⏱ 28 min read
How We Structured ArchiMate Models for a 500-Application Enterprise Landscape
Learn how we structured ArchiMate models for a 500-application enterprise landscape to improve clarity, governance, traceability, and scalable architecture management. how architecture review boards use Sparx EA
ArchiMate, enterprise architecture, ArchiMate modeling, application portfolio, enterprise landscape, architecture governance, application architecture, architecture repository, model structuring, EA best practices, large-scale architecture, 500-application landscape, architecture traceability, enterprise modeling, IT landscape management Sparx EA best practices
Introduction
Modeling an enterprise estate of roughly 500 applications is not mainly a diagramming exercise. It is a problem of structure, consistency, and control. At that scale, the question is not whether architects can produce accurate views. The real question is whether the repository remains coherent as multiple teams contribute, technologies evolve, and business priorities shift. ArchiMate gives you a strong language, but language on its own does not create a useful model. Without clear conventions, even a standards-based repository drifts toward inconsistency, uneven detail, and limited decision value.
From the outset, our objective was not comprehensive documentation. We wanted a model that could support real architectural work across portfolio planning, governance, risk management, and transformation. The repository had to answer the same practical questions repeatedly and credibly: which business capabilities are supported by which applications, where redundancy exists, which integrations create fragility, and which technologies introduce concentration risk or technical debt. It also had to serve different audiences without creating multiple versions of the truth. Architects needed formal views. Leadership needed simpler summaries. Analysts needed data they could query.
The central lesson was straightforward: usefulness depends on controlled abstraction. If applications are modeled at different levels of detail, the repository stops being analytically reliable. If every possible relationship is captured, the model fills with noise and becomes expensive to maintain. We therefore treated the ArchiMate repository as a managed information product rather than a collection of diagrams. That decision shaped the whole approach: modeling principles, level-of-detail rules, relationship constraints, repository structure, and governance.
We also learned early that enterprise landscapes do not stand still. Mergers, retirements, cloud migrations, and operating model changes continually reshape the estate. The model therefore needed stable anchors that could survive local change. In our case, those anchors were business capabilities, application services, and technology domains. They gave us a way to add, split, merge, or retire systems without repeatedly redesigning the repository itself. Sparx EA performance optimization
The rest of this article explains how we structured the model to balance rigor with usability. We begin with the realities of a 500-application landscape, then outline the principles that guided the repository, and then describe the core layers, viewpoints, and level-of-detail rules. From there, we look at how the repository was organized in practice, how portfolio mapping made it analytically useful, and which standards and reusable patterns kept it consistent at scale. We close with the main lessons and recommendations for teams facing similar complexity.
1. Enterprise Context and the Challenge of Modeling 500 Applications
A 500-application landscape is rarely the product of deliberate design. More often, it is the cumulative result of years of local optimization: business units buying tools independently, delivery teams solving immediate problems, acquisitions bringing in parallel platforms, and legacy systems surviving because they still matter operationally. By the time enterprise architects begin modeling the estate, the portfolio already reflects several generations of strategy, funding logic, and technology choices. The challenge is not just volume. It is variety.
In our case, the estate included customer-facing platforms, internal operational systems, shared enterprise services, data platforms, middleware, end-user tools, and a long tail of niche applications with limited but important business use. Some were modern SaaS products with clear APIs and vendor roadmaps. Others were custom-built systems understood well by only a small number of teams. Several systems played multiple roles at once: one platform could deliver business functionality, expose reusable services, host integrations, and act as a system of record for a domain. Any modeling approach based on neat categories started to fail as soon as it met the real portfolio.
That is why enterprise-scale modeling differs so much from documenting a smaller solution architecture. At 500 applications, small inconsistencies become systemic defects. If one team models products as application components, another as application services, and a third links business objects directly to systems, the repository may still look rich. It will not, however, support comparison or analysis. The real danger is not incompleteness. It is false consistency: a model that appears detailed and mature but whose content was captured with different meanings.
The term application adds another complication because it is unstable by nature. One team may treat a platform as a single application because it has one budget line and one owner. Another may see it as several architectural building blocks because it provides distinct services and has separate integration patterns. The reverse also happens: a set of legacy tools may be funded separately while functioning operationally as one business-critical system. Before we could define repository structure, we had to define what counted as an application in repository terms and when decomposition was warranted.
