⏱ 27 min read
ArchiMate Modeling Challenges in Large Enterprises: Real Examples
Explore the biggest ArchiMate modeling challenges in large enterprises, including complexity, stakeholder alignment, governance, tool limitations, and scalability, with real-world examples and practical insights. ArchiMate training courses
ArchiMate modeling challenges, ArchiMate large enterprise, enterprise architecture modeling, ArchiMate examples, ArchiMate governance, ArchiMate complexity, stakeholder alignment, architecture repository, EA modeling best practices, ArchiMate scalability Sparx EA best practices
Introduction
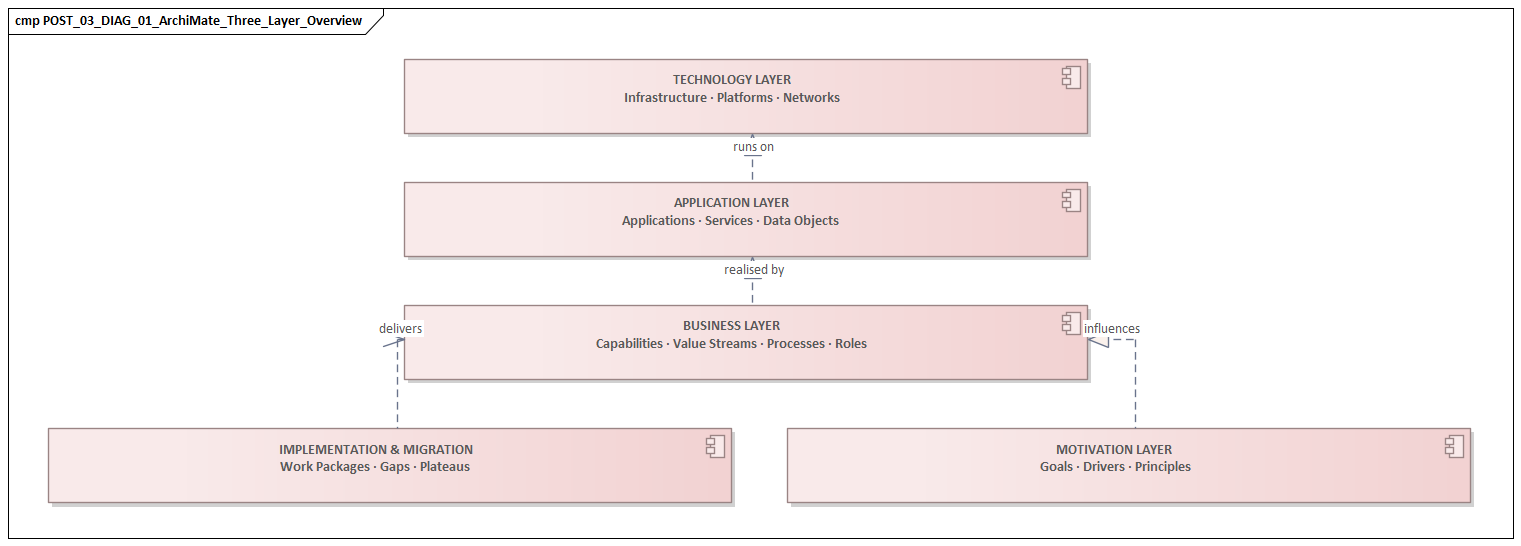
ArchiMate gives enterprises a shared language for describing strategy, business operations, applications, technology, and change in one connected model. In large organizations, that promise is attractive because complexity is never just technical. It is organizational, financial, regulatory, and political. A global enterprise may run hundreds of applications, support different operating models by region, maintain several generations of technology platforms, and execute transformation programs that run for years. In that setting, architecture teams use ArchiMate for more than diagrams. They use it to connect business intent, delivery choices, dependencies, and outcomes. how architecture review boards use Sparx EA
The harder part is rarely the notation. The real questions are practical: what should be modeled, at what level, for which audience, and under what governance? ArchiMate can represent capabilities, processes, applications, data, infrastructure, and transition states. But if teams use different definitions, naming rules, and decomposition levels, the result is a repository that is formally valid and operationally unreliable. The issue is not whether ArchiMate can describe complexity. It is whether the enterprise can apply it consistently enough to support decisions. ArchiMate tutorial
That problem becomes sharper in large organizations because architecture content is created by many groups with different goals. Central EA teams, business architects, domain architects, solution architects, platform teams, and program architects all view the enterprise through different lenses. A capability such as “Customer Management” may mean one thing in one region and something narrower in another. Even the term “application” shifts by audience: a product suite to business stakeholders, a deployable system to solution architects, or a collection of services to engineering teams. Unless those differences are reconciled through conventions, ownership, and review, the model stops being a dependable reference point. Sparx EA training
For that reason, successful ArchiMate use in large enterprises depends less on mastering symbols than on building an operating discipline around the model. The repository must be selective enough to remain maintainable, standardized enough to support comparison, and flexible enough to reflect local reality. It also has to answer concrete questions: where applications overlap, which capabilities depend on aging platforms, how transformation initiatives interact, and what transition states introduce risk. In one post-merger environment, for example, an architecture board needed a clear model of whether two regional IAM platforms should be retained, consolidated, or retired. In another, a platform review asked whether a new Kafka backbone should be treated as a strategic enterprise standard or left as a project-specific integration choice.
