⏱ 24 min read
Modeling Data Architecture with ArchiMate: A Practical Enterprise Guide ArchiMate training
Learn how to model data architecture with ArchiMate using clear views, relationships, and best practices to align data, applications, and business capabilities. ArchiMate tutorial for enterprise architects
Modeling Data Architecture with ArchiMate, ArchiMate data architecture, enterprise architecture modeling, data architecture framework, ArchiMate views, ArchiMate relationships, information architecture, business and application alignment, enterprise data modeling, architecture best practices ArchiMate layers explained
Introduction
Data architecture is no longer a specialist concern limited to database design. In most enterprises, it sits at the center of business performance, regulatory compliance, automation, analytics, and digital product delivery. How data is defined, governed, shared, and used now shapes operational resilience as much as application design or infrastructure choices. As organizations modernize core platforms, adopt cloud services, expand event-driven integration, and invest in AI and self-service reporting, they need a consistent way to describe data across the enterprise. ArchiMate provides that language. ArchiMate relationship types
ArchiMate is often associated with business processes, applications, and technology platforms, yet it is equally effective for modeling data across those layers. Its strength lies in showing data as an enterprise asset connected to capabilities, services, processes, applications, and platforms, rather than as an isolated catalog of tables, files, or interfaces. That broader perspective matters in large organizations, where the same business concept often appears in multiple systems under different names, ownership models, and quality standards. ArchiMate modeling best practices
This is where ArchiMate becomes especially useful. It helps architects answer practical questions that are difficult to manage in spreadsheets or purely technical diagrams. Which capabilities depend on trusted master data? Where is customer data created, transformed, and consumed? Which applications are systems of record, and which are downstream consumers? Which privacy, retention, and lineage constraints shape architecture decisions? By linking data concepts to business roles, application components, and technology services, ArchiMate makes those dependencies visible to both technical and non-technical stakeholders.
It also brings discipline to viewpoints. Data architecture is often documented separately by domain architects, solution teams, integration specialists, and governance functions, which fragments understanding. ArchiMate supports a shared model that can represent conceptual business objects, application data structures, services, flows, and supporting platforms without forcing every stakeholder to work at the same level of detail. Executives can focus on critical data domains and ownership. Architects can trace dependencies across processes and applications. Engineers can connect services and interfaces to platforms and controls.
The need becomes most apparent during transformation. Mergers, ERP replacement, IAM modernization, data platform consolidation, and regulatory remediation all have significant data implications. Without explicit modeling, organizations duplicate data, blur ownership, and carry compliance risk into new solutions. ArchiMate supports impact analysis by linking data-related elements to processes, services, constraints, and roadmaps. For example, an architecture board reviewing an IAM modernization may approve a target state in which HR remains the source of workforce identity, a cloud IAM platform provides authentication and provisioning services, and downstream applications stop maintaining local user profiles except for role-specific preferences.
The purpose of this article is not simply to show how to draw data entities in ArchiMate. It is to explain how to model data architecture as part of enterprise design: clarifying meaning, ownership, lifecycle, and dependency so the enterprise can make better decisions and manage change with less ambiguity.
Why Data Architecture Matters in Enterprise Architecture
Enterprise architecture is fundamentally about coherence: aligning business design, applications, technology, and change initiatives so they evolve in a coordinated way. Data architecture matters because data is one of the few assets created in one part of the enterprise and reused across many others, often far beyond the purpose for which it was originally captured. A process may be local to one function, and an application may serve one department, but data routinely crosses organizational, functional, and technical boundaries. That makes it an enterprise concern by definition.
A common mistake is to treat data as a by-product of applications rather than as a design domain in its own right. When that happens, each system defines its own structures, semantics, and quality rules independently. The result is familiar: duplicated customer records, inconsistent product definitions, conflicting reports, brittle integrations, and expensive reconciliation work. These are not isolated technical defects. They are symptoms of an operating model in which information is not governed as a shared asset.
