling is also a governance problem. Large enterprises are rarely running a single transformation agenda. More often, they are managing cloud migration, regulatory change, ERP consolidation, cybersecurity uplift, and customer-facing modernization at the same time, often in the same domains. ArchiMate becomes valuable when it reveals where those efforts intersect, compete, or depend on one another. That only happens when repository structure, naming standards, ownership rules, lifecycle states, and abstraction levels are governed consistently.
Selectivity matters just as much. The aim is not to represent everything. The aim is to maintain a living architectural knowledge base that helps the enterprise make better decisions, faster. In practice, that means modeling where traceability and impact analysis matter most: critical capabilities, regulated processes, shared applications, key data domains, and major technology platforms. It often includes cross-cutting concerns such as IAM modernization, event platforms built on Kafka, or technologies approaching end of life.
This article examines ArchiMate scaling on those terms. It begins with the reasons enterprise repositories become difficult to manage, then moves through governance, repository structure, complexity management, collaboration, and long-term quality. Across all of those topics, one point remains constant: scale does not come from model volume. It comes from preserving coherence, reuse, and decision value as the enterprise evolves.
Why ArchiMate Models Become Difficult to Scale in Large Enterprises
In most large organizations, scaling problems appear when repository growth outpaces the organization’s ability to keep the model coherent. The notation is rarely the issue. ArchiMate can represent strategy, business, application, technology, physical, and implementation relationships effectively. The real difficulty starts when many teams model the same enterprise for different purposes, at different levels of maturity, and with different assumptions. Without a shared operating model, the repository turns into a collection of locally useful diagrams rather than a dependable enterprise asset.
Inconsistent abstraction is one of the most common failure points. A business architect may model a capability at a high level, while a solution architect decomposes the same area into processes, services, interfaces, and applications. At the same time, a transformation office may describe it in broad roadmap terms. None of those views is wrong in isolation. Problems begin when the relationships between them are unclear. Stakeholders can no longer tell whether two elements represent the same thing, different levels of decomposition, or competing interpretations. The result is predictable: duplication, contradictory views, and repeated debates over which model is authoritative.
A simple example illustrates the point. A retail bank may model “Customer Onboarding” as a business capability in its strategic architecture. Meanwhile, a digital channel team models onboarding as a journey with KYC steps, identity verification services, and mobile app interactions. At the same time, a compliance program models onboarding as a control-heavy process tied to anti-money-laundering obligations. All three views may be valid. If they are not linked clearly, however, the repository ends up with three different versions of the same enterprise concern and no reliable path between them.
Organizational fragmentation creates a second problem. Large enterprises often model along reporting lines, business units, or regions because that is how funding and accountability are structured. Over time, those choices produce local modeling habits with different naming rules, decomposition styles, and ownership assumptions. The repository begins to reflect enterprise politics more accurately than enterprise architecture. That becomes especially damaging when the organization needs to analyze cross-cutting concerns such as identity, resilience, data flows, or shared platform risk. An IAM modernization program may span HR systems, customer channels, privileged access tools, and cloud platforms, but fragmented models make that end-to-end dependency difficult to see.
Repository and tool design also have an outsized effect at scale. In smaller environments, architects can compensate for weak structure through personal knowledge and informal coordination. In large environments, that no longer works. If the repository lacks clear organization, metadata discipline, status indicators, and relationship conventions, users struggle to find relevant content or determine whether it is current. Search results fill with near-duplicates. Workshop diagrams remain visible long after they have lost relevance. Relationships may exist in theory, but they are not applied consistently enough to support impact analysis. The repository becomes a presentation store instead of an analytical one.
Another barrier is the mismatch between the speed of change and the pace of model maintenance. Enterprises change continuously: products are retired, teams are reorganized, cloud services are introduced, controls evolve, and integration patterns shift. If ArchiMate updates are treated as a separate architecture exercise rather than part of delivery and governance workflows, the model drifts away from reality. Once that drift becomes visible, trust drops quickly. Architects then spend more time defending the repository than using it.
This is particularly common in fast-moving integration domains. A manufacturer introducing an event-driven architecture may stand up Kafka clusters, define new topics, and onboard producers and consumers in a matter of weeks. If the repository is updated quarterly, the architectural model will lag the operating environment almost immediately. Teams then fall back to spreadsheets, wiki pages, and tribal knowledge for dependency analysis, even though the enterprise already has a modeling repository.
