⏱ 21 min read
Modeling Microservices Architecture with ArchiMate: A Practical Enterprise Architecture Guide ArchiMate training
Learn how to model microservices architecture with ArchiMate to visualize services, dependencies, interfaces, and deployment views for better enterprise architecture design and governance. ArchiMate tutorial for enterprise architects
Modeling Microservices Architecture with ArchiMate, ArchiMate microservices, microservices architecture modeling, ArchiMate enterprise architecture, microservices design, application architecture modeling, ArchiMate service modeling, enterprise architecture framework, microservices dependencies, deployment architecture visualization ArchiMate layers explained
Introduction
Microservices have become a practical architectural choice for organizations that need to change digital products quickly without giving up scale, resilience, or team autonomy. Instead of delivering a system as one deployable application, teams decompose it into smaller services aligned to business capabilities and release them independently.
That change affects far more than code structure. It reshapes ownership, integration patterns, operational dependencies, governance, and risk. As the number of services grows, informal diagrams and team-specific sketches stop being sufficient. Architects need a way to connect business intent, application behavior, technology platforms, and organizational accountability in one coherent model.
ArchiMate is well suited to that task because it provides a standardized language across business, application, and technology layers. In a microservices environment, this matters. A service is rarely just an API or a container. It usually supports a business capability, exposes behavior through interfaces, owns or exchanges data, depends on other services or events, runs on shared platforms, and operates within governance constraints. ArchiMate makes those relationships explicit instead of leaving them implied. ArchiMate relationship types
This becomes more important as microservices move from early adoption to enterprise scale. At small scale, teams can rely on shared understanding and direct communication. At larger scale, dependencies multiply, boundaries blur, and platform services become central to day-to-day operation. Architects then face practical questions. Which business processes depend on a given service? Which interfaces are enterprise-critical contracts? Where is coupling hidden behind asynchronous messaging or shared data? Which runtime dependencies reduce service autonomy? Which teams own which parts of the landscape? ArchiMate provides a common vocabulary for answering those questions across structure, behavior, data, deployment, and responsibility. ArchiMate modeling best practices
It also supports multiple stakeholder viewpoints without fragmenting the architecture into disconnected diagrams. Business leaders can see how services support capabilities and value delivery. Delivery teams can focus on interfaces, interactions, and data ownership. Platform engineers can examine gateways, brokers, runtime services, and cloud infrastructure. Governance and risk stakeholders can trace controls, trust boundaries, and operational dependencies. These are not separate architectures. They are different views of the same one.
This article explains how to model microservices effectively with ArchiMate. It starts with the core concepts, then shows how to map microservices across layers, represent service interactions and event-driven communication, capture deployment and cloud-native runtime environments, and model governance and operational dependencies. The aim is not simply cleaner diagrams. It is to build models that support impact analysis, design decisions, and enterprise alignment over time.
Why Use ArchiMate for Microservices
The main challenge in microservices is not the number of services. It is understanding the system created by their interactions. That is where ArchiMate adds value. It treats microservices as part of an enterprise structure rather than as isolated technical artifacts.
The first benefit is separation of concerns. In practice, the term microservice is used loosely. It may refer to a business-aligned capability, a deployable application component, an API, or a containerized runtime. Those meanings are related, but they are not interchangeable. ArchiMate helps keep them distinct. A business capability can link to an application service, that service can be realized by an application component, and that component can be deployed on specific technology infrastructure. This distinction matters when services are refactored, redeployed, or replatformed while the business outcome remains the same.
The second benefit is explicit dependency modeling. Microservices are defined by relationships: service-to-service calls, event flows, data access, platform dependencies, and team ownership. When those relationships remain implicit, the architecture becomes difficult to reason about. ArchiMate provides relationship types such as serving, realization, access, triggering, and flow, making dependencies visible and open to analysis. That helps architects spot coupling, identify where resilience patterns are needed, and understand where a local change may have broader effects.
Consider a retail organization changing its customer profile model. On the surface, the change appears limited to the Customer Profile Service. In the model, however, the same profile data may feed a mobile API, a fraud-scoring event stream, a marketing consent service, and an IAM policy engine. What looked like a local schema change is now clearly an enterprise change.