The sections that follow examine the most common challenges that appear when ArchiMate is used at enterprise scale. These are not edge cases. They recur in mergers, ERP transformations, cloud migrations, regulatory programs, and operating model redesigns. Across those settings, success with ArchiMate depends on five linked capabilities: clear modeling intent, balanced standardization, disciplined viewpoint design, reliable integration with enterprise data sources, and governance that keeps the model current during change.
1. Why ArchiMate Becomes Difficult at Enterprise Scale
ArchiMate becomes harder in large enterprises because scale introduces not only more elements, but more competing versions of reality. In a smaller environment, a few architects can usually align informally. They know the landscape, naming disputes stay manageable, and diagrams are created for immediate use. At enterprise scale, that breaks down. The model is no longer a communication aid for one team. It becomes a shared reference for portfolio management, transformation planning, risk review, solution design, and governance. Once several decision processes depend on it, inconsistency stops being annoying and starts becoming structural.
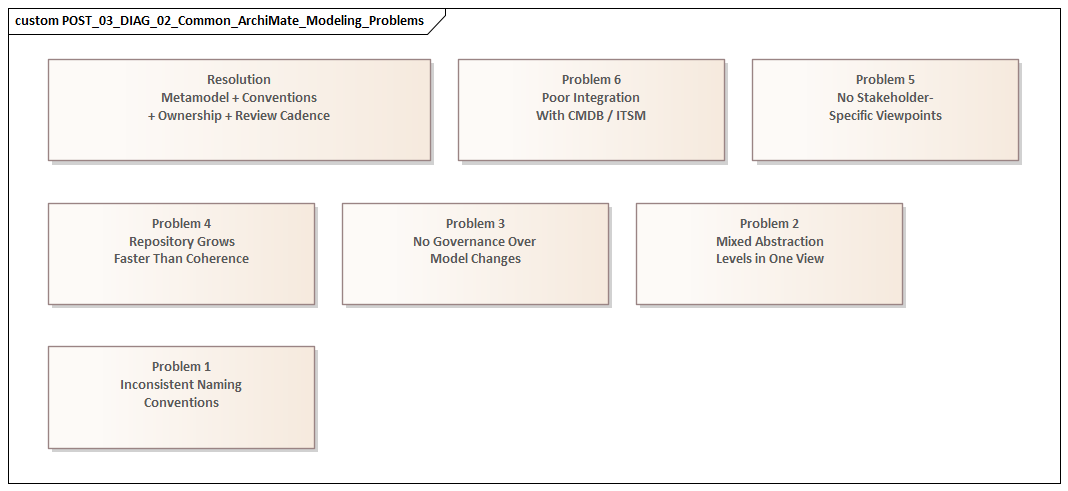
A common problem is that repositories grow faster than they become coherent. Large organizations often begin modeling in response to specific initiatives: cloud migration, ERP replacement, compliance remediation, merger integration, or application rationalization. Each initiative produces useful content for its own purpose, but over time the repository starts to reflect the history of projects more than an intentional enterprise metamodel. Coverage becomes uneven. One domain may be modeled in depth because it was a transformation priority, while shared services, integration dependencies, or regional variations remain vague. The repository can look comprehensive and still fail when used for analysis.