Data architecture provides the structure needed to address that fragmentation. It defines which data domains matter, where authoritative sources are located, how information is exchanged, and which controls apply to quality, privacy, retention, and use. That foundation enables decisions that would otherwise be made in isolation. A new digital channel, for example, is not just an application initiative; it depends on whether customer identity, consent, pricing, and order data are consistently available across channels. A cloud migration is not only a hosting change; it also raises questions about residency, replication, lineage, and integration patterns.
The value lies in making these dependencies visible across layers. Shared platforms, APIs, analytics environments, and automation initiatives all depend on stable and well-understood data. If core business objects are poorly defined, service orientation remains superficial because each service still carries hidden semantic differences. If ownership is unclear, governance cannot prioritize remediation or approve change effectively. If lineage is unknown, reporting, AI models, and regulatory submissions become difficult to trust.
Data architecture also helps balance local autonomy with enterprise control. Business units and product teams need flexibility to move quickly and use fit-for-purpose tools. Without enterprise-level data principles, that flexibility quickly turns into silos. Good enterprise architecture does not require every team to use identical data models or platforms. It establishes the minimum shared structures needed for interoperability, traceability, and governance: common business concepts, master data responsibilities, metadata standards, and rules for exposing and consuming data through services or events.
In practice, this means data concerns should surface early in capability planning, target-state design, and transition roadmaps. Architects should ask not only which applications support a capability, but which data is essential to operating it, who owns that data, how quality is measured, and what dependencies exist between operational and analytical use. Those questions expose transformation risks before they become delivery problems. An architecture board, for instance, may decide that no new customer-facing application can go live until it consumes the enterprise customer identifier rather than creating its own.
Core ArchiMate Concepts for Modeling Data Architecture
ArchiMate’s strength is that it does not isolate data into a separate architectural silo. Instead, it represents data through structural, behavioral, and motivation elements spread across the business, application, and technology layers. That allows architects to show not only what data exists, but how it is used, who is responsible for it, which services expose it, and which platforms store or transport it.
Business-layer concepts
At the business layer, the most important data-oriented concept is the Business Object. A Business Object represents information with business meaning, such as Customer, Product, Policy, Claim, or Invoice. It is not a table, message, or file. It is the business-level concept the enterprise cares about. That distinction matters because many implementation artifacts may correspond to the same underlying concept. Modeling Business Objects establishes a common vocabulary before the discussion moves into system-specific structures.
Other business-layer elements provide the surrounding context:
- Business Process shows how information is created, validated, or used in operations.
- Business Service shows the externally visible business behavior enabled by that information.
- Business Role or Business Actor helps identify responsibility and stewardship.
Together, these elements make ownership and lifecycle visible. In many enterprises, data problems stem less from storage design than from unclear accountability for creation, validation, and change.
Application-layer concepts
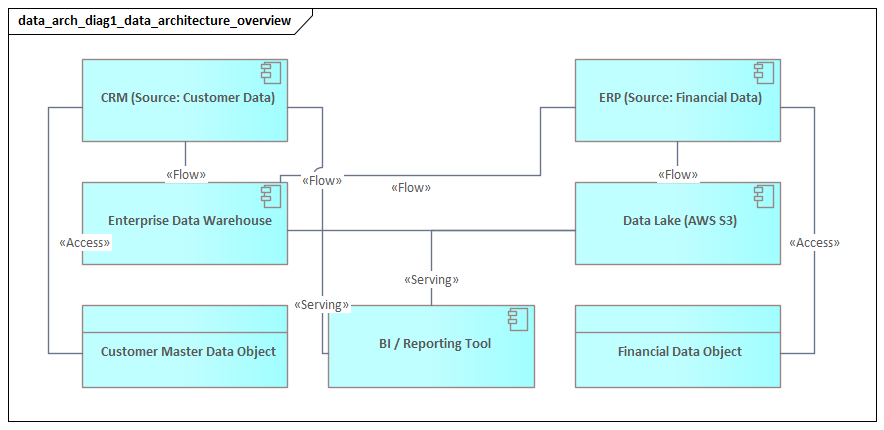
At the application layer, the central concept is the Data Object. A Data Object represents data suitable for automated processing, such as Customer Record, Product Master Entry, or Order Transaction. Unlike a Business Object, which captures business meaning, a Data Object reflects how information is handled by applications. Several Data Objects may realize a single Business Object, which allows architects to show duplication, specialization, or fragmentation across systems.