The operating model matters just as much. In a federated enterprise, architecture data comes from many contributors with different priorities and different levels of familiarity with ArchiMate. Some teams care most about process-to-application mapping. Others are focused on lifecycle risk, resilience controls, or regulatory obligations. That is precisely why controlled abstraction matters. The structure has to absorb varied needs without encouraging each contributor to invent local semantics.
Time adds another layer of complexity. In a 500-application estate, some part of the portfolio is always moving: implementations underway, systems nearing retirement, contracts awaiting renewal, integrations being redesigned, and cloud migration programs changing hosting patterns. A repository that captures only a static current-state snapshot becomes stale almost immediately. It has to distinguish baseline architecture from transition logic and planned target states. During an IAM modernization, for example, an old directory, a legacy SSO stack, and a new cloud identity platform may coexist for more than a year. If that temporary state is mixed indiscriminately into the baseline, the model becomes hard to interpret.
These realities shaped the principles in the next section. We needed a structure that could tolerate imperfect information, support progressive enrichment, and preserve comparability across the estate. That in turn influenced how we defined core entities, how we separated stable anchors from volatile detail, and how tightly we constrained relationships so the repository remained usable at enterprise scale.

2. Architecture Principles and Objectives Behind the ArchiMate Structure
Before we defined folders, viewpoints, or relationship rules, we agreed on a small set of principles to govern the model. That step was essential. Repository structure is never neutral; it reflects assumptions about what matters, what can be compared, and what decisions the model is meant to support. In a landscape of this size, those assumptions need to be explicit.
Principle 1: Model for decisions, not completeness
The repository was not intended to become an encyclopedia of the estate. Its purpose was to support recurring decisions in portfolio management, governance, risk assessment, investment planning, and transformation design. Every core element type and relationship pattern had to justify itself by helping answer a practical question. If a detail did not support analysis, governance, or impact assessment, it did not belong in the core model. free Sparx EA maturity assessment
This principle kept the repository from turning into a documentation exercise. It also influenced the level-of-detail rules described in Section 3 and the governance controls in Section 4. In practice, it meant the architecture board could use the model to make decisions such as whether to approve a second workflow platform in the same capability area or require reuse of an existing enterprise service.
Principle 2: Separate stable reference structures from volatile implementation detail
Some enterprise concepts change slowly: business capabilities, major information domains, core application services, and technology domains. Others change constantly: hosting arrangements, product versions, interface styles, project states, and temporary coexistence patterns. We structured the model so stable concepts acted as anchors while volatile details could evolve around them.
This proved to be one of the most important design choices in the whole approach. Stable anchors allowed the model to survive mergers, retirements, and migrations without repeated refactoring. They also made longitudinal analysis possible. An application could move from on-premises infrastructure to a cloud platform without breaking its capability alignment or service relationships.
Principle 3: Use ArchiMate semantically, but pragmatically
We wanted enough rigor to keep the model analytically trustworthy, but not so much theoretical purity that contribution became difficult. The practical answer was to use a constrained subset of ArchiMate consistently. Most contributors were not full-time enterprise architects. In a large estate, a smaller set of repeatable conventions is more valuable than uneven use of the full language. ArchiMate training courses
This principle shaped the approved modeling patterns described later in Section 6.
Principle 4: Preserve traceability across layers selectively
One of ArchiMate’s strengths is cross-layer traceability between business, application, data, and technology. In a large repository, though, indiscriminate cross-layer modeling creates noise very quickly. We therefore aimed for selective traceability: enough to answer dependency and impact questions, but not so much that every application became linked to every process, interface, and infrastructure node.
A realistic example came from event architecture. We modeled Kafka as a strategic integration platform and captured critical producer and consumer dependencies for high-value domains such as order management and customer notifications. We did not attempt to represent every topic, schema, and event subscription in the enterprise repository. That level of detail belonged elsewhere.
Principle 5: Make governance lightweight but enforceable
A repository of this size cannot depend on manual review of every modeling decision. We embedded governance into the structure itself through naming rules, mandatory metadata, ownership expectations, and a small set of validation checks. Governance had to be distributed, but consistency still had to be protected centrally.
