⏱ 24 min read
Managing Multi-Team Collaboration in Sparx EA: Governance, Version Control, and Best Practices Sparx EA training
Learn how to manage multi-team collaboration in Sparx EA with effective governance, shared repositories, version control, security, and modeling best practices for enterprise architecture teams. Sparx EA best practices
Managing Multi-Team Collaboration in Sparx EA, Sparx EA collaboration, Enterprise Architect multi-user modeling, Sparx EA version control, shared repository Sparx EA, Sparx EA governance, model security in Sparx EA, team-based modeling, enterprise architecture collaboration, Sparx EA best practices Sparx EA guide
Introduction
As enterprise architecture matures, the hardest problem is rarely creating individual models. The harder task is enabling many teams to work in a shared repository without losing consistency, traceability, or confidence in what the repository actually represents. In Sparx Enterprise Architect, that challenge becomes very visible because business architects, solution architects, application owners, integration specialists, data teams, and governance functions often work in parallel on connected content.
This is not only a tooling issue. It is an operating model issue. A central repository does not, by itself, create collaboration. Teams need clear ownership boundaries, review responsibilities, lifecycle rules, and modelling conventions. Without those controls, local habits fill the gap: content is duplicated instead of reused, diagrams drift away from their underlying elements, and stakeholders begin to question which view is authoritative. Over time, the repository stops functioning as a shared architectural knowledge base and starts to resemble a loose collection of team-specific models.
Part of the difficulty comes from the way different teams work. Enterprise architecture teams usually maintain long-lived structures such as capabilities, target-state platforms, and shared taxonomies. Delivery and solution teams move faster, concentrating on projects, interfaces, deployments, and transition designs. Both perspectives matter, but they place very different demands on governance and repository design. If everything is tightly controlled, teams avoid the repository and work elsewhere. If everything is open, consistency and trust erode.
A more workable approach is to treat multi-team collaboration as the design of a managed shared workspace. That means deciding which content is authoritative, which areas support working design, who owns each type of element, how changes are reviewed, and how local work is promoted into shared enterprise views. It also means accepting that different parts of the repository need different controls. Shared reference models and reusable building blocks usually need stronger stewardship than team-local working packages.
This article sets out a practical structure for making that collaboration sustainable at scale. It begins with why multi-team work in Sparx EA is inherently difficult, then moves through the mechanisms that make it workable: governance and ownership, repository and security design, controlled change through baselines and version control, review and communication workflows, and the practices that preserve traceability, quality, and consistency across the shared model. Taken together, these disciplines turn Sparx EA from a modelling tool into a dependable platform for coordinated enterprise change. free Sparx EA maturity assessment
Why Multi-Team Collaboration in Sparx EA Is Challenging
The central challenge in Sparx EA is that many teams are editing a shared set of architectural facts, not simply drawing their own diagrams. A local change—renaming an application component, reclassifying an interface, or moving an element into a different package—can affect reports, roadmaps, dependency views, and governance outputs used far beyond the originating team. Because that downstream impact is often indirect, teams do not always see the consequences immediately.
Sparx EA also offers considerable modelling flexibility. That is one of its strengths. In a shared repository, however, the same flexibility can produce divergence. Different teams may use the same element type for different purposes, apply tagged values inconsistently, or interpret naming standards in their own way. Each team may still feel it is modelling sensibly within its own context, yet the cumulative effect is weaker comparability and lower trust across the repository.
The problem becomes more pronounced when teams work at different levels of abstraction. Enterprise architects typically model stable structures such as capabilities, value streams, standards, and target states. Solution and delivery teams focus on nearer-term concerns such as projects, interfaces, deployments, and transition architectures. Unless those layers are connected deliberately, the repository starts to split. Strategic content becomes too abstract to guide delivery, while delivery content becomes too detailed to support enterprise decisions.