The third benefit is traceability across layers. A useful microservices model should allow an architect to move from a business change to the affected services, interfaces, data, and runtime dependencies. ArchiMate supports that traceability within one modeling language. This is valuable not only in design, but also in modernization planning, risk assessment, platform standardization, and governance reviews.
Finally, ArchiMate improves communication across stakeholders. Product teams think in customer outcomes and domain boundaries. Platform teams think in runtime services and operational controls. Governance teams think in standards, dependencies, and risk. ArchiMate gives them a shared modeling foundation while allowing each group to work at the right level of abstraction.
The rest of this article builds on those strengths: separation of concerns, explicit dependencies, and cross-layer traceability.
Core ArchiMate Concepts Relevant to Microservices
To model microservices well, it helps to focus on concepts that capture enterprise-relevant behavior rather than every technical detail. The concepts below provide a practical foundation.
Application Component
The Application Component is usually the most appropriate way to represent a microservice as a structural software unit. It captures the service as something with responsibilities, dependencies, and ownership. In most cases, that is more useful than reducing a microservice to only an API or only a deployment artifact.
For example, a Claims Adjudication Service in an insurance platform is best modeled as an application component. It may expose several interfaces and run in multiple environments, but it is still one accountable software element with a defined business purpose.
Application Service
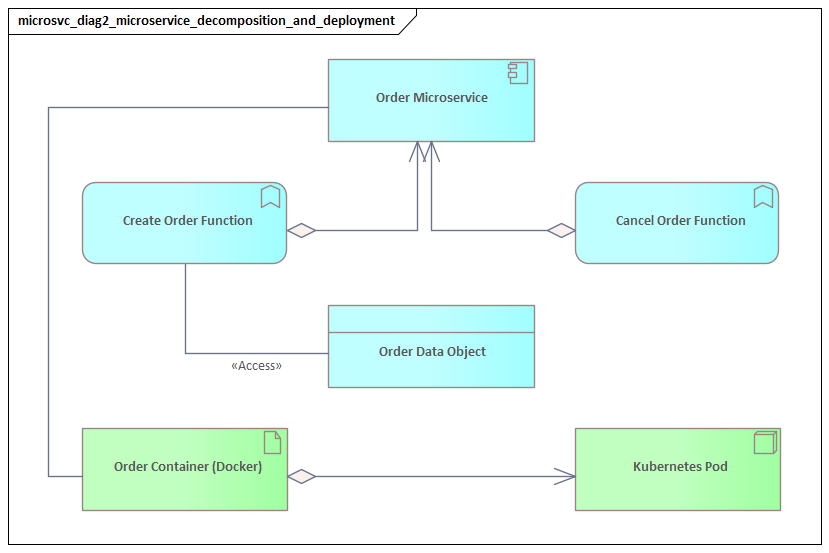
An Application Service represents the externally visible behavior the microservice provides. The distinction matters: the component is the structural element, while the service is the behavior consumers depend on. An Order Service component, for example, may realize application services such as Create Order, Cancel Order, or Retrieve Order Status.
This separation becomes useful when the same component exposes different services to different consumers, or when one service is later split across multiple components without changing the business-facing contract immediately.
Application Interface
The Application Interface shows how the application service is exposed. In a microservices environment, that might be a REST API, a gRPC endpoint, an event publication interface, or a message subscription interface. Modeling interfaces separately from services and components makes contracts visible and supports impact analysis when those contracts change.
A payment platform offers a good example. A Payment Service may expose a REST interface for merchant checkout calls and, separately, an event publication interface for downstream reconciliation and settlement processes. Treating those as distinct interfaces avoids flattening everything into one generic dependency.
Application Function and Application Process
These concepts represent internal behavior. They are useful when a service performs meaningful orchestration, validation, fulfillment logic, or workflow coordination. They should be used selectively to show architecturally significant behavior, not implementation detail.
A Fulfillment Orchestrator, for instance, may coordinate stock reservation, shipment creation, and customer notification. In that case, an application process can legitimately represent the orchestration logic because it affects resilience, troubleshooting, and change impact.
Data Object
A Data Object represents information a service owns, consumes, or produces. In microservices, data ownership often defines service boundaries, which makes this concept especially important. It helps show which service is the system of record, where duplication is intentional, and where hidden shared data compromises autonomy.