Scaling also fails when success is measured by coverage rather than decision support. Repositories often grow because teams are told to document everything, not because they need to answer specific enterprise questions. That produces volume without clarity. A more effective practice focuses on the parts of the enterprise where traceability, comparison, and impact insight are genuinely needed. In large enterprises, scale comes not from maximizing model size, but from keeping the repository coherent enough to support meaningful decisions.
Establishing Governance, Standards, and Modeling Principles
If scale problems are really coherence problems, governance is what preserves coherence. That does not require heavy approval for every model change. It requires a clear minimum set of rules that keeps the language usable across domains, portfolios, and programs. Good governance reduces ambiguity without making the repository so cumbersome that teams avoid it.
A practical starting point is a small set of modeling principles rather than an exhaustive rulebook. Principles last longer than detailed standards and help architects make sensible decisions in situations the standards do not yet cover. Typical examples include modeling for decision support, separating conceptual and implementation concerns, reusing existing elements before creating new ones, making ownership explicit, and capturing only the level of detail required for the intended viewpoint. In large enterprises, those principles matter because edge cases are constant: shared platforms with many consumers, temporary transition states, partially outsourced processes, or products spanning several business units.
Standards then translate those principles into working conventions. At a minimum, enterprises should define naming rules, element definitions, preferred relationship patterns, decomposition rules, status values, and mandatory metadata. Naming should clearly distinguish business concepts, logical application structures, deployed technology, and initiative-specific work. Relationship standards matter just as much. If one team uses a serving relationship to express a dependency while another uses assignment or association for the same pattern, the repository loses analytical value even if both diagrams look reasonable. A useful standard does not need to prescribe every ArchiMate construct, but it should define preferred patterns for the organization’s most common cases, such as identity services, event publishers and consumers, shared platform dependencies, or external SaaS integrations.
Governance must also clarify ownership. Accountability for the repository platform, the metamodel and standards, and the content domains should not be blurred together. Without that separation, governance becomes either too centralized to scale or too fragmented to preserve consistency. In most large enterprises, a federated model works best: a small central architecture function maintains standards and quality controls, while domain architects own the accuracy and evolution of content in their areas. That balance preserves enterprise comparability without losing local expertise.
Review mechanisms should reinforce quality and reuse rather than create bureaucracy. Architecture review boards, portfolio checkpoints, and solution governance forums can all help validate that new content aligns with standards, reuses existing enterprise objects where possible, and adds meaningful traceability. For instance, an architecture board may approve consolidation onto a single workforce identity provider while rejecting a separate customer IAM stack because the model shows duplicated capabilities, fragmented controls, and unnecessary integration risk. In another case, a payments program might be required to reuse the enterprise “Settlement Service” object rather than creating a project-specific equivalent, simply because the existing object already anchors the right application and technology relationships.
Governance also needs proportion. Different model types require different quality thresholds. A strategic capability view should not be held to the same completeness standard as a deployment model. A transition architecture may legitimately contain temporary abstractions that would be inappropriate in a steady-state domain model. Defining what is “good enough” by viewpoint keeps governance realistic and supports a layered modeling approach.
Done well, governance makes modeling predictable for contributors and trustworthy for consumers. Architects and analysts know how to create content that fits the enterprise model, and decision-makers can rely on the outputs as structured representations of enterprise reality rather than polished slides. That reliability is what makes repository reuse and cross-domain traceability workable at scale.