Ownership is another recurring source of friction. In theory, domains may have named owners. In practice, related content often cuts across several teams. An application team may own an application record, while integration teams update interfaces, data teams maintain information objects, and governance teams rely on the same content for assessments. Without explicit stewardship, shared areas become places where many teams can edit but no one really curates.
Cadence adds another complication. Strategic reference models may change quarterly, project designs weekly, and operational metadata almost continuously. Treating all content as though it needs the same review and control model usually leads to one of two results: delay or instability. Effective collaboration depends on recognising from the outset that different repository areas need different levels of stewardship.
Quality issues are also cumulative. A repository rarely fails in one dramatic moment. More often, it becomes progressively harder to navigate, harder to reuse, and harder to trust. Teams respond with side documents, spreadsheets, and duplicate packages, which weakens the repository further. A familiar example is the application catalogue: one domain updates lifecycle status on the master application element, another creates a duplicate application in a project area to show a migration, and six months later portfolio reporting shows two conflicting retirement dates for the same system. The real challenge, then, is not simply enabling concurrent access. It is ensuring that decentralised contribution still results in one coherent architectural system.
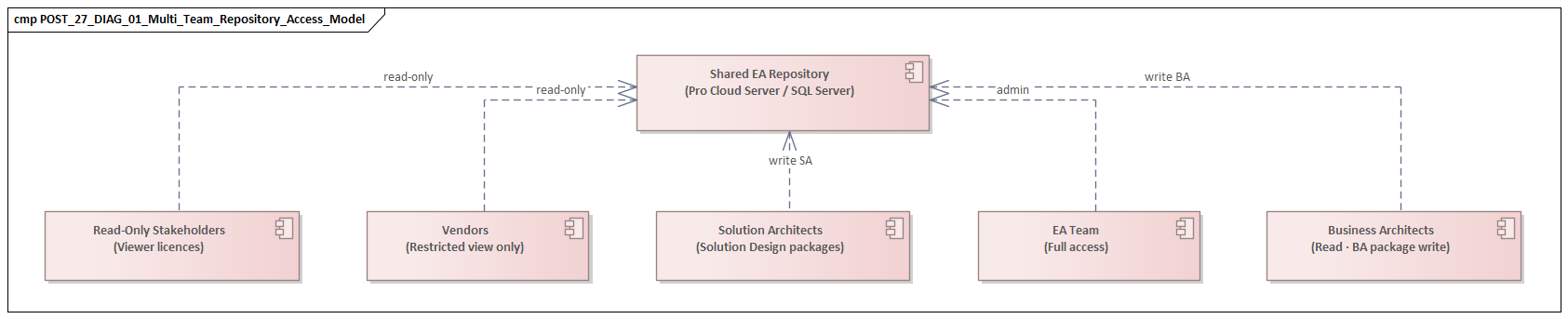
Establishing Governance, Roles, and Ownership Across Teams
Because the problem is structural, the first response has to be governance. Sustainable collaboration in Sparx EA starts with explicit decisions about who can change what, under which conditions, and with what level of review. Broad statements such as “enterprise architecture owns the standards” or “domains maintain their models” are not enough. Teams need an operational ownership model that works at package, element, relationship, and lifecycle level. how architecture review boards use Sparx EA
A useful distinction is between content ownership, metamodel ownership, and repository administration.
- Content ownership sits with the teams accountable for the meaning and lifecycle of architectural information. Application owners may own application records, data teams may own canonical information concepts, and platform teams may own technology building blocks.
- Metamodel ownership defines valid modelling patterns, stereotypes, tagged values, and naming conventions. This usually sits with an enterprise architecture or architecture governance function.
- Repository administration covers security groups, package controls, Pro Cloud Server configuration, versioning mechanisms, and operational support.
Keeping these roles separate avoids a common confusion: owning the tool is not the same as owning the modelling rules, and neither is the same as owning the architectural content itself.