Two other application concepts are especially important:
- Application Component identifies the system or application responsible for creating, maintaining, publishing, or consuming data.
- Application Service shows the functionality through which data is exposed or managed, such as retrieval, validation, synchronization, or event publication.
These relationships are central when identifying systems of record, downstream consumers, and integration responsibilities. In an IAM modernization, for example, the HR platform may own the Worker data object, the IAM platform may provide Identity Provisioning and Authentication services, and business applications may consume identity attributes without becoming systems of record themselves.
A retail example makes the distinction clearer. The business may define a single Product Business Object, while applications handle it through different Data Objects: Product Master Record in ERP, Web Catalog Item in e-commerce, and Store Assortment Entry in point-of-sale systems. The concept is shared; the representations are not. ArchiMate helps make that difference explicit.
Relationships that matter for data
Relationships are what turn isolated elements into architecture:
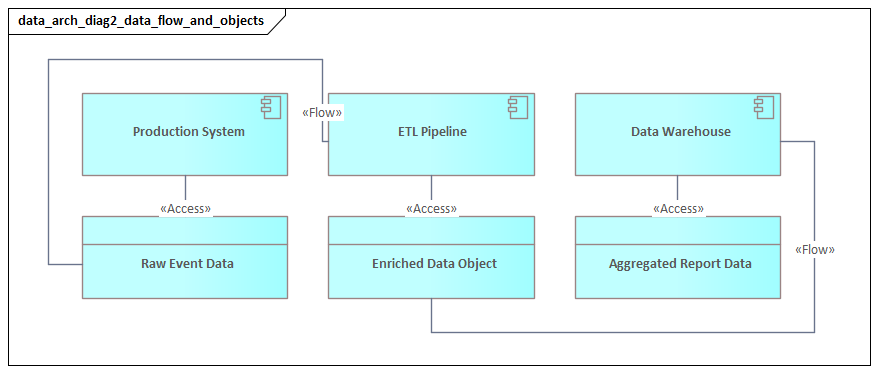
- Access shows whether a process, service, or application reads, writes, or updates a Business Object or Data Object.
- Flow indicates movement of information between processes, applications, or services.
- Realization helps connect business meaning to application implementation.
- Association, Aggregation, Composition, and Specialization support structural modeling of related concepts.
Used carefully, these relationships make it possible to distinguish authoritative sources from consumers, identify synchronization dependencies, and show where semantic divergence exists.
Technology and motivation concepts
At the technology layer, architects often use Node, System Software, Technology Service, and Artifact to show where data is stored, processed, or transported. This becomes important when data architecture must address encryption, backup, residency, resilience, or platform standardization.
Motivation elements complete the picture. Principles, Requirements, Constraints, and Assessments can be linked directly to data-related elements. A privacy rule, retention requirement, quality target, or master data principle can therefore be represented as part of the architecture model rather than left in separate policy documents. The same applies to technology lifecycle governance: a principle such as “do not introduce new workloads on end-of-life integration middleware” can be linked to affected services, applications, and transition plans.
Together, these concepts provide the foundation for the rest of the article. The following sections build on them to show how ArchiMate can represent structure, alignment, lifecycle, governance, and communication.