This principle shaped the repository operating model outlined in Section 4.
Objectives
Taken together, these principles gave us a clear set of objectives. The repository needed to be:
- comparable across domains
- resilient to organizational and technology change
- useful to both architects and non-architect stakeholders
- capable of progressive enrichment without losing coherence
- governed through simple, repeatable controls rather than heavy review processes
With those objectives in place, the next step was to define what each modeling layer would represent and how much detail it was allowed to contain.
3. Core Modeling Layers, Viewpoints, and Level of Detail
Once the principles were in place, the next decision was how to structure model content so it remained useful across hundreds of applications. The key discipline was not merely separating the business, application, and technology layers. We also had to define what each layer was allowed to represent and at what level of detail.
Business layer: capabilities as the primary anchor
At the business layer, we centered the repository on business capabilities. We needed a stable reference structure that could survive organizational churn and shifting project priorities, and capabilities provided that stability.
We did not try to model the entire operating model, every process hierarchy, or every organizational nuance. That would have added maintenance overhead without improving enterprise-wide decision support. Instead, capabilities became the main business normalization layer, supported where necessary by selected business processes, business services, and actors.
This let the business layer answer practical questions such as:
- where application support was concentrated
- where multiple systems enabled the same capability
- where critical capabilities depended on fragile platforms
In one domain, for example, three separate tools were all mapped to the same case-management capability: a legacy workflow engine, a departmental SaaS tracker, and a custom intake portal. That capability view made the overlap visible in a way product-centric reporting had not.
Application layer: managed systems and the services they provide
At the application layer, the application component became the core managed entity because it aligned best with ownership, lifecycle management, investment decisions, and portfolio analysis. But a list of applications on its own was not enough. For architecturally important systems, we also modeled the application services they exposed or consumed.
That distinction mattered. The application component represented the managed system; the application service represented what that system provided to the rest of the enterprise. Without that separation, the repository would have remained a catalog rather than an architecture model.
It also made comparison easier. Two applications might be technically very different yet provide similar enterprise services such as identity management, document management, or case handling. This was particularly useful during IAM modernization: the old directory, SSO platform, and access governance tool were separate managed systems, but the repository made clear which identity-related services each one provided and which capabilities still depended on them.
A second example came from HR technology. One SaaS suite handled core employee records, while a separate on-premises tool managed access requests for contractors. At a system level they looked unrelated. At a service level, both were contributing to workforce identity and access services, which changed the way we assessed duplication and migration sequencing.
Technology layer: selective representation of strategic dependencies
At the technology layer, we were deliberately selective. We did not model every server, network segment, or deployment artifact. That level of detail belonged in operational tools such as CMDBs or platform engineering repositories. Instead, we modeled technology where it affected enterprise decisions: cloud platforms, major middleware products, database platforms, end-user technology domains, and critical hosting patterns.
That was enough to answer questions such as:
- which applications depended on technologies nearing end of life
- where concentration risk existed
- whether strategic platform standards were being followed
It also supported technology lifecycle governance. When a database platform moved into “contain” status, we could identify which business-critical applications still depended on it and which planned projects would extend that dependency. In one case, a claims platform looked stable from a business perspective but was still tied to an aging commercial database version that the infrastructure team was trying to exit. The technology mapping exposed a risk that portfolio summaries had previously missed.
Data and integration as cross-cutting viewpoints
Rather than modeling data and integration as exhaustive standalone domains, we treated them as cross-cutting viewpoints. We modeled data objects where they clarified business meaning, system-of-record relationships, or major transformation dependencies. We modeled integrations where they mattered for impact analysis, resilience, or governance.
This followed directly from the decision-oriented principle introduced in Section 2. In a 500-application estate, trying to capture every interface adds noise much faster than it adds value. For domains using Kafka, for instance, we represented the event backbone, key publishing applications, and critical consuming services, but not every low-level event subscription.