Governance works best when ownership is assigned where decisions are actually made. Department-level ownership is usually too vague for day-to-day modelling. It is more effective to map repository zones to named steward roles. Shared reference packages—such as enterprise capabilities, glossary terms, standard integration patterns, and core technology components—should have clear custodians. Team-specific working areas can be more flexible, but they still need an accountable lead who decides when content is mature enough to be promoted into shared views.
That creates an important distinction, one that runs through the rest of this article, between authoring areas and controlled reuse areas. Authoring areas support local design and iteration. Controlled reuse areas hold content that multiple teams depend on and therefore require stronger stewardship.
A RACI-style approach can help, but it needs to be adapted to modelling work. The practical questions are these:
- Who may create new elements?
- Who may change core properties?
- Who approves structural changes?
- Who can deprecate or retire content?
- Who must be consulted when relationships cross domain boundaries?
For example, a solution architect may model a new interface in a working area, but the owning application team may need to approve its association to an application service, while the integration architecture function checks alignment with standard patterns. In another case, a domain team may propose a new customer data object for a digital onboarding initiative, but the enterprise data steward may be required to confirm whether the concept already exists in the canonical model before it can be promoted into shared reference content.
Governance should also reflect how the organisation actually operates. If teams are federated, the repository should support delegated stewardship within clear guardrails. If some domains are heavily regulated or architecturally sensitive, those packages should have tighter controls. The aim is not uniform governance. It is governance proportionate to risk, reuse impact, and rate of change.
Lifecycle ownership matters just as much as creation rights. Teams should know who can mark content as draft, approved, deprecated, retired, or replaced, and what evidence each state change requires. Without that clarity, repositories accumulate obsolete artefacts that remain visible but no longer reflect reality. A simple example is technology lifecycle governance: a platform team may mark Oracle 12c as deprecated, but only after the standards owner has recorded the approved replacement version and the architecture board has agreed the retirement timeline.
Governance becomes credible only when it is visible in the repository itself. Package permissions, naming rules, status fields, review workflows, dashboards, and reporting should all reinforce the ownership model. If governance exists only in policy documents, teams will fall back into local habits. When it is embedded in Sparx EA, collaboration becomes far more predictable and scalable. fixing Sparx EA performance problems
Structuring Repositories, Packages, and Security for Scalable Collaboration
Once governance and ownership are defined, they need to be translated into repository structure. In Sparx EA, repository design is not administrative housekeeping. Root nodes, package hierarchies, and permissions shape how easily teams can find content, understand boundaries, and collaborate safely. A weak structure encourages duplication and accidental interference. A strong one makes the operating model visible.
A scalable repository is usually organised by purpose rather than by organisational chart alone. In practice, four broad zones work well:
- Shared reference content
Stable artefacts reused across teams, such as business capabilities, application catalogues, standard integration patterns, and core information concepts.
- Domain-owned architecture
Content maintained by accountable teams within agreed stewardship boundaries.
- Solution or initiative working areas
Flexible spaces for active design, impact analysis, and transition modelling before content is promoted.
- Published viewpoints and reporting packages
Curated views used for governance forums, portfolio reporting, and stakeholder consumption.
This structure reinforces the distinction between authoring areas and controlled reuse areas introduced earlier. Not all packages should behave in the same way. Shared reference content benefits from tighter edit rights, stronger review, and clearer lifecycle control. Working areas should support faster iteration, but they must not become permanent substitutes for governed architecture.
A common failure pattern is to let project teams build complete parallel structures in isolated areas and then never reconcile them with the enterprise repository. The result is apparent completeness but multiple competing truths. To avoid that, package design should support a clear promotion path: teams model locally, review against shared standards, and then promote approved content into controlled reuse areas.
Repository structure should also reflect how people consume architecture. Architects may think in domains, but many users navigate by business question: Which applications support this capability? Which interfaces expose this service? Which information objects are shared across processes? If package structures are too deep, too technical, or inconsistent between domains, users stop navigating and start asking for exports. A scalable repository therefore needs to balance stewardship boundaries with discoverability.