Representing Data Objects, Relationships, and Structure
With the core concepts in place, the next challenge is modeling data structure at the right level. ArchiMate is not a substitute for entity-relationship diagrams, canonical schemas, or physical database design. Its role is architectural: to show which information structures matter, how they relate, where boundaries exist, and why those structures affect enterprise change.
Start with the right level of abstraction
A useful place to begin is the conceptual level. Architects often start with a small number of high-value Business Objects such as Customer, Product, Contract, Asset, or Employee. Relationships between them can be modeled using Association, Aggregation, Composition, or Specialization. For example:
- Contract associated with Customer
- Order composed of Order Lines
- Individual Customer specialized from Customer
This reveals the structural logic of the enterprise without dropping into implementation detail.
That approach is especially valuable when similar terms are used differently across the organization. One business unit may use Account to mean a financial relationship, while another uses it to mean a digital access profile. By modeling those distinctions explicitly, architects reduce ambiguity in mergers, platform standardization, and reporting initiatives.
Connect conceptual meaning to application representation
At the application layer, the same concepts can appear as Data Objects such as Customer Master Record, Product Catalog Entry, or Invoice Transaction. The distinction between Business Object and Data Object is one of the most important in data architecture modeling. It allows the architect to show that a single business concept may be realized differently by multiple systems.
This is where architectural insight starts to emerge. If one Business Object is realized by several incompatible Data Objects, the model exposes semantic fragmentation. If several Application Components write to the same Data Object type, the model highlights potential ownership conflicts. If reporting depends on data assembled from loosely related sources, the model helps explain why reconciliation effort is high.
Consider a bank integrating a newly acquired lender. Both organizations manage a Customer Business Object, but one core platform stores Party, another stores Borrower, and a CRM platform stores Client Profile. All three may partially realize the same business concept. A simple ArchiMate view can show that overlap, identify the intended system of record, and make the remediation path visible before integration work begins.
Use domains and groupings
Another practical technique is to organize data by domain before modeling by application. Domains such as Customer Data, Product Data, Finance Data, and Risk Data can be shown as groupings containing related Business Objects or Data Objects. This helps communicate scope, ownership, and reuse boundaries. It also makes duplication visible at portfolio level. Five applications that independently maintain customer-related data may look acceptable in separate solution diagrams, but grouped in one domain view they reveal a broader architectural issue.
Focus on what is architecturally significant
Not all data deserves the same modeling depth. Master and reference data usually merit explicit structural modeling because they are widely reused and often require governance. Transactional and event data can be modeled more selectively, focusing on objects that matter for integration, auditability, or analytics. For example, in a Kafka-based event architecture, architects may model CustomerCreated and OrderShipped as significant event-related data objects because they drive downstream fulfillment, notifications, and analytics, while leaving internal topic schemas to implementation teams.
The goal is not completeness. It is visibility into structural risk: duplication, overlap, semantic inconsistency, lineage complexity, and unclear boundaries. Modeled this way, structure becomes a decision aid rather than just documentation.
Aligning Data Architecture with Business Capabilities, Processes, and Applications
A data model becomes far more useful when it is connected to the operating model. Without that alignment, it may describe what data exists but not why it matters or where weaknesses create business risk. ArchiMate addresses this by linking data-related elements to capabilities, processes, and applications.
Capability-centered modeling
A useful starting point is the business capability. Capabilities such as Customer Management, Order Fulfillment, Risk Management, Claims Handling, or Financial Reporting depend on specific information being accurate, timely, and accessible. By relating capabilities to Business Objects, Business Processes, and Application Services, architects can show that data quality or ownership issues are not merely technical defects; they directly constrain business performance.
This also helps identify which data domains are strategically important. Not every domain requires the same level of governance. Data that underpins many high-value capabilities, or data essential for compliance and customer experience, should be modeled as a shared enterprise dependency. If Customer data supports onboarding, billing, service management, marketing, and regulatory reporting, fragmented ownership across applications becomes an enterprise issue rather than a local system problem.