Level-of-detail rules
The layer structure only worked because we paired it with explicit level-of-detail rules. Every application had to meet a minimum baseline:
- owner
- lifecycle status
- business capability alignment
- key application services
- major dependencies
Beyond that baseline, additional detail was added only when justified by importance, risk, or active change. A commodity SaaS tool with limited integration might remain lightly modeled. A core transaction platform, by contrast, would include richer service decomposition, technology dependencies, and transition-state relationships.
That discipline prevented the repository from becoming uneven in ways that distorted analysis.
Standard viewpoints
Stakeholders rarely ask for “the model.” They ask for answers to specific questions. We therefore organized content around a small set of recurring viewpoints rather than producing ad hoc diagrams:
- capability-to-application maps
- application collaboration and integration views
- application-to-technology dependency views
- lifecycle and risk overlays
- transition views for transformation initiatives
These viewpoints became the practical interface to the repository. They also set up the next section, where repository organization and governance ensured those views could be generated consistently across domains.
4. Organizing the Repository: Domains, Relationships, and Governance
Once the layers and level-of-detail rules were defined, the next challenge was operational: how to organize the repository so hundreds of applications could be modeled by many contributors without the structure collapsing into inconsistency. At this scale, repository design matters as much as notation.
Domains first, diagrams second
We organized the repository around domains first and diagrams second. The primary structure was not a library of views, but a managed set of domain packages reflecting stable ownership and accountability. At the top level, we separated:
- business reference content
- application portfolio content
- technology reference content
- transformation content
Within the application area, applications were grouped by business or architectural domain rather than by vendor, project, or reporting line. That aligned with the stability principle from Section 2. Projects and organizations change often; domain boundaries usually make better long-term architectural anchors.
Within each domain, we used a consistent internal pattern:
- core application elements
- domain-specific services
- major integrations and dependencies
- domain viewpoints
That consistency reduced navigation effort and made validation easier.
Reusable objects, not diagram-only content
We required the repository to store reusable architecture objects first, with views assembled from those objects afterward. That may sound obvious, but many repositories drift toward diagram-centric modeling, where important facts exist only inside views. That approach does not scale. Reusable objects made the model queryable, comparable, and maintainable.
Relationship discipline
Relationship control mattered even more than folder structure. In large repositories, uncontrolled relationships do more damage than missing ones. We therefore limited the relationship patterns allowed in the core landscape model.
For example:
- business capabilities linked primarily to application services
- application components realized application services
- application components depended on other application or technology elements through a small approved set of relationships
- direct cross-layer links were used only where they added clear analytical value
This reinforced the selective traceability principle from Section 2 and the layer definitions from Section 3.
Structural versus contextual relationships
One of the most useful distinctions we introduced was the difference between structural and contextual relationships.
- Structural relationships represented enduring architectural facts, such as an application providing a service or depending on a database platform.
- Contextual relationships represented situation-specific logic, such as temporary coexistence during migration or a dependency within a transformation program.
Separating the two prevented short-lived project logic from polluting the baseline repository while still allowing transition planning. This distinction became especially important in portfolio and transformation analysis. It also helped the architecture board distinguish between permanent design decisions and temporary exceptions granted during delivery.
A practical example came from a CRM replacement program. In the baseline model, the customer master service was linked structurally to the incumbent CRM and the integration hub. In the transformation view, a contextual relationship showed temporary synchronization between the old CRM and the new SaaS platform during phased migration. Because we kept those relationship types distinct, the baseline remained stable while the program team could still model transition complexity.
Governance model
Governance was distributed but controlled. Each domain had model stewards responsible for content quality, while a central architecture function owned:
- metamodel conventions
- mandatory properties
- naming rules
- validation checks
We did not rely on review boards to catch every issue manually. Instead, we enforced a small set of repository controls:
- mandatory ownership
- lifecycle status
- criticality
- domain classification
- approved naming patterns
- periodic validation for orphaned elements, duplicate relationships, and missing expected links
This was governance embedded in the structure, not governance applied only after the fact.
Governance as an operating model
Most importantly, repository governance was tied to recurring enterprise processes: portfolio reviews, technology risk assessments, and transformation checkpoints. That kept the model alive. A 500-application repository remains trustworthy only when it is updated through the same processes that continuously reshape the estate. In practice, technology lifecycle governance was one of the strongest drivers. When a product moved from “strategic” to “contain” or “retire,” the repository provided the application impact list used in planning and governance.