Security should reinforce this structure, not compensate for poor design. Teams need:
- write access where they are expected to maintain content,
- read access where they need visibility,
- restricted access only where uncontrolled change would create significant risk.
Overly broad write permissions destabilise shared content. Overly restrictive controls push teams into offline modelling and delayed updates. The goal is selective control aligned with stewardship responsibilities.
It is useful to think in terms of change surfaces. Some packages have high downstream impact because many diagrams, reports, or integrations depend on them. Those packages need stronger protection, baseline discipline, and more formal review before structural changes are made. Other areas carry lower enterprise risk and can support more direct team editing. This risk-based approach is usually more practical than applying the same controls everywhere. For example, an enterprise IAM reference package containing identity domains, authentication patterns, and privileged access controls should normally be more tightly governed than a project package exploring a temporary onboarding workflow.
The same principle applies to security group design. A retail bank, for instance, may allow solution teams read-only access to the enterprise payments capability model, write access to their programme workspaces, and controlled update rights to the shared integration catalogue only through nominated integration stewards. That arrangement is more effective than a blanket “architects can edit everything” rule because it matches real accountability.
The repository also needs to support growth. New domains, teams, and initiatives will join over time. If adding a new domain requires major restructuring, the package model is too brittle. A scalable Sparx EA repository allows new contributors to work within clearly defined spaces, reuse shared content with confidence, and still contribute to a model that remains understandable as participation expands.
Using Baselines, Version Control, and Branching to Manage Change
Once repository zones and ownership are clear, change has to be managed explicitly. In a multi-team environment, direct editing of live shared content is rarely enough. The goal is balance: teams need room to move quickly, but the repository must still preserve reviewability, rollback options, and confidence in authoritative content. Baselines, version control, and branching provide that discipline.
Baselines
Baselines provide a snapshot of package content at a specific point in time. They are especially useful before major solution work, governance reviews, regulatory updates, or structural refactoring of shared packages. Their value is not limited to recovery. They also help teams compare current and previous states and understand exactly what changed.
As noted earlier, not all repository areas need the same level of control. Baselines are most useful where packages have significant downstream impact or where changes need careful review. Shared reference content, high-value domain models, and published architecture viewpoints are typical candidates.
Baselines work best when tied to meaningful lifecycle events rather than created arbitrarily. Examples include:
- before quarterly planning,
- before a target-state release,
- before a major programme mobilises,
- before bulk taxonomy or standards changes.
That gives each baseline business context. A repository full of unmanaged snapshots creates noise. A repository with baselines aligned to decision points creates usable architectural history.
A practical example is a core banking modernisation programme. Before the payments domain updates its target-state application map, the architecture team takes a baseline of the shared application and integration packages. During review, the team can then show exactly which interfaces are newly introduced, which legacy payment hubs are marked for retirement, and which capability-to-application mappings have changed since the previous planning cycle. That is far easier than debating changes from memory.
Version control
Version control serves a different purpose. Where baselines capture and compare states, version control supports controlled movement of package content between working and governed states. It is useful where packages require check-in and check-out behaviour, stronger auditability, or tighter coordination across distributed teams.
Typical candidates include:
- shared taxonomies,
- reusable standards,
- core reference packages,
- high-dependency architecture assets.
Version control can reduce collisions between contributors and provide a clearer record of who changed what and when. Even so, it should be used selectively. If every package is forced into the same mechanism, collaboration becomes heavier than it needs to be. Team-local exploratory modelling often does not justify that overhead.
Branching
Branching is valuable when teams need to explore significant change without destabilising the mainline architecture. This is particularly relevant for transformation programmes, mergers, platform replacements, and large process redesigns. Branches allow future-state models to diverge temporarily from the authoritative repository while teams test options, analyse impacts, and mature designs.