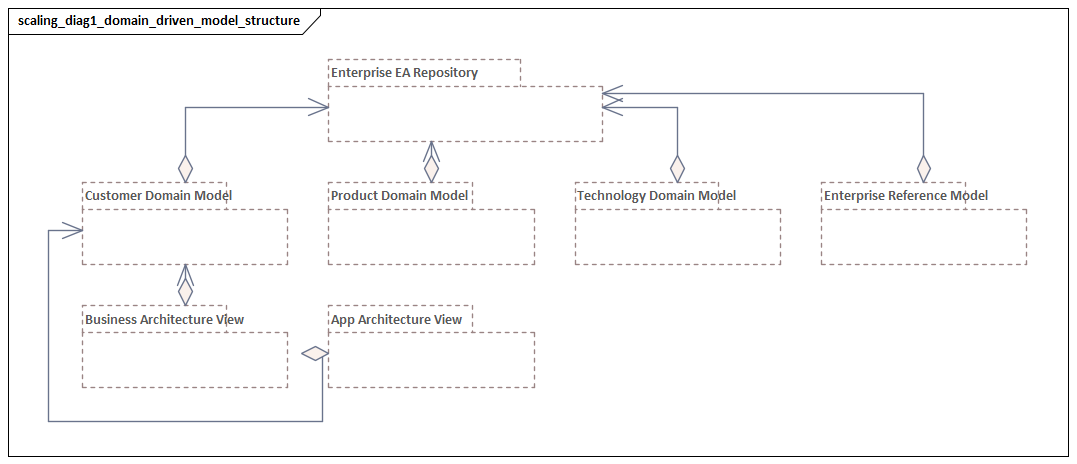
Structuring the Architecture Repository for Reuse and Maintainability
Governance defines how ArchiMate should be used. Repository structure determines whether those rules can be applied consistently. If the repository is poorly organized, even good standards will be applied unevenly. If it is designed well, reuse becomes natural and maintenance becomes manageable.
A strong starting point is to organize the repository around stable architectural domains rather than projects or reporting structures. Core capabilities, value streams, products, applications, data domains, technology platforms, and shared services should have persistent homes that remain valid as programs begin and end. Initiative content should reference those enterprise objects rather than redefine them. This distinction matters. Reusable repository content represents enduring enterprise structure; initiative content represents change against that structure. When the two are mixed together, temporary delivery artifacts begin to look like long-lived architecture.
The repository should also make abstraction levels explicit. Unclear abstraction is one of the main sources of duplication and confusion. A practical pattern is to distinguish conceptual, logical, and physical or deployed representations where relevant. That separation does not need to be rigid in every domain, but it does need to be navigable. Stakeholders should be able to move from executive-level constructs to operational detail without losing continuity.
An event architecture provides a straightforward example. A conceptual view may show business events such as Order Accepted and Payment Failed. A logical view may show event domains, event services, and publisher-consumer relationships. A physical view then shows Kafka clusters, topics, schemas, and consuming applications. If those levels are mixed into one flat model, stakeholders either drown in detail or lose the ability to trace decisions into implementation.
Metadata design is equally important. At enterprise scale, the repository must do more than store ArchiMate elements and relationships. It needs to help users understand status, ownership, criticality, lifecycle, geography, regulatory relevance, and sourcing model. These attributes allow the same architectural core to answer different questions for different stakeholders. Application portfolio teams may want to identify end-of-life systems. Resilience teams may want to assess concentration risk. Transformation offices may want to understand regional dependencies. Without disciplined metadata, those analyses drift back into spreadsheets and slide decks, weakening the repository’s value.
Another foundational practice is to separate canonical objects from viewpoint-specific views. The object should be maintained once, with controlled relationships and metadata, while views are assembled to answer particular questions. This improves reuse because many diagrams can draw on the same underlying facts. It also improves maintainability because updating the object updates every dependent view. This is one of the clearest differences between a scalable repository and a slide library: in a mature practice, diagrams are not the architecture, but curated windows into it.
Lifecycle management should be built into the repository from the beginning. Objects need statuses such as proposed, active, transitional, deprecated, and retired, along with review dates and accountable owners. Without this, old architecture remains visible without context and is easily mistaken for current state. In large enterprises, stale content does more than create clutter; it distorts decisions.
A realistic example is technology lifecycle governance in a global insurer. The repository may show that a legacy MQ broker is in sunset status, Kafka is the target integration standard, and seventeen applications still depend on the old platform. That single status model can support several conversations at once: portfolio prioritization, resilience risk review, infrastructure budgeting, and migration sequencing. Without lifecycle metadata, the same decision would depend on manual reconciliation across several teams.
Cross-domain navigation is equally important. Users should be able to move from a capability to the business services it enables, the applications that support those services, the data involved, and the technology platforms underneath them. That navigability is what makes reuse practical. It also enables complexity management through layering, viewpoints, and decomposition. Without a well-structured repository, those techniques become presentation tricks rather than scalable modeling practices.
Managing Complexity Through Layering, Viewpoints, and Decomposition
Once governance and repository structure are in place, complexity can be managed deliberately rather than reactively. Different audiences need different abstractions, but that principle only works when the enterprise has practical ways to control what is shown, how detail is introduced, and how views remain connected. Layering, viewpoints, and decomposition provide those controls.