Technology Layer Concepts
At runtime, microservices depend on technology elements such as Node, System Software, Technology Service, and Artifact. These concepts let architects represent container platforms, API gateways, message brokers, managed databases, service meshes, and deployable artifacts.
Key Relationships
Several relationship types are particularly useful:
- Realization: what implements what
- Serving: what provides value or functionality to another element
- Access: what reads or writes data
- Triggering: what initiates behavior or events
- Flow: how information or value moves
Used consistently, these concepts create a vocabulary that connects business alignment, application behavior, data ownership, deployment, and governance without collapsing everything into a single ambiguous “service box.”
Mapping Microservices Across ArchiMate Layers
With those concepts in place, the next step is to map each microservice across layers rather than representing it only as an application component. This is where ArchiMate starts to show its value as an enterprise architecture language rather than a software sketching tool.
Business Layer
At the business layer, a microservice should connect to the business capability, value stream stage, or process step it supports. That establishes why the service exists. A Pricing Service, for example, may support the pricing capability and serve multiple processes such as quote generation and checkout.
This traceability matters because implementation structures change more often than business intent. Services may be split, merged, or renamed, but business-aligned modeling provides a more stable reference point.
In a bank, a Card Authorization Service might support the broader Payment Authorization capability while serving both point-of-sale transactions and e-commerce checkout. Even if the bank later separates card-present and card-not-present flows into different services, the capability relationship remains stable.
Application Layer
At the application layer, the microservice is typically modeled as an Application Component that realizes one or more Application Services and exposes them through Application Interfaces. This makes service contracts explicit and separates externally visible behavior from internal structure.
This is also the layer where collaboration patterns become visible. Synchronous calls, command-style interactions, and event-based interactions should not all appear as the same generic dependency. If the model does not distinguish them, it hides the architecture instead of clarifying it.
Data Perspective
Across the application layer, the microservice should be linked to the Data Objects it owns, accesses, or publishes. In many cases, this says more about real service boundaries than the service inventory itself. If multiple services write to the same data object, the model may expose hidden coupling. If one service publishes information that many others replicate, the model clarifies where eventual consistency or schema governance becomes important.
A common example appears in IAM modernization. An organization replaces scattered local user stores with a central identity provider, but the model reveals that several services still write role data directly into shared application tables. That is not only a security issue. It shows that the intended service boundary has not actually been achieved.
Healthcare platforms often reveal a similar pattern. A Patient Administration Service may be designated as the system of record for demographic data, yet appointment, billing, and care-management services still update fragments of the same patient record in a shared database. ArchiMate makes that contradiction hard to ignore.
Technology Layer
At the technology layer, the application component is connected to its runtime environment through Artifacts, Nodes, System Software, and Technology Services. This shows where the service runs and which platform capabilities it depends on, such as container orchestration, ingress, brokers, identity, or observability.
That connection is critical because microservice autonomy is often limited by shared runtime services. A service may be logically independent while still depending operationally on the same gateway, event bus, or database platform as many others.
Strategy and Change
Where needed, the model can extend upward into strategic drivers and downward into implementation and migration. Strategic motivations such as faster release cycles, domain ownership, or regulatory isolation can justify decomposition choices. Work packages and transition architectures can then show how services are introduced, split, or retired over time.
For example, a technology lifecycle view may show a legacy API gateway marked for phase-out, with migration work packages linked to the target ingress platform and the affected services. In a regulated environment, the same view might connect a data residency requirement to the decision to split a shared customer service into region-specific deployments.
A simple test is useful here: if the model allows an architect to move from a business change to the affected services, interfaces, data, and platform dependencies, it is doing meaningful architectural work.
Modeling Service Interactions, APIs, and Event-Driven Communication
Once microservices are mapped across layers, the next step is to model how they interact. In distributed systems, architectural risk often appears between services rather than inside them. Interaction style therefore needs to be explicit.
Synchronous APIs
For synchronous interactions, the provider exposes an Application Interface that delivers an Application Service. The consumer is shown using that interface. This makes the contract visible as a first-class architectural element.