The main challenge with branching is not creating branches but reconciling them. Long-lived branches often become architecture silos. The longer they diverge, the harder they are to compare, align, and merge back. For that reason, branches should always have:
- a defined purpose,
- a named owner,
- a review cadence,
- a planned exit path.
They should be temporary change environments, not permanent parallel repositories. A practical example is event architecture redesign: a programme team may branch the integration domain to model Kafka topics, producers, consumers, and event contracts for a new order platform, while the controlled reuse area remains the source of truth until the target pattern is reviewed and approved.
Using the three together
A mature Sparx EA practice uses these mechanisms together:
- Baselines preserve reference points.
- Version control regulates managed updates.
- Branching provides safe space for temporary divergence.
Used together, they support the promotion path described earlier. Teams can work in authoring areas, compare changes against a known baseline, manage updates through controlled package handling where needed, and merge approved results back into controlled reuse areas without destabilising the wider repository.
The key is discipline in deciding when each mechanism applies. A small update to a team-local deployment view may need none of them. A change to the enterprise application taxonomy may justify all three: a baseline before the update, version-controlled package management during the change, and a temporary branch if several domains need to test the revised classification approach before it is adopted.
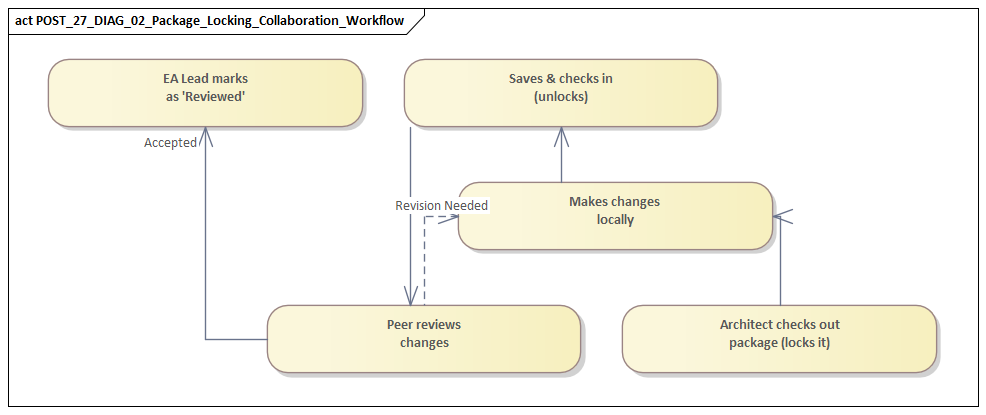
Coordinating Reviews, Approvals, and Communication Workflows
Governance, package structure, and change controls provide the framework, but collaboration still depends on how teams review and communicate changes. A repository may be well designed in principle and still fail in practice if teams do not know when to consult others, how decisions are captured, or how issues are resolved. In a shared environment, review is not just an approval gate. It is the mechanism that keeps local modelling aligned with shared meaning.
A common mistake is to treat review as a single final checkpoint. In practice, architecture content usually needs several kinds of review, each with a different purpose:
- Peer review improves modelling quality and consistency within a team or domain.
- Cross-domain review checks impact on adjacent teams, shared services, information objects, and integration patterns.
- Governance review assesses alignment with standards, target-state direction, and control requirements.
When all of that is collapsed into one generic approval step, the result is usually either superficial sign-off or unnecessary delay. As with governance intensity and package controls, review should be proportionate to architectural significance.
The trigger for review should be change significance, not routine administration. Minor diagram refinements or local clarifications may only need peer validation. Changes to shared taxonomies, core relationships, standard interfaces, or published viewpoints should trigger broader consultation. This follows directly from the earlier distinction between lower-risk authoring areas and higher-impact controlled reuse areas.
Approvals also need more nuance than simply “accepted” or “rejected.” Useful outcomes often include:
- approved,
- approved with actions,
- approved for working use only,
- approved subject to domain confirmation,
- returned for revision.