Layering is the first mechanism. In enterprise practice, layers should be treated less as isolated stacks and more as decision lenses. The strategy layer is useful for discussing intent, investment themes, capability uplift, and transformation outcomes. The business layer clarifies operating model implications, accountability, and service delivery. The application and technology layers explain enablement, constraint, and implementation feasibility. The value lies in showing only the layers needed for the decision at hand while preserving traceability to adjacent layers.
An executive investment discussion, for example, may focus on goals, capabilities, and value streams. That does not mean application and technology detail is irrelevant. It means the discussion starts at the level of business decision and only traces downward when challenge or prioritization requires it. By contrast, a resilience review may start in the technology layer and trace upward to identify which business services and capabilities are exposed by a single-region deployment pattern.
Viewpoints make this selective exposure practical. A scalable viewpoint is defined by the question it answers, not by a generic audience label. A transformation dependency viewpoint might cut across business, application, and implementation elements to show where several programs converge on the same process area or platform. A risk concentration viewpoint might show critical business services supported by aging applications and single-region infrastructure. A domain ownership viewpoint might focus on responsibility boundaries, interfaces, and shared services.
An IAM modernization viewpoint is a good example of purposeful scoping. It may show identity providers, authentication services, joiner-mover-leaver processes, privileged access controls, and the applications affected by migration to a central platform. It does not need to show every surrounding business process, every support application, or every network component. Its usefulness comes from making one enterprise question clear: what must change, who depends on it, and where the risks sit.
Decomposition provides the bridge between enterprise coherence and domain detail. In large organizations, decomposition should be driven by modeling intent, not by the enthusiasm of individual teams. Not every capability needs process-level expansion, and not every application needs component-level modeling. Decomposition adds the most value where the enterprise needs sharper analysis: regulated control points, customer-critical journeys, shared platforms, integration-heavy domains, or costly legacy estates.
A useful discipline is to define decomposition thresholds. A capability may be decomposed only when it is strategically differentiating, operationally unstable, or undergoing major change. An application may be decomposed further only when it presents significant integration, resilience, or modernization risk. Event-driven domains often meet that threshold. Once Kafka becomes a shared integration backbone, it is usually worth decomposing producers, consumers, event contracts, and platform services because those details affect ownership, coupling, and recovery planning.
One pharmaceutical company, for instance, modeled “Batch Release Management” as a single capability for years. That was sufficient until regulatory remediation exposed dependencies across quality systems, manufacturing execution, document management, and laboratory platforms. At that point, decomposition became necessary. The capability was broken into controlled process areas, supporting applications, key data objects, and technology services. The result was not a larger diagram for its own sake. It was a model precise enough to show where a validation change in one system would affect release timing across several plants.
Taken together, layering, viewpoints, and decomposition allow one repository to support multiple planning horizons. Enterprise portfolio planning may need broad capability and transition views. Domain architecture may need service interaction and ownership detail. Solution delivery may need specific interfaces, events, or platform relationships. A mature practice does not force all of this into one master diagram. Instead, it creates a connected set of abstractions in which each view is purposeful, each decomposition step is justified, and each layer contributes to a chain of reasoning that can be followed when necessary.
Applied consistently, this approach changes the role of the repository. It stops being a store of dense diagrams and becomes a mechanism for progressive disclosure. Stakeholders see only the complexity needed for the decision in front of them, while architects retain the continuity required for traceability, impact analysis, and coordinated change.
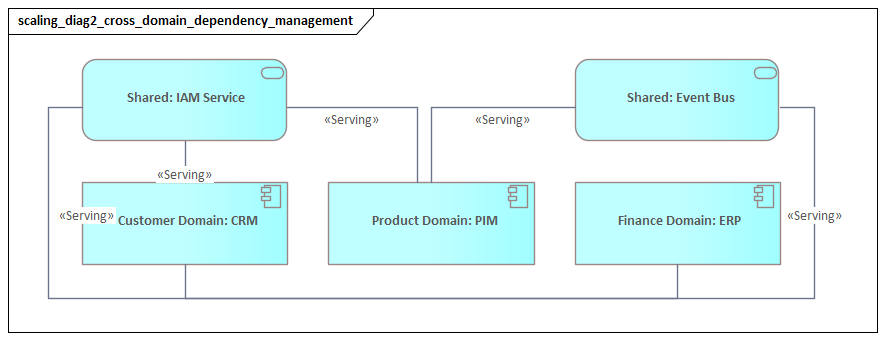
Enabling Collaboration Across Teams, Domains, and Toolchains
The previous sections focused on coherence inside the repository. At scale, that coherence also has to extend across the people and tools involved in enterprise change. A technically well-structured model will still fail if it remains confined to a central architecture team. In large organizations, architecture knowledge is distributed across business architects, process owners, application teams, platform engineers, cybersecurity specialists, data teams, and portfolio managers. Collaboration is what turns ArchiMate from a specialist artifact into a shared decision asset.