Process alignment
Processes show how data is created, validated, enriched, and consumed over time. A capability may depend on trusted data, but processes reveal where that trust is established or where it breaks down. For example, a Loan Approval process may read Customer, Income, and Risk Assessment information while creating Approval Decision data for downstream servicing and reporting.
By linking processes to Access relationships and application support, architects can identify manual re-entry, duplicated validation, or uncontrolled transformations. Those are often the real causes of enterprise inconsistency, even when the data structures themselves appear reasonable.
A healthcare example illustrates the point. A Patient Registration process may create core patient demographics in an admissions system, while a Care Delivery process enriches the same patient context in an electronic medical record. If billing later relies on a separate insurance verification process that rekeys patient identifiers, the model will expose the handoff risk more clearly than an application landscape diagram alone.
Application alignment
Applications clarify implementation responsibility. Application Components and Application Services are essential for showing which system creates, updates, publishes, or consumes each Data Object. In practice, this is often the most important issue in enterprise architecture: not the absence of data, but the absence of clarity about which system is authoritative for which information.
When several applications maintain the same data needed by the same capability, the model exposes overlap and governance weakness. When a process depends on data from a system not designed for timely access, the model reveals an operational bottleneck. These insights are particularly useful in ERP modernization, platform consolidation, and domain redesign.
Why this alignment matters
This alignment supports better prioritization. Enterprises rarely have the capacity to fix every data issue at once. By linking data concerns to capabilities and processes, architects can separate issues that are merely inconvenient from those that materially affect strategic outcomes. The model helps justify remediation in business terms.
That is what turns data architecture from a descriptive inventory into a planning tool: it shows where data dependency affects business capability, process performance, and application design at the same time.
Modeling Data Lifecycle, Governance, and Quality
Once structure and alignment are visible, the next step is to model how data changes over time and what controls govern it. Data architecture is not only about what data exists, but also about ownership, dependency, and accountability. Lifecycle, governance, and quality make those concerns operational.
Modeling the data lifecycle
The same data object often passes through multiple states during its existence. Customer data may be captured during onboarding, validated during compliance checks, enriched through service interactions, shared with downstream platforms, archived after inactivity, and eventually deleted under retention rules. ArchiMate can represent this by linking Business Processes, Application Processes, Events, and Data Objects.
The aim is not to document every state change. It is to highlight the transitions where responsibility, status, or control changes in meaningful ways. A Customer Record moving from prospective to active to dormant may trigger different access rules, quality checks, and retention obligations. Lifecycle modeling becomes especially useful during transformation because many failures occur at handoff points: migration, replication, reporting extracts, archival, or deletion.
A practical example is employee onboarding and offboarding. HR may create the initial Worker record, the IAM platform may derive digital identity attributes, payroll may enrich employment status, and downstream SaaS applications may retain local copies for authorization or audit. When an employee leaves, retention and deletion obligations differ by system. A lifecycle view can make those obligations visible and identify where deprovisioning or archival controls are incomplete.
Representing governance
Governance can be made explicit by connecting data-related elements to Principles, Requirements, Constraints, and responsible Roles or Actors. For example:
- A principle such as “customer data must have a single accountable owner”
- A constraint such as “personal data must remain within approved jurisdictions”
- A requirement for auditability, retention, consent enforcement, or classification
Linking these directly to Business Objects, Data Objects, Application Services, or Technology Services makes governance traceable. Instead of being implied by policy documents, it becomes part of the architecture.
This is particularly useful for clarifying the difference between business ownership and technical custody. A platform team may host a data store, while a business role remains accountable for meaning, policy, and acceptable use. Making that distinction visible reduces confusion in delivery and governance forums. It also gives architecture boards a firmer basis for decision-making—for example, approving a customer-data API only after a named business steward, retention rule, and quality threshold are attached to it.