With that operating structure in place, the repository could support richer analysis. The next section explains how capability, process, data, and technology mapping turned the model from a classified inventory into a decision instrument.
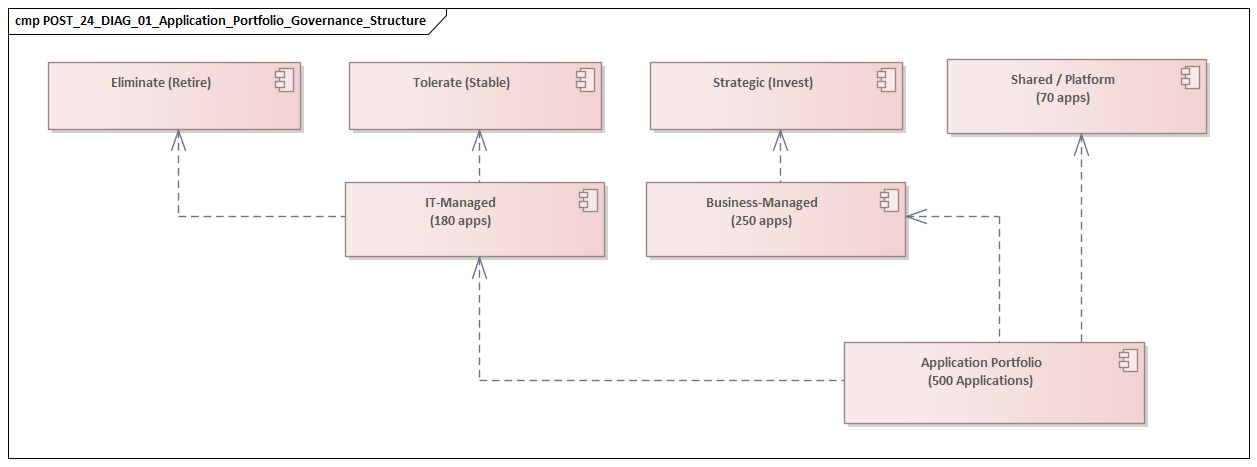
5. Application Portfolio Mapping: Capabilities, Processes, Data, and Technology
Once the repository structure stabilized, the next task was to make the application portfolio analytically useful. This was the point where the ArchiMate model stopped being an organized inventory and started becoming a decision tool. ArchiMate tutorial
Capability mapping as the normalization layer
We began with capability mapping because it provided the strongest enterprise-wide normalization layer. Applications vary widely in scope and technical style, but they can still be compared meaningfully through the capabilities they support.
That immediately made several patterns visible:
- capabilities supported by too many overlapping tools
- critical capabilities dependent on a single aging platform
- domains where strategic capabilities relied on weakly governed local systems
Capability mapping was especially effective in rationalization discussions because it shifted the conversation away from product loyalty and toward functional necessity.
Selective process mapping
Capability mapping alone was not enough. Two applications may support the same capability while playing very different roles. One may execute the process itself; another may provide workflow, reporting, or orchestration around it. To avoid flattening those distinctions, we added process relevance selectively.
We did not build a full process architecture for every domain. Instead, we mapped applications to high-value or high-variation processes where sequence, handoff, or operational dependency mattered. This revealed:
- where process fragmentation was driving application sprawl
- where multiple systems were stitched together to complete one business activity
- where modernization opportunities were really process redesign opportunities
In one operations area, four applications appeared justified when viewed separately. A process view showed that staff were manually bridging them to complete a single onboarding flow. That changed the discussion from “which tool should we replace?” to “why is one process spread across four systems?”
Data mapping and system-of-record clarity
The data dimension often turned high-level portfolio discussions into actionable roadmap discussions. In many enterprises, applications appear functionally distinct while the deeper issue is duplicated or contested ownership of business data.
We therefore mapped key applications to major data objects and identified system-of-record patterns where architecturally important. This was not a full information architecture. It was a targeted way to answer questions such as:
- which applications create or master customer data
- where product data is duplicated across platforms
- which transformations require coordinated data migration rather than simple application replacement
This became particularly useful in customer-domain planning. Two applications both claimed authority over customer contact data: a sales platform and a service platform. The model made that overlap visible, which in turn clarified why downstream reporting and consent management were inconsistent.