That distinction matters because consumer dependency is usually tied to the interface, not to the provider’s internal implementation. If multiple consumers rely on a specific API contract, backward compatibility and versioning become architectural concerns. The model can then show where gateway mediation, contract testing, or consumer-specific adaptation may be needed.
A common enterprise example is a Product Catalog API consumed by web, mobile, and in-store kiosk channels. The Catalog Service may evolve internally, but if all three channels depend on the same search and pricing contract, the interface itself becomes the stable architectural element.
Event-Driven Communication
Event-driven interaction should be modeled differently because its architectural consequences differ from direct invocation. Application Events can represent domain-significant events such as Order Confirmed or Payment Authorized. The publishing service triggers the event, and subscribing services respond through their own interfaces or internal behavior.
This avoids implying direct point-to-point coupling where none exists. It also highlights the trade-off introduced by asynchronous interaction: less temporal coupling, but greater complexity in observability, consistency, and event ownership.
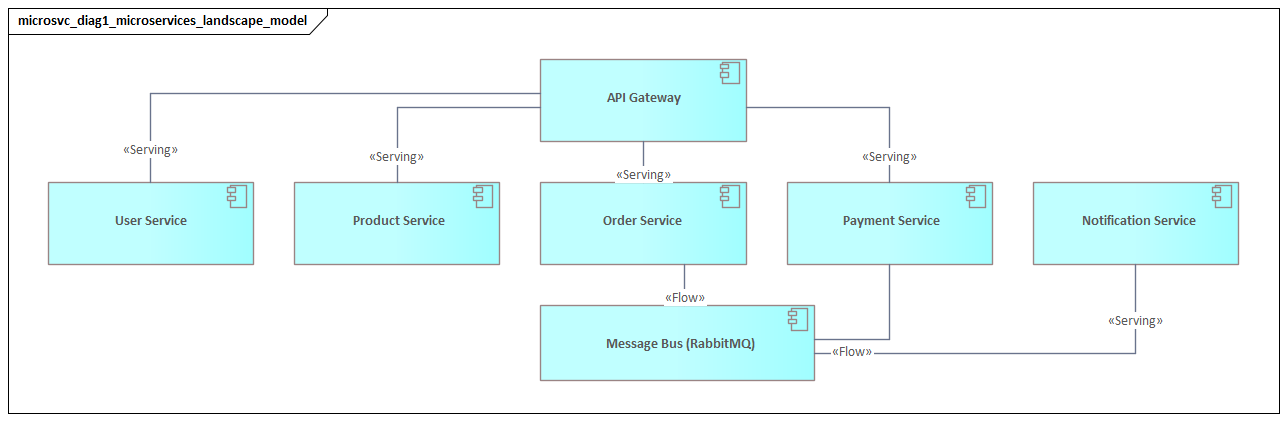
A realistic example is a Kafka-based event architecture in which the Order Service publishes Order Confirmed to a shared event platform, while Billing, Fulfillment, and Notifications subscribe independently. In ArchiMate, the event platform should appear as a technology service rather than disappearing behind abstract arrows, because retention, topic governance, and schema compatibility are part of the architecture.
Business Events vs. Technical Events
Not every message deserves equal architectural attention. Business-significant events should appear in the core model because they shape domain collaboration. Low-level retries, health notifications, or internal platform signals usually belong in supporting views unless they are operationally critical.
This selectivity keeps the model readable while preserving the interactions that matter most.
Mediation Infrastructure
Shared interaction mechanisms such as API gateways, message brokers, event streaming platforms, schema registries, and service mesh ingress should be modeled explicitly when they materially affect behavior or governance. Otherwise, the architecture can appear more decentralized than it actually is.
This is especially important in large enterprises where “direct service communication” often passes through several layers of mediation. A customer-facing API may be routed through an external gateway, an internal ingress controller, a service mesh policy layer, and centralized authentication before it ever reaches the target service. Leaving those out produces a neat diagram, but not an honest one.
Orchestration and Choreography
Where one service coordinates a multi-step flow, an Application Process or Application Function can represent orchestration. Where outcomes emerge from multiple services reacting to events, the model should show choreography through triggering relationships and event flows.