Scale also multiplies viewpoint demand. Different stakeholders ask different questions of the same model. A CIO wants to see which capabilities depend on end-of-life platforms. A domain architect wants to identify duplicate applications. A program manager wants transition dependencies. A security team wants to know which processes rely on systems handling regulated data. An IAM modernization lead may want to see which business services still depend on legacy LDAP directories and where workforce and customer identity are improperly entangled. ArchiMate can support all of those concerns, but only if the model is built around the questions it needs to answer. Repositories designed element-first rather than use-case-first often become rich in diagrams and poor in decisions.
Another difficulty is managing multiple decomposition levels at once. In a global bank, “Payments” may appear as an enterprise capability, a value stream stage, an operational process group, and a set of application services and integration components. None of those views is wrong. The challenge is keeping the relationships between them explicit so stakeholders can move from strategic intent to implementation impact without crossing semantic gaps. When those mappings are weak, traceability collapses. The same pattern appears in event-driven architecture. “Order Fulfilment” may be modeled as a business process, while Kafka topics, producers, and consumers sit at a lower implementation level. If the relationship between the business event and the technical event stream is unclear, impact analysis quickly becomes guesswork.
Federation makes all of this harder. Large enterprises rarely operate with one architecture team that has complete authority. More often, they have central EA, domain architects, solution teams, platform groups, and regional architecture functions. Each group has valid local concerns and, often, its own modeling habits. Without strong conventions, the same concept gets represented differently across domains. Those differences are not cosmetic. They affect impact analysis, rationalization counts, and investment decisions directly.
Then there is the maintenance problem. A model can be built centrally, but it cannot stay accurate centrally. Operating reality changes too quickly: products are retired, integrations are redesigned, platforms move to cloud services, and transformation roadmaps slip. The key question is not “Can we model this?” but “Who keeps this true, and through which governance event?” If ownership is unclear, ArchiMate turns into a snapshot archive instead of a living decision asset.
These scale effects shape everything that follows. The next sections look at how enterprises respond through standardization, viewpoint discipline, integration, model maintenance, and governance.
2. Balancing Standardization and Local Flexibility Across Business Units
At scale, the central tension is not expressive power but consistency. That is why the balance between enterprise standardization and business-unit autonomy is one of the most persistent challenges in ArchiMate practice.
Standardization matters because the model must support comparison, aggregation, and governance across the enterprise. Local flexibility matters because business units often operate under different market conditions, regulatory regimes, product structures, and delivery models. If the enterprise imposes a rigid modeling approach, local teams may reject the repository as detached from reality. If every unit models in its own way, enterprise views lose coherence.
This tension is especially visible in diversified organizations. A global insurer, for example, may have life, health, and property divisions with different process structures, distribution channels, and application landscapes. All three may use concepts such as customer, policy, claim, and partner, yet the meaning and decomposition of those concepts can vary in ways that matter. A central EA team may need a common capability map and application taxonomy for investment planning. Local architects may resist because the abstraction hides distinctions that matter for compliance or operations. Both positions are valid.
In practice, the most durable answer is a layered convention model rather than a single rigid standard. The enterprise should standardize the concepts required for cross-enterprise decisions: capability definitions, application lifecycle states, ownership rules, critical business services, major data domains, and a core set of relationship patterns. Around that core, business units should have controlled freedom to extend the model with local specializations and deeper decomposition. The enterprise might define “Customer Onboarding” as a common capability, while each region models its own process variants, controls, and supporting systems below that level. Likewise, the enterprise may define one standard technology lifecycle vocabulary—strategic, tolerable, containment, retirement—while local teams classify products against it based on actual usage and risk.
This works because enterprise-wide questions require standardized semantics, while local execution often requires richer detail. The mistake is trying to force both into the same abstraction layer.
Two failure patterns appear repeatedly.
The first is over-standardization. Central teams sometimes design elegant metamodels with many mandatory element types, naming rules, and relationship constraints in the hope of improving consistency. Adoption then slows because the method is too heavy for delivery work. Local teams fall back on spreadsheets or informal diagrams because the official repository cannot represent what they need quickly enough. The enterprise gains formal control and loses architectural truth.
The second is uncontrolled local modeling. Teams are told simply to “use ArchiMate” but are given too few guardrails. One business unit models products as business objects, another as business services, and another as value stream outputs. Each choice may make sense locally, but enterprise analysis becomes distorted. Rationalization counts lose credibility, capability heatmaps cannot be compared, and transformation dependencies disappear behind inconsistent abstractions.