One practical challenge is that these teams work in different rhythms and on different platforms. Portfolio managers use roadmapping tools, delivery teams work in agile systems, service teams maintain operational inventories, and engineers document implementation in cloud or DevOps environments. A scalable ArchiMate practice should therefore be explicit about where the modeling repository is the system of record, where it consumes authoritative data, and where it acts as an integration layer between sources. That avoids the common failure mode of asking teams to maintain the same facts in multiple places without clear value.
This is why federation across toolchains matters. Some architectural objects should be mastered outside the modeling tool and linked through synchronization or metadata integration. Application inventories, technology assets, project portfolios, ownership records, and control libraries are common examples. ArchiMate adds value when it connects these sources into a coherent enterprise model, not when it duplicates them badly. Canonical structure should be maintained once, while views and analyses draw on both modeled relationships and authoritative operational data.
Collaboration also depends on clear working agreements between domains. Teams need to know who can create enterprise-level objects, who can refine them, who approves cross-domain relationships, and how conflicts are resolved when several initiatives affect the same area. Without these agreements, collaboration slips into parallel modeling, with each team producing a locally valid but enterprise-incompatible view. Federated governance provides the basis for these contribution patterns, but it must be translated into day-to-day practice.
Accessibility matters as much as formal control. Many repositories fail because they are intelligible only to trained architects. To scale, ArchiMate outputs must be usable by non-specialists without losing rigor. That usually means combining formal views with concise narrative, business-friendly labels, curated legends, and role-specific dashboards. Operational leaders and engineering teams do not need to become notation experts, but they do need to validate whether the model reflects reality. If they cannot do that, the repository will drift.
The social operating model is therefore as important as the technical one. Cross-domain forums, initiative intake processes, and recurring synchronization between enterprise architects and delivery leads create the conditions for continuous refinement. Often, the most useful collaborative behavior is not modeling together, but validating together: confirming that capability owners, application managers, and platform architects all recognize the same dependency chain and its implications.
Take a Kafka platform review in a telecommunications company. The platform team may own cluster configuration and nonfunctional standards. Domain teams may own event topics and consumer services. Security may own encryption and access policy. The architecture repository does not need every engineer to model directly in ArchiMate. It does need a shared view that makes topic ownership, critical consumers, resilience requirements, and platform dependencies visible enough for all three groups to validate the same picture.
When collaboration is designed well, the repository becomes part of a broader architecture ecosystem. It connects strategy to delivery, domains to shared services, and architecture intent to operational evidence. That is what allows quality and traceability practices to be sustained over time.
Sustaining Model Quality, Traceability, and Change Over Time
Once an ArchiMate practice is established, the harder challenge is keeping it useful as the enterprise changes. Repository decay rarely comes from one major failure. More often, it appears gradually: weak ownership, delayed updates, inconsistent interpretation, and transition states that are modeled once and then forgotten. Sustaining value requires operating disciplines that treat the repository as part of the enterprise change system, not as a separate documentation exercise.
A good starting point is to manage quality as a set of measurable characteristics rather than as subjective judgment. Quality indicators can include completeness for critical domains, relationship validity, metadata currency, ownership coverage, and view relevance. An application object with no owner, no lifecycle status, and no connection to the business services it supports may still exist in the repository, but it has little decision value. Likewise, a strategic capability that links to no initiatives, no supporting services, and no target-state intent is structurally present but analytically weak. Measuring these conditions makes remediation possible without relying on periodic complaints from stakeholders.
Traceability should be treated with the same selectivity discussed earlier. Not every object needs end-to-end traceability across every layer. That is expensive and often unnecessary. Instead, enterprises should define a small number of mandatory traceability paths that matter most to decision-making. They may require traceability from strategic objective to capability, from capability to business service, from business service to application, and from application to technology platform for critical operational areas. In regulated domains, they may also require traceability from obligation to control, process, application, and data object. For IAM modernization, a mandatory path might run from security policy to identity service, to affected applications, to underlying directory and authentication technologies.