The distinction matters because orchestration and choreography create different change, resilience, and troubleshooting characteristics. An orchestrator centralizes flow logic. Choreography distributes it across the landscape.
A travel platform illustrates the difference well. A Booking Orchestrator may synchronously coordinate flight reservation, payment capture, and ticket issuance. By contrast, a loyalty points update may happen through choreography: ticket issuance emits an event, the loyalty service reacts, and the customer-notification service follows independently.
The goal is not to document every call or topic. It is to reveal the interaction patterns that shape architectural decisions: synchronous chains, enterprise-critical contracts, event propagation paths, and shared integration dependencies.
Representing Deployment, Infrastructure, and Cloud-Native Runtime Environments
The interaction model explains how services collaborate logically. The next step is to show where and how those services run. This is where many microservices models fall short. They describe service boundaries but leave out the shared runtime ecosystem that shapes resilience, scalability, and control.
Deployable Artifacts and Runtime Nodes
An Artifact can represent a deployable unit such as a container image or deployment package. That artifact is then assigned to a Node, which represents the runtime environment: a Kubernetes cluster, virtual machine, serverless platform, or managed container service.
This preserves an important distinction: the microservice is an application component, but what gets deployed is an artifact running on technology infrastructure. The same service may be deployed across multiple regions or environments without changing its logical identity.
Platform Services
System Software and Technology Services are used to represent the platform capabilities that enable runtime execution. Examples include Kubernetes, container runtimes, load balancers, API gateway platforms, service mesh components, managed brokers, and secret management services.
Modeling these explicitly matters because a service does not simply “run in the cloud.” It consumes platform capabilities such as scheduling, autoscaling, traffic routing, certificate management, logging, and secret injection. Those shared services often become enterprise-critical dependencies.
An e-commerce company may have dozens of independently deployed services, yet all of them depend on the same managed ingress controller, centralized secrets vault, and cluster logging stack. If the vault becomes unavailable, deployment pipelines fail and runtime secrets cannot be refreshed. The services are still separate, but the operational dependency is shared.
Network and Trust Boundaries
Microservices often run across multiple trust zones, regions, or hybrid environments. Communication Networks and Nodes can be used to represent virtual networks, subnets, private zones, edge environments, or cross-region links.
This is especially useful for security and compliance analysis. A deployment view that shows which services are internet-facing, which remain internal, and which cross regulated boundaries is often more valuable than a purely functional application diagram.
Shared Infrastructure and Concentration Risk
Although microservices emphasize service-level autonomy, many landscapes still depend on shared managed databases, caches, object stores, identity providers, observability stacks, and event platforms. These should be modeled explicitly because they reveal concentration risk.
This connects directly to the earlier discussion of dependencies. A set of services may appear loosely coupled at the application layer while still depending on the same database cluster, gateway plane, or identity service. If those dependencies stay hidden, the model overstates autonomy and understates operational risk.
Runtime Patterns
A mature model may also show runtime patterns that materially affect architectural decisions, such as sidecars, service mesh proxies, autoscaling groups, multi-zone deployments, or active-active regional topologies. These should be included selectively, where they influence availability, recoverability, portability, or governance.
The purpose is not to recreate infrastructure-as-code in ArchiMate. It is to expose runtime characteristics that matter for enterprise decisions.
Capturing Governance, Dependencies, and Operational Concerns
The previous sections established the core model: services tied to business intent, exposed through interfaces, interacting through APIs and events, and running on shared platforms. The final step is to represent the governance and operational conditions under which this landscape can evolve safely.
Organizational Ownership
Microservices are often described as “owned by teams,” but ownership is rarely modeled with enough precision. ArchiMate business-layer elements such as Business Actor and Business Role can show which product team, platform team, or support function owns a service, interface, or shared runtime capability.
This matters because structural dependency alone is not enough for decision-making. When an interface changes or a platform service degrades, architects also need to know who must coordinate.
A practical example is a subscription business where the Billing Product Team owns the Billing Service, but the API Gateway Platform Team owns the external exposure pattern and the IAM Team owns token validation policies. A change to invoice retrieval may therefore involve three teams even though only one application component is being modified.