A more effective response is governance by question rather than governance by notation purity. Architects should identify which questions must be answered consistently across business units:
- Where do we have duplicated applications?
- Which capabilities depend on strategic or aging platforms?
- Which processes are affected by regulatory change?
- Which transformation initiatives touch the same operating areas?
Those questions define the minimum standardization baseline. Beyond that baseline, variation should be allowed only when it improves decision quality. If an architecture board wants to decide whether to consolidate three IAM products into one strategic platform, the enterprise needs a consistent way to model identity services, consuming applications, lifecycle state, and ownership. It does not need every region to model user provisioning workflows at identical depth.
Reference patterns usually work better than exhaustive rulebooks. Common patterns for shared services, regional variants, SaaS platforms, outsourced operations, and ERP domains give teams a recognizable structure while still allowing local realism. The same applies to event architecture. A reference pattern for domain events, Kafka topics, publishers, subscribers, and integration ownership can create comparability across teams without forcing every stream-processing design into one template.
In short, the goal is not one universal model. It is one enterprise language with controlled dialects. That same principle carries into the next challenge, because without it, viewpoint sprawl follows quickly.
3. Managing Model Complexity, Viewpoint Proliferation, and Stakeholder Readability
Once an enterprise has established some consistency, a new problem usually appears: the repository becomes too rich to consume. In large organizations, ArchiMate rarely fails because there are too few diagrams. More often, it fails because there are too many—too many partial viewpoints, too many one-off representations, and too many versions of the same landscape created for different audiences and initiatives.
This usually starts for good reasons. An ERP program needs a target-state application cooperation view. A rationalization initiative needs a capability-to-application map. A cloud migration needs transition architecture views. A compliance program needs process-support and data-handling views. An IAM modernization program may need one view for executive decisions on platform consolidation and another for engineers planning federation, MFA rollout, and directory retirement. Each request is justified. The issue is that the number of views grows faster than the organization’s ability to curate them. Different architects create similar diagrams with slightly different scope boundaries, naming choices, and abstraction levels. Stakeholders then find themselves facing multiple “official” views of the same domain.
As argued earlier, standardization should be driven by decision need. The same is true for viewpoint design. A view should exist because it answers a specific question for a specific audience, not because the repository makes it easy to generate another diagram.
Viewpoint proliferation becomes especially damaging when diagrams are treated as deliverables rather than expressions of a coherent underlying model. Teams then optimize for presentation instead of reuse. A steering committee view may simplify relationships for clarity. A domain architect may add technical granularity for impact analysis. A business architect may use business-friendly labels that do not align with repository objects. Each choice is understandable. But when those views are not anchored to shared elements and explicit viewpoint rules, readability for one audience creates ambiguity for another.
At the center of this is a practical tension: readability versus fidelity. Executives do not need to see every application component, interface, and technology node involved in customer onboarding. Delivery teams, on the other hand, cannot plan migration sequencing from an executive heatmap. One view rarely serves both purposes well. Large enterprises therefore need deliberate viewpoint stratification—separate but connected views for strategic, operational, and implementation concerns.
A useful operating discipline is to treat viewpoints as products. Every recurring view should have:
- a defined question it answers
- a named audience
- a declared level of granularity
- clear source elements from the underlying model
- an expected shelf life
For example, a portfolio view may show capabilities, business services, and applications only. A transition planning view may include work packages, plateaus, and dependencies. A technical risk view may show technology lifecycle status and infrastructure services while omitting process decomposition. A Kafka architecture view may show event domains, topics, producers, consumers, and ownership boundaries, while hiding broker clusters and deployment detail unless the audience is a platform engineering forum.
Readability also depends on visual governance. ArchiMate is expressive, but stakeholder comprehension often depends on conventions beyond the notation itself: color use, edge minimization, layering, labels, and limits on what can appear in one view. Without visual standards, enterprises produce diagrams that are formally correct yet cognitively unusable. If a model has to be explained live by an architect every time it appears in a meeting, it is not truly readable.