Time also needs to be modeled deliberately. Large enterprises operate through overlapping transition states, and architectural truth is often time-bound. A repository that shows only current state can hide planned retirements, interim integrations, target-state dependencies, or future ownership changes. Plateaus, transition relationships, and milestone-linked views should therefore be used routinely where timing affects risk, investment sequencing, or dependency management. This is especially important when several initiatives depend on the same target platform or when temporary states persist longer than expected.
Maintenance becomes sustainable only when it is embedded in operational checkpoints. Portfolio governance can confirm that initiatives reference existing enterprise objects. Solution governance can verify that approved designs update relevant relationships and lifecycle states. Service and platform governance can signal when technologies are upgraded, deprecated, or retired. In a mature practice, the repository changes because the enterprise changes, and those updates are triggered through normal governance events rather than annual cleanup exercises.
A practical example comes from database lifecycle management. When a strategic database version moves into unsupported status, the repository should not simply mark the platform as deprecated and stop there. It should support impact views that show which applications still depend on it, which business services those applications enable, and which remediation initiatives are already funded or missing. That turns lifecycle status into an actionable enterprise control rather than a static label.
It is also important to distinguish tolerated imperfection from unacceptable ambiguity. No large repository is complete in every area, and forcing perfect coverage usually creates administrative overhead with little value. What cannot be tolerated is ambiguity in critical decision paths. If the enterprise cannot reliably determine which applications support a regulated business service, or which platforms underpin a customer-critical capability, then the repository is failing where it matters most. Sustaining quality means concentrating precision where consequences are highest and allowing lighter treatment elsewhere.
The clearest sign of a healthy ArchiMate practice is continued decision relevance. If stakeholders still use the model to assess impact, challenge assumptions, coordinate dependencies, and understand transition risk, then the repository is being sustained effectively. Size and diagram count are poor indicators. Ongoing usefulness is the real measure.
Conclusion
Scaling ArchiMate in a large enterprise is ultimately about preserving usefulness under pressure. As the organization grows, the model has to support decisions across competing priorities, uneven maturity, and constant change. The real test is not whether the repository can represent complexity. It is whether it can help the enterprise act coherently in spite of that complexity.
The argument across these sections is straightforward. Scale problems start when abstraction, ownership, and repository structure are left uncontrolled. Governance and standards create the minimum discipline needed for shared meaning. Repository design turns that discipline into reusable architectural assets rather than disconnected diagrams. Layering, viewpoints, and decomposition make complexity manageable for different audiences. Collaboration connects the repository to the people and toolchains where enterprise knowledge actually resides. Sustained quality ensures that traceability and decision value survive over time.
From a practical enterprise architecture perspective, the most successful organizations treat ArchiMate as an enabling discipline, not a standalone modeling activity. They focus on a small set of high-value outcomes: clearer dependency management, stronger impact analysis, better transition planning, and more reliable communication across domains. They also recognize that scale requires restraint. Not every relationship needs to be modeled, not every viewpoint needs to be standardized, and not every area needs the same depth.
The long-term benefit is architectural continuity. In large enterprises, people, programs, and platforms change constantly, but the need for shared understanding does not. When governance, repository structure, complexity management, collaboration, and maintenance work together, ArchiMate becomes more than a notation. It becomes part of how the enterprise senses change, coordinates response, and maintains coherence across transformation cycles.
Frequently Asked Questions
What is architecture governance in enterprise architecture?
Architecture governance is the set of practices, processes, and standards that ensure architecture decisions are consistent, traceable, and aligned to organisational strategy. It typically includes an Architecture Review Board (ARB), architecture principles, modeling standards, and compliance checking.
How does ArchiMate support architecture governance?
ArchiMate supports governance by providing a standard language that makes architecture proposals comparable and reviewable. Governance decisions, architecture principles, and compliance requirements can be modeled as Motivation layer elements and traced to the architectural elements they constrain.
What are architecture principles and how are they modeled?
Architecture principles are fundamental rules that guide architecture decisions. In ArchiMate, they are modeled in the Motivation layer as Principle elements, often linked to Goals and Drivers that justify them, and connected via Influence relationships to the constraints they impose on design decisions.