Principles, Requirements, and Constraints
Governance is often expressed through shared standards: API design rules, identity integration requirements, encryption controls, data retention policies, resilience expectations, and observability obligations. These can be modeled as Principles, Requirements, and Constraints, linked to the relevant services, interfaces, or technology services.
That makes governance visible inside the architecture rather than leaving it in separate documents. It also helps identify where standards are applied intentionally and where they are uneven.
For example, an architecture board decision may require all customer-facing services to use centralized OAuth2-based authentication by a target date. Linked in the model, that decision can be traced to affected interfaces, the IAM platform, and the migration work packages needed to retire legacy LDAP dependencies.
Different Types of Dependency
A mature model should distinguish dependency types rather than treating all dependencies alike. For example:
- Functional dependency: one service needs another service’s business capability
- Data dependency: one service depends on another service’s data or event semantics
- Runtime dependency: multiple services depend on a shared platform capability
- Governance dependency: a service is constrained by shared policies or approval processes
This distinction makes impact analysis more useful. A service may be functionally independent while still sharing critical runtime or governance dependencies with many others.
Operational Capabilities
Operational concerns such as monitoring, logging, tracing, alerting, backup, secret management, and incident support should be modeled when they materially affect reliability or control. These are often represented as technology or application services.
This is important because many failures in microservices landscapes emerge from shared operational tooling rather than isolated service defects. If tracing across asynchronous flows depends on a centralized observability platform, that dependency is architecturally significant.
A financial services firm may discover during an incident review that payment processing continued correctly, but transaction support teams could not reconstruct the event trail because the shared tracing platform dropped correlation metadata. The business service remained available; the operational capability did not. That distinction belongs in the model.
Governance as Visibility, Not Bureaucracy
In microservices environments, governance should not mean centralized control over every design decision. It should mean making constraints, responsibilities, and dependencies visible enough that team autonomy does not turn into fragmentation.
The same principle applies to technology lifecycle governance. A model should show not only what is in production, but also what is tolerated, strategic, deprecated, or scheduled for retirement. A simple example is marking a self-managed Kafka cluster as transitional while new event workloads must use the managed streaming platform. This gives teams freedom within clear boundaries.
ArchiMate supports that by linking the concerns introduced throughout this article: business alignment, service boundaries, interfaces, data ownership, runtime platforms, ownership, and controls. The result is a model that reflects enterprise reality rather than an idealized picture of isolated services.
Conclusion
Modeling microservices with ArchiMate is not mainly about documenting a fashionable architectural style. It is about creating a usable representation of a distributed operating model.
Microservices distribute complexity across business domains, interfaces, data, platforms, and teams. ArchiMate helps make that complexity visible by separating concerns, showing dependencies clearly, and preserving traceability across layers. A strong model does more than list services. It explains why they exist, what behavior they expose, which data they own, how they interact, where they run, what they depend on, and who governs them.
That is why the distinctions introduced early in this article matter. The difference between application component, service, interface, data object, and runtime platform is not just modeling discipline. It is what makes later analysis meaningful. Once those distinctions are in place, architects can examine interaction patterns, reveal hidden coupling, identify concentration risk in shared platforms, and connect technical change back to business impact.
The most useful ArchiMate models are the ones that continue to help during change. They support platform reviews, service refactoring, cloud migration, resilience analysis, regulatory assessment, ownership clarification, and technology retirement decisions. In that sense, the model becomes a decision tool rather than a static description.
Used well, ArchiMate provides a coherent way to understand microservices as part of the wider enterprise system. That makes it valuable not only for communication, but for better architectural decisions over time.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business operations, information systems, and technology infrastructure. It provides a structured framework for understanding how an enterprise works today, where it needs to go, and how to manage the transition.
How is ArchiMate used in enterprise architecture practice?
ArchiMate is used as the standard modeling language in enterprise architecture practice. It enables architects to create consistent, layered models covering business capabilities, application services, data flows, and technology infrastructure — all traceable from strategic goals to implementation.
What tools are used for enterprise architecture modeling?
Common enterprise architecture modeling tools include Sparx Enterprise Architect (Sparx EA), Archi, BiZZdesign Enterprise Studio, LeanIX, and Orbus iServer. Sparx EA is widely used for its ArchiMate, UML, BPMN and SysML support combined with powerful automation and scripting capabilities.