These states reflect the way architecture decisions usually mature: progressively rather than all at once. A design may be directionally sound but still require metadata updates, lifecycle clarification, or dependency validation before it becomes authoritative. For example, an IAM modernisation design might be approved for working use pending confirmation of the target identity provider, MFA standard, and ownership of legacy LDAP integrations.
Communication quality has a direct effect on review quality. Reviewers need more than an updated diagram. They need to know:
- what changed,
- why it changed,
- what assumptions were made,
- which domains may be affected,
- what decision is being requested.
Without that context, reviews tend to focus on notation or formatting rather than architectural consequence.
In more mature environments, review and communication workflows are tied to recurring forums rather than handled entirely ad hoc. Typical examples include:
- domain architecture syncs,
- design authority meetings,
- integration review boards,
- portfolio governance sessions.
These forums are useful only when their scope is clear and their decisions are reflected back into the repository. Traceability matters. If a relationship, classification, or standard is approved in a meeting, that evidence should be visible through model status, review notes, issue logs, or linked documentation. For instance, if an architecture board approves Kafka as the strategic event backbone for internal asynchronous integration, that decision should be linked to the standard pattern, affected solution designs, and any exceptions still using point-to-point messaging.
One practical improvement is to standardise the review pack for significant changes. A short package summary, impact list, affected domains, decision request, and baseline comparison is usually enough. That avoids the common situation where reviewers are presented with a complex diagram but no explanation of what is actually under discussion.
A practical rule is to minimise reliance on memory and email trails. If a decision affects the model, the record of that decision should sit close to the model. That reduces repeated debate, improves onboarding, and makes later audits much easier.
Ultimately, review and communication workflows turn Sparx EA from a passive store of architecture into a place where shared architectural meaning is discussed, tested, and confirmed. The repository remains trustworthy not because every change is centrally controlled, but because collaboration around change is structured, visible, and repeatable.
Ensuring Traceability, Quality, and Consistency Across Shared Models
The earlier sections describe how teams should collaborate. This section focuses on how the repository remains useful once many teams are collaborating. At scale, the value of Sparx EA depends less on how much content it contains and more on whether that content can be trusted, followed, and compared. Traceability, quality, and consistency are what make the shared repository usable as an architectural system of record.
Traceability
Enterprise architecture decisions rarely stand alone. A capability is supported by applications; applications expose services and interfaces; interfaces exchange information objects; and all of these may be affected by initiatives, standards, risks, and target-state decisions. If teams model only the part directly relevant to their own work, the repository may look complete locally while still failing to explain how decisions connect across domains.
To avoid that, define a minimum set of relationships for key element types. For example, an application should not exist only as a catalogue entry. It should also connect, where appropriate, to:
- supported business capabilities,
- owning organisation,
- lifecycle status,
- technology dependencies,
- integration dependencies,
- relevant initiatives or target states.
That creates usable chains of meaning rather than isolated records. It also supports the review and impact analysis practices discussed earlier. In an IAM modernisation, for example, the target identity platform should trace not only to applications consuming SSO, but also to security standards, decommissioned directories, and projects funding the transition.
Quality
Quality is broader than notation correctness. A diagram can look tidy and still be weak if elements are poorly named, duplicated, missing mandatory metadata, or linked inconsistently to the wider repository. In a multi-team environment, quality needs to be assessed at several levels:
- element quality,
- relationship integrity,
- completeness of required properties,
- coherence of derived views and reports.
This is where validation rules, naming standards, mandatory tagged values, and regular quality checks become essential. They reduce the likelihood that each team defines “good enough” in its own way.
Quality controls are most effective when they are routine rather than exceptional. A monthly repository health check that flags orphaned interfaces, missing owners, or applications without lifecycle status is far more useful than a major clean-up exercise once a year. In practice, small recurring corrections prevent larger trust problems later.