Modeling quality as an architectural concern
ArchiMate does not replace profiling tools or detailed data quality rules, but it can represent quality in architectural terms through Assessments, Goals, and Requirements. An assessment might identify inconsistent supplier data across procurement and finance systems. That can be linked to a goal such as improving reporting accuracy and to requirements for standard identifiers, validation services, or master data controls.
The most useful quality models focus on points of enterprise dependency. Data used in regulatory reporting, cross-channel customer interactions, or shared analytics should be marked where quality failures would have broad consequences. This allows architects to prioritize control points such as validation services, reference data management, metadata capture, and authoritative publication mechanisms.
Taken together, lifecycle, governance, and quality show that trusted data does not emerge automatically from applications or platforms. It depends on managed transitions, explicit accountability, and controls designed into the architecture from the start.
Using Views and Viewpoints to Communicate Data Architecture
One of ArchiMate’s major strengths is the separation between the underlying model and the views used to communicate it. This matters especially in data architecture, where the same relationships must be explained differently to executives, architects, delivery teams, and governance bodies.
Build views for a question, not for completeness
Data architecture should not be communicated through a single “master data diagram.” Instead, architects should create focused views designed around stakeholder concerns. Examples include:
- Capability-to-data view: shows which business capabilities depend on which data domains or Business Objects
- Process-to-data view: shows where information is created, validated, handed off, or consumed
- Application cooperation view: shows which systems exchange which Data Objects and where authoritative sources sit
- Technology support view: shows the platforms, storage, and transport services supporting those flows
- Governance view: shows principles, constraints, ownership, and control points for critical data
Each view should answer a specific question: Where is this data mastered? Which capabilities depend on it? Which applications may update it? Which controls apply in transit and at rest?
Tailor the view to the audience
Executives generally need to see ownership, risk concentration, and dependency on a few critical domains. Delivery teams need application services, access relationships, and current-to-target transition impacts. Governance forums may care more about principles, constraints, and accountable roles than about process mechanics.
Because the underlying model remains coherent, these different views stay aligned. That is one of the main reasons ArchiMate works well for enterprise data architecture: it supports multiple conversations without forcing the organization into multiple disconnected models.
Use baseline, target, and transition views
In transformation work, baseline, target, and transition views are especially valuable. A baseline view can reveal current fragmentation, duplicated maintenance, and unclear ownership. A target view can show the intended simplification, such as a designated system of record or a governed domain platform. Transition views often add the most value because they show temporary coexistence: which interfaces remain, which data is synchronized during migration, and where risk must be managed until the target state is reached.
A short example is technology lifecycle governance. A baseline view may show several applications still dependent on an end-of-support ETL product. The target view replaces it with managed integration and streaming services. The transition view then shows which data feeds move first, which remain temporarily bridged, and where risk acceptance is required.
Connect layers in the same view when needed
Layered views are often the most powerful. A business-only view may hide implementation constraints, while a technical-only view may obscure why the data matters. A layered ArchiMate view can show that a regulatory reporting capability depends on a Business Object, which is realized by several application Data Objects, which in turn rely on integration and storage services governed by specific constraints. This kind of traceability is highly effective in architecture reviews because it connects business dependency directly to design consequence.
Used well, viewpoints turn complex data relationships into focused architectural narratives that stakeholders can understand and act on.
Practical Patterns, Pitfalls, and Best Practices
Once an organization starts modeling data architecture in ArchiMate, the main challenge is usually not notation. It is deciding how to model data in a way that is useful, maintainable, and credible to both business and technical stakeholders. A few recurring patterns and pitfalls are worth calling out.
Practical patterns
1. System-of-record pattern
Make explicit which Application Component is authoritative for a given Data Object, which services expose it, and which downstream applications consume it. This is one of the clearest ways to model ownership and dependency.
2. Publish-subscribe pattern
Show where an application creates or updates a Data Object and publishes changes to multiple consumers. This is essential in event-driven environments where copies of data proliferate quickly. A realistic example is an order platform publishing OrderCreated and OrderShipped events to Kafka, with billing, warehouse, and customer-notification services consuming them independently.