A simple micro-example illustrates the point. In one retail transformation, the architecture team produced a single “order-to-cash” view containing capabilities, processes, applications, APIs, integration middleware, cloud services, and migration work packages. It was accurate, but nobody used it. The team split it into three linked views: an executive capability-impact map, a domain application-dependency view, and a transition sequencing view for the program office. The underlying model changed very little; the usefulness of the architecture changed dramatically.
The principle remains the same: one underlying model, many disciplined views. Stakeholders should be able to move from concise executive views to more detailed domain and solution views without encountering contradictory semantics. If they cannot move between levels of detail with confidence, the model is not functioning as a shared reference.
This challenge leads directly to the next one. Once a repository supports many useful views, pressure grows to populate it with data from CMDBs, process repositories, and portfolio tools. Without viewpoint discipline, those integrations often add more noise than value. free Sparx EA maturity assessment
4. Integrating ArchiMate with CMDBs, Process Repositories, and Other Enterprise Data Sources
In large enterprises, ArchiMate rarely succeeds as a standalone modeling effort. Its long-term value depends on how well it connects to the operational systems that already describe parts of the enterprise: CMDBs, application portfolios, process repositories, data catalogs, identity directories, project portfolios, and technology lifecycle inventories. But integration helps only when semantics are controlled. Otherwise, it simply scales inconsistency.
The architecture repository is often expected to provide coherence across these sources. That is difficult because those systems were built for different purposes, governed by different teams, and maintained at different levels of rigor. The challenge is not just technical integration. It is semantic alignment.
A CMDB is the most common example. Infrastructure and operations teams may treat it as the source of truth for servers, environments, hosts, middleware, and sometimes business applications or services. But CMDB structures are usually optimized for service management and operational support, not enterprise architecture analysis. A CI such as “SAP-PRD-ECC” may be perfectly useful for incident and change control, yet it does not map neatly into ArchiMate without interpretation. Is it an application component, a deployment of system software, a node, or shorthand for an entire production stack? If architects import CMDB content directly, the repository fills with operational detail that obscures architecture relationships. If they ignore the CMDB, they lose an important source of deployment truth.
Process repositories create a different problem. BPMN tools, control libraries, and process documentation systems often contain workflow detail that is richer than ArchiMate should carry. They may model task-level logic, exception handling, and procedural controls in ways that are essential for operations but too granular for enterprise-wide architecture. The practical question is what to synchronize and what to leave in specialist tooling. In most large enterprises, ArchiMate works best when it references process structures at the level needed for cross-domain traceability—major processes, business services, ownership, and dependencies—while procedural depth remains outside the repository.
The same pattern appears with application portfolio tools and data governance platforms. Portfolio systems may hold lifecycle status, vendor information, support ownership, cost data, and risk ratings. Data catalogs may define systems of record, data domains, stewardship assignments, and regulatory classifications. Identity repositories may hold directory ownership, authentication patterns, and federation relationships. These sources are valuable, but only if the enterprise defines canonical mappings. What exactly is the relationship between an “application” in the portfolio tool and an ArchiMate application component? Does a data domain map to a business object, a data object, or an external classification object? Is an Azure AD tenant represented as a technology service, a system software environment, or part of an identity platform? Without explicit mapping decisions, integration creates false precision: dashboards look complete, but the underlying semantics are unstable.
The principles from the earlier sections become practical here. Integration should support the standardized concepts that drive enterprise decisions, and it should enrich the viewpoints stakeholders actually use. It should not try to replicate every source system inside the architecture repository.
A practical way to scope integration is to start from decision scenarios. If the enterprise needs to assess which critical business services depend on end-of-life technology, then the priority is to connect business services, applications, technology elements, and lifecycle data. If the goal is regulatory impact analysis, then process ownership, application support, data classification, and control mappings may matter more than deep infrastructure synchronization. If the goal is event architecture governance, then the useful integration may be between the repository and Kafka topic catalogs, API gateways, and application ownership records rather than the full CMDB. Integration scope should follow governance use cases because every additional source increases reconciliation cost.
A realistic micro-example helps. In one manufacturing group, the EA team imported the full CMDB into the architecture repository to improve “traceability.” The result was thousands of infrastructure items with weak business linkage and almost no increase in decision value. The approach was reset. Instead of importing everything, the team synchronized only production application instances, hosting patterns, lifecycle status, and ownership for systems supporting critical business services. That smaller integration was easier to govern and far more useful in technology risk reviews.