Consistency
Consistency matters because many consumers do not inspect modelling choices in detail. They rely on searches, matrices, dashboards, impact assessments, and generated reports. If two teams represent similar concepts differently, the problem may not be obvious in a local diagram, but it appears quickly in enterprise reporting.
Consistency therefore depends on practical shared patterns for recurring scenarios, such as:
- how applications relate to capabilities,
- how interfaces are classified,
- how data entities differ from message schemas,
- how target-state elements are marked,
- how obsolete content is retired.
These patterns should be simple enough for teams to apply repeatedly without constant interpretation. Event architecture is a good example: if Kafka topics, event schemas, and consumer services are modelled differently by each programme, enterprise dependency views quickly lose value.
Another common case is cloud platform modelling. If one team models an Azure subscription as a technology node, another as a deployment environment, and a third as an application boundary, any attempt to report on platform ownership, resilience, or hosting concentration will produce misleading results. Shared patterns prevent that drift.
Fitness for use
One of the most effective ways to improve traceability, quality, and consistency is to focus on model fitness for use. The key question is not whether a package is perfect in isolation. It is whether another team can consume it without reinterpretation. Can they understand what an element represents, trust its status, follow its dependencies, and reuse it in their own work? If not, the issue is usually not a lack of detail but a lack of disciplined structure.
Duplicate content is a particularly important warning sign. Duplicate applications, interfaces, or information concepts split relationships across competing elements and make impact analysis unreliable. For that reason, repository operations should routinely include checks for:
- duplicate candidates,
- orphaned elements,
- missing mandatory relationships,
- inconsistent metadata,
- outdated lifecycle states.
These quality controls reinforce everything discussed in earlier sections. Governance defines who is accountable; repository structure defines where content belongs; change controls manage how it evolves; reviews validate significance and impact; and quality practices ensure the resulting shared model remains dependable.
Conclusion
Managing multi-team collaboration in Sparx EA is not primarily about giving many users access to one tool. It is about creating a shared architectural workspace that can absorb decentralised contribution without losing coherence. That requires a deliberate operating model: clear governance, visible ownership, repository zones aligned to purpose, proportionate security, explicit change controls, structured reviews, and ongoing quality management.
The key principle running through all of these sections is that different repository areas need different treatment. Shared reference content and controlled reuse areas need stronger stewardship because many teams depend on them. Authoring areas need more flexibility so teams can work at delivery speed. Collaboration succeeds when there is a clear path between those two modes: teams can model locally, review appropriately, and promote approved content into authoritative shared structures.
It is also important to judge success by usability rather than volume. A repository is valuable when teams can rely on it—when delivery teams can trace dependencies, governance forums can trust published views, and domain owners can maintain their areas without destabilising others. In that sense, multi-team collaboration is a capability in its own right, combining modelling discipline, operational governance, and organisational trust.
For enterprise architecture leaders, the objective is not to centralise every modelling decision. It is to create an environment in which federated teams can work independently while still producing enterprise-level clarity. When that happens, Sparx EA becomes more than a modelling platform. It becomes a durable foundation for coordinated change across the organisation.
Frequently Asked Questions
What is architecture governance in enterprise architecture?
Architecture governance is the set of practices, processes, and standards that ensure architectural decisions are consistent, traceable, and aligned to strategy. It includes an Architecture Review Board, modeling standards, lifecycle management, compliance checking, and exception handling.
How does Sparx EA support architecture governance?
Sparx EA supports governance through package-level security, model validation rules, tagged value lifecycle tracking, baseline management, and report generation. Architecture decisions, compliance status, and review outcomes can all be tracked as model elements with defined owners and statuses.
What are the key elements of an effective EA governance checklist?
An effective EA governance checklist covers: principles alignment, standards compliance, integration impact assessment, security and data classification review, requirements traceability, roadmap alignment, and operational readiness. Each gate should produce model-based evidence, not just a presentation.