3. Data domain pattern
Group related objects into domains such as customer, product, finance, or asset data, then map those domains to ownership, capabilities, and major platforms. This is often more useful for enterprise planning than purely interface-centered diagrams.
4. Control-point pattern
Highlight services, roles, and constraints that act as control points for privacy-sensitive, financially significant, or regulated data. This shows whether governance is embedded in the architecture or left as a manual afterthought.
Common pitfalls
Too technical
A frequent mistake is to treat ArchiMate as a simplified database modeling tool and fill diagrams with entity-level detail, attributes, or schema-like relationships. That reduces clarity and makes models hard to maintain.
Too abstract
The opposite mistake is to stay so conceptual that the model cannot support decisions about migration, ownership, or integration. A useful model sits between those extremes.
Confusing Business Objects and Data Objects
Collapsing business meaning and application representation into one concept hides semantic divergence across systems. That is especially risky in post-merger environments and major modernization programs.
Modeling movement without responsibility
Many diagrams show that data moves but not who owns its definition, who may change it, or which platform is accountable for quality. Without responsibility, the model describes connectivity but not architecture.
Best practices
- Start with a clear modeling question.
- Keep each view limited to the detail needed to answer that question.
- Use names consistently, especially where business concepts and system-specific data objects differ.
- Model only data that matters architecturally: shared, regulated, high-value, or transformation-critical.
- Validate models with both business and delivery stakeholders.
- Reuse the same underlying concepts across multiple viewpoints so communication stays consistent.
In practice, the best models are not the most complete. They are the ones that make trade-offs, risks, and responsibilities visible early enough to improve decisions.
Conclusion
Modeling data architecture with ArchiMate is most valuable when it turns implicit assumptions into explicit design choices. Data problems usually persist not because organizations lack databases, integration tools, or governance policies, but because the relationships between meaning, ownership, usage, and implementation remain unclear. ArchiMate gives architects a disciplined way to expose those relationships and discuss them across business, delivery, and governance communities.
As this article has shown, the key is not merely to represent data objects, but to connect them to capabilities, processes, applications, platforms, and constraints. Business Objects establish shared meaning. Data Objects show application realization. Access and Flow relationships reveal usage and movement. Motivation elements make governance and quality visible. Viewpoints then present those relationships in forms different stakeholders can use.
ArchiMate does not solve data architecture by itself. It makes data architecture governable. Once critical domains, dependencies, responsibilities, and controls are visible in a shared model, the enterprise can make better decisions about standardization, modernization, platform investment, and risk treatment. That matters most in environments where data is distributed across SaaS platforms, legacy systems, analytics estates, and event streams.
The practical test of the model is straightforward: does it improve change outcomes? Can it show which data must be stabilized before an ERP rollout, where duplicated mastering will undermine customer experience, which IAM attributes should remain centrally governed, or which controls must be built into a new event platform from the start? If it can, then it is doing meaningful architectural work.
Used thoughtfully, ArchiMate makes data architecture part of mainstream enterprise design rather than a specialist side activity. It supports clearer alignment, stronger accountability, and better transformation decisions across the enterprise.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business operations, information systems, and technology infrastructure. It provides a structured framework for understanding how an enterprise works today, where it needs to go, and how to manage the transition.
How is ArchiMate used in enterprise architecture practice?
ArchiMate is used as the standard modeling language in enterprise architecture practice. It enables architects to create consistent, layered models covering business capabilities, application services, data flows, and technology infrastructure — all traceable from strategic goals to implementation.
What tools are used for enterprise architecture modeling?
Common enterprise architecture modeling tools include Sparx Enterprise Architect (Sparx EA), Archi, BiZZdesign Enterprise Studio, LeanIX, and Orbus iServer. Sparx EA is widely used for its ArchiMate, UML, BPMN and SysML support combined with powerful automation and scripting capabilities.