Ownership is usually the hardest part. Source systems often have local custodians, uneven data quality, and update cycles that do not align with architecture governance. An integrated repository remains trustworthy only when each imported attribute has a defined steward, refresh mechanism, and conflict rule. Mature enterprises do not try to make architects the owners of all source data. Instead, they treat ArchiMate as the semantic integration layer: not the place where every fact originates, but the place where enterprise meaning is assembled and related.
That distinction becomes critical during transformation. If integrated data cannot be kept current as initiatives evolve, the model quickly loses credibility. That leads directly to the next challenge.
5. Keeping Large-Scale ArchiMate Models Current in Fast-Changing Transformation Programs
Large enterprises often discover that architecture models age fastest during transformation. The reason is simple: transformation programs change scope, sequencing, ownership, funding assumptions, vendor choices, and technical dependencies all at once. A model that was accurate at the start of a planning cycle can become misleading within weeks if a migration wave slips, a platform decision changes, or an interim integration pattern is introduced.
This is especially visible in multi-year initiatives such as ERP replacement, post-merger integration, cloud migration, and core platform modernization. These programs are often presented with a clean story: baseline, transition architectures, and target state. In practice, execution is messier. Legacy systems remain longer than expected, temporary interfaces become semi-permanent, business units negotiate exceptions, and implementation waves diverge by region. If the repository reflects only the approved target architecture, it quickly stops representing the enterprise that delivery teams are actually changing.
That problem grows when the repository integrates data from other systems. Imported lifecycle statuses, deployment information, and ownership attributes are useful only if they remain aligned with program reality. Otherwise, integration gives the appearance of control while hiding drift.
A common failure pattern is to treat model maintenance as a documentation task performed after delivery milestones. By the time updates are made, the program has already moved on. The repository becomes useful for retrospective explanation but weak for dependency management. In fast-moving transformations, architecture content has to be updated through the delivery lifecycle itself. Changes to ownership, interfaces, deployment states, capability impacts, and work package dependencies need to be captured as part of governance events such as design approvals, release planning, cutover readiness, and decommissioning decisions.
Another recurring issue is under-modeling transition states. Enterprises are usually comfortable describing the current state and the future state, but they are less disciplined in representing the temporary states in between. Yet those intermediate states are where most delivery risk sits. A bank migrating payments may run old and new services in parallel, introduce temporary data replication, and maintain dual reporting for regulatory reasons. A retailer replacing order management may keep legacy fulfillment integrations active for only part of the network. An IAM modernization program may retain a legacy directory for workforce authentication while customer-facing applications move to a cloud identity provider, creating a coexistence state that matters for support and security. These temporary conditions affect cost, resilience, support complexity, and sequencing. If ArchiMate models do not represent plateaus, work packages, and coexistence periods clearly, transformation planning becomes detached from operational reality.
One healthcare example makes this concrete. During an EHR integration program, the target architecture assumed a single patient identity service. In reality, the acquired clinics continued using a local master patient index for nine months because data-cleansing work ran late. The architecture repository initially showed only the target state, which meant dependency analysis missed the temporary need for dual identity reconciliation and added support controls. Once the transition state was modeled explicitly, the program was able to plan the required interfaces, support ownership, and decommissioning sequence more realistically.
The practical solution is to make model currency a governed outcome of change rather than a voluntary cleanup activity. Each major program should define:
- which elements must be updated at which decision points
- who is accountable for each update
- what evidence is required to confirm the change
- how planned, approved, implemented, and retired states are distinguished
For example, a design approval may establish target relationships, a release milestone may confirm actual deployment status, and an exit review may validate decommissioned interfaces and retired components. A technology review board may also require a lifecycle update when a platform shifts from strategic to containment—for instance, when an on-premises integration broker is no longer approved for new use and Kafka becomes the preferred event backbone. This ties model maintenance to delivery events instead of relying on periodic repository refreshes.
It is also important to distinguish stable facts from volatile planning assumptions. Not every roadmap dependency deserves equal status in the model. Architects should explicitly mark what is current, what is approved, what is forecast, and what is retired. Without that discipline, stakeholders begin to read planned relationships as if they were current truth.
Model freshness is ultimately a credibility issue. If delivery leaders learn that the repository is consistently behind reality, they stop using it for planning. If, by contrast, the model reflects current transition conditions well enough to support sequencing, risk review, and investment decisions, ArchiMate becomes more than a design language. It becomes a working control instrument for enterprise change.