Technology mapping and hidden risk
Technology mapping exposed the dependency underside of the portfolio. An application may look healthy in business terms yet still represent elevated risk because it depends on an obsolete runtime, a niche middleware product, or a hosting model the enterprise is trying to exit.
By linking applications to technology domains and strategic platform choices, we could distinguish business criticality from technical sustainability. This was especially valuable in investment planning. Two applications supporting similar capabilities were not necessarily equal if one ran on a strategic platform and the other carried severe technology debt.
Multi-factor portfolio views
The real value came from combining these mappings. Instead of asking whether an application was simply “important,” we could assess it across several dimensions:
- capability criticality
- process embeddedness
- data ownership significance
- integration centrality
- technology risk
That produced a more realistic basis for prioritization. Some applications were strategically important because they supported broad capability coverage. Others were deceptively important because they sat at the center of fragile process and data dependencies. Still others looked replaceable until technology mapping revealed broader platform constraints.
This cross-mapping approach depended on the structural choices made earlier: stable capability anchors from Section 3, disciplined repository organization from Section 4, and selective traceability from Section 2. Without those foundations, portfolio analysis would have become inconsistent across domains.
6. Standards, Naming Conventions, and Reusable Modeling Patterns
At enterprise scale, standards are what turn an ArchiMate repository from a set of reasonable local models into a coherent enterprise asset. The issue is not stylistic neatness. It is whether the model can be searched, compared, merged, queried, and trusted over time.
Naming conventions as part of the metamodel
We treated naming conventions as part of the metamodel, not as editorial guidance. Every core element type had a defined naming structure aligned to its role in the repository.
- Application components were named according to the managed system identity used in portfolio governance.
- Application services were named from the consumer perspective, describing what was provided rather than how the system was built.
- Technology elements followed standardized product and platform naming, including controlled version representation where lifecycle analysis required it.
This reduced ambiguity and improved reporting reliability across domains.
Enterprise identity versus implementation identity
One critical lesson was the need to distinguish enterprise identity from implementation identity. A platform may have a vendor brand, an internal funding name, and several technical instances. If those identities are collapsed into a single label, the model becomes confusing quickly.
We therefore defined explicit conventions for when an element represented:
- the enterprise-recognized application
- a service exposed by that application
- a specific technology product or deployment context
That separation made rationalization, ownership discussions, and migration planning much clearer.
Reusable modeling patterns
Rather than allowing each architect to represent common situations differently, we created a small library of approved patterns. These covered recurring cases such as:
- system-of-record representation
- shared platform decomposition
- SaaS application modeling
- integration hub relationships
- legacy wrapper services
- transition-state coexistence
Each pattern specified the element types, preferred relationships, minimum metadata, and when the pattern should be used. We later added patterns for IAM modernization and event-driven integration, including when to model an identity platform or Kafka backbone as a shared enterprise service rather than as a domain-local implementation.
This directly supported the pragmatic ArchiMate principle from Section 2. Contributors did not need to solve the same modeling problem repeatedly. They could start from an approved pattern and adapt it only where necessary.
Handling ambiguous cases consistently
Reusable patterns were especially valuable in areas where ambiguity was common. Shared enterprise platforms were a good example. Without a standard pattern, some contributors modeled such platforms as a single application component, others decomposed them into modules, and others modeled only the services consumed by their own domain.
Our pattern library defined when to:
- keep a platform intact
- introduce internal application components
- model at service level only
That consistency improved impact analysis and prevented some domains from appearing more important simply because they were modeled in greater detail.
Relationship intent
Standards also had to cover relationship intent, not just naming. Two architects can use the same objects while implying different meanings through different relationships. Our patterns therefore documented why a relationship existed and what decision question it was meant to support.
This discouraged decorative modeling and kept the repository aligned with the decision-oriented objective introduced in Section 2.
Living standards
Finally, we treated standards as living architecture assets. Conventions were versioned, examples were published, and recurring exceptions were used to refine the pattern library. New cloud services, data products, and integration styles inevitably put pressure on the repository. The goal was not rigid uniformity, but controlled adaptability: enough standardization to preserve comparability, enough evolution to keep the model relevant.