That final step depends on more than method. It depends on governance, tooling, and adoption, which is where many large-enterprise efforts succeed or fail.
6. Governance, Tooling, and Adoption Challenges in Practice
In large enterprises, ArchiMate problems often become most visible not in modeling workshops but in governance forums, tool rollouts, and day-to-day adoption. By this point, the pattern should be clear: notation is rarely the limiting factor. The surrounding operating model is.
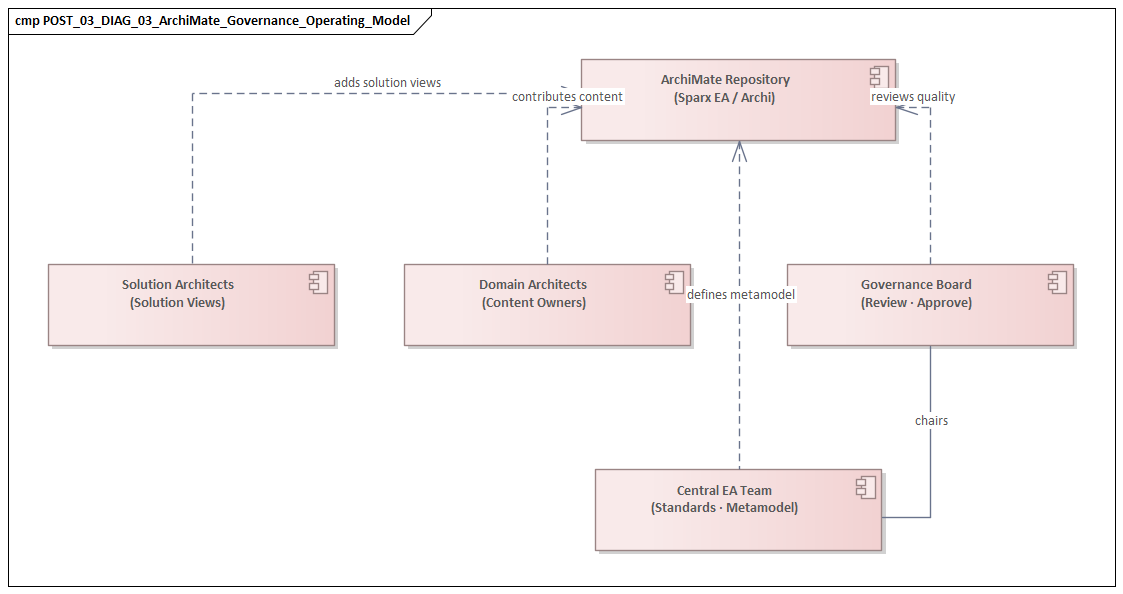
Governance is the first test. In merger environments, for example, a combined enterprise may launch an architecture assessment to identify duplicative capabilities, overlapping applications, and integration risks. ArchiMate may be introduced as the common language for consolidation planning. But each legacy organization brings its own approval processes, architecture boards, and definitions of what counts as authoritative. One side may treat architecture artifacts as decision records tied to investment governance; the other may treat them as optional design documents. The result is predictable: diagrams are produced, but no one agrees on which model drives funding, decommissioning, or platform standardization decisions. The issue is not model quality. It is the absence of governance authority around the model.
A realistic example is an architecture board deciding to standardize on one IAM platform and retire two regional tools within eighteen months. Unless that decision is reflected in lifecycle state, transition architecture, funding controls, and delivery checkpoints, the repository remains descriptive rather than directive. The model may show intent, but the enterprise will continue funding exceptions.
Tooling is the second test. Enterprises often select repository platforms because they support ArchiMate, workflow, and integration. Yet user experience frequently becomes a barrier. A central team may expect domain architects, solution architects, and analysts to contribute directly in the tool, only to discover that it is too slow, too rigid, or too specialized for broad use. Architects continue to sketch in PowerPoint, Visio, or whiteboarding tools because those are faster in working sessions. The repository is updated later—if at all. This creates a split between working architecture and record architecture. Once that split becomes normal, trust in the repository starts to erode.
Role clarity is the third test. In federated organizations, enterprise architects, regional architects, and program architects often share the same repository but work to different incentives. Enterprise architects want consistency and traceability. Regional architects want the model to reflect operational reality. Program architects want speed and enough flexibility to support delivery options. Without a clear RACI, the same application or business service gets edited by multiple parties, ownership becomes contested, and review cycles turn into negotiation sessions. The repository then reflects organizational politics as much as enterprise structure.
Adoption is the fourth test, and often the hardest. Business stakeholders may support architecture modeling when it is tied to a major transformation, but interest fades quickly if the outputs feel abstract or slow to influence decisions. One practical sign of weak adoption is when executives ask for architecture insight and receive custom slide decks rather than repository-generated views. Another is when delivery teams treat ArchiMate as a compliance obligation rather than a planning aid. In that environment, updates become minimal and defensive. By contrast, adoption strengthens when teams see direct value: a technology lifecycle review uses the model to show that twelve customer-facing services still depend on an out-of-support web server stack, or a Kafka governance forum uses it to identify duplicate event streams for the same customer update event.
The lessons from the earlier sections come together here:
- From Section 1: the model must answer real governance questions.
- From Section 2: standardization must focus on decision-critical concepts.
- From Section 3: viewpoints must be disciplined and audience-specific.
- From Section 4: integration must strengthen semantics, not merely aggregate data.
- From Section 5: model maintenance must be tied to change events.
When those conditions are in place, governance, tooling, and adoption reinforce one another. Governance gives the model authority. Tooling makes contribution and retrieval practical. Adoption grows because stakeholders can see the model influencing funding, sequencing, risk, and operational decisions.
When they are absent, the opposite happens. Governance remains ambiguous, tooling is bypassed, and the repository becomes a secondary record rather than a decision instrument. Large enterprises do not fail with ArchiMate because they cannot draw the right diagram. They fail because the model is disconnected from authority, too cumbersome to maintain, or too weakly embedded in the way the enterprise actually changes.
Conclusion
ArchiMate can be highly effective in large enterprises, but its value depends far more on operating discipline than on notation alone. The language is capable of linking strategy to execution, yet that value appears only when the enterprise treats modeling as part of how it governs change.
The main challenge at scale is coherence. Large enterprises generate competing truths, uneven coverage, and federated ownership. The response is not to model everything. It is to define a small set of decision-critical concepts and maintain them consistently. That is why the balance described in Section 2 matters: standardize what the enterprise must compare and govern, while allowing controlled local depth where operational reality requires it.
The same logic applies to consumption. Section 3 showed that a useful repository is not the one with the most diagrams, but the one with disciplined viewpoints tied to stakeholder questions. Section 4 extended that principle to integration: external data sources should enrich the model where they improve enterprise decisions, not flood it with unmanaged detail. Section 5 then made clear that none of this matters if the model cannot stay current during transformation. In fast-changing programs, model maintenance must be built into governance events, not left as cleanup work.
Taken together, these points lead to a practical conclusion: enterprises should judge ArchiMate adoption by behavior, not by repository size. If program boards challenge roadmaps using architecture evidence, if domain teams use the model to expose overlap and risk, if transition decisions trigger updates automatically, and if stakeholders trust the repository enough to move from strategy to implementation, then ArchiMate is working as intended.
Large-enterprise modeling is therefore a long-term capability, not a one-time implementation. The organizations that succeed are the ones that model selectively, standardize deliberately, integrate carefully, and govern continuously. ArchiMate does not remove complexity. It makes complexity visible and manageable—provided the model stays anchored to real decisions, real ownership, and real change.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business processes, information systems, and technology. It provides a structured approach to understanding the current state, defining the target state, and managing the transition — using frameworks like TOGAF and modeling languages like ArchiMate.
How does ArchiMate support enterprise transformation?
ArchiMate supports transformation by modeling baseline and target architectures across business, application, and technology layers. The Implementation and Migration layer enables architects to define transition plateaus, work packages, and migration events — creating a traceable roadmap from strategy through to implementation.
What tools are used for enterprise architecture modeling?
The most widely used tools are Sparx Enterprise Architect (ArchiMate, UML, BPMN, SysML), Archi (ArchiMate-only, free), and BiZZdesign Enterprise Studio. Sparx EA is the most feature-rich — supporting concurrent repositories, automated reporting, scripting, and integration with delivery tools like Jira and Azure DevOps.