7. Lessons Learned, Common Pitfalls, and Recommendations for Scale
Structuring the repository was only part of the challenge. Sustaining its value over time required an operating discipline that matched the scale of the estate.
Lesson 1: Value depends on operating discipline
Repository value depends less on modeling ambition than on sustained operating discipline. Many architecture initiatives begin with a strong metamodel and attractive target views. What determines long-term success is whether the repository remains aligned with how the enterprise actually makes decisions.
If updates happen only during major initiatives or formal architecture review cycles, the model quickly becomes historical. At 500 applications, delay accumulates fast. That is why Section 4 emphasized governance as an operating model rather than an administrative task.
Lesson 2: Do not chase semantic perfection too early
A common pitfall is trying to resolve every conceptual edge case before establishing a usable baseline. In large estates, some ambiguity is unavoidable, especially around application boundaries and shared platforms. It is usually better to define a workable default pattern, document the important exceptions, and improve precision over time.
Decision support suffers more from missing comparability than from controlled imperfection. A mostly consistent model that is used regularly is more valuable than a theoretically perfect one that never reaches meaningful coverage.
Lesson 3: Good diagrams can hide weak structure
Polished diagrams can create false confidence. Executive audiences may see clean visuals without realizing that the underlying content is inconsistent. We learned to test model health through queries, cross-domain comparisons, and impact scenarios rather than presentation quality alone.
If the repository cannot answer basic questions reliably, the problem is structural no matter how good the diagrams look.
Lesson 4: Do not overfit the model to the current organization
Large enterprises reorganize frequently. If repository ownership and content grouping mirror reporting lines too closely, every reorganization creates unnecessary architectural cleanup. More durable anchors are capability domains, application identities, and technology reference structures. This reinforces the stable-anchor principle introduced earlier and formalized in Section 2.
Lesson 5: Do not ignore the long tail
Architecture teams naturally focus on strategic platforms and major transformation programs. Many resilience, compliance, and rationalization risks, however, sit in smaller applications that are lightly governed and poorly understood. These systems may not justify rich modeling individually, but excluding them creates blind spots.
The practical answer is the baseline level-of-detail rule from Section 3: maintain a lightweight minimum standard for all applications, and add richer detail only where complexity, criticality, or change exposure justifies it.
Lesson 6: Stewardship is not authorship
Central architecture teams often assume they must create or correct most repository content themselves. At this scale, that does not work. The better model is domain accountability with central curation: domains own accuracy, while enterprise architecture owns conventions, quality controls, and coaching.
That distinction is essential for sustainability.
Recommendations
For organizations attempting similar work, our main recommendations are:
- Treat the repository as a product with explicit consumers and service levels.
- Define the questions it must answer before expanding the metamodel.
- Use stable business and technology anchors to survive change.
- Enforce a minimum baseline for all applications, then enrich selectively.
- Standardize common patterns so contributors do not invent semantics locally.
- Separate structural architecture from transition-specific context.
- Embed updates in portfolio, risk, and transformation processes.
- Measure quality visibly through validation and reporting, not just manual review.
At enterprise scale, architecture is never finished. The goal is not a complete and permanent representation of the estate, but a model that stays coherent while the estate continues to change.
Conclusion
Structuring an ArchiMate model for a 500-application enterprise landscape required us to think less like diagram authors and more like custodians of an architectural knowledge system. The repository became valuable not because it represented everything, but because it established a dependable architectural grammar for discussing complexity across strategy, delivery, operations, and risk.
The most important outcome was not better documentation by itself. It was better architectural conversation. The model gave portfolio teams a clearer basis for rationalization, helped domain architects identify dependencies earlier, and allowed transformation programs to position change within a broader enterprise context. In that sense, it served both as a representation of the estate and as a coordination mechanism for change.
The core idea running through every section is simple: scale increases the need for deliberate abstraction. Large landscapes do not become understandable by adding detail indiscriminately. They become understandable when detail is organized around stable anchors, constrained through clear conventions, and exposed through viewpoints tied to real decisions.
That is what kept the repository usable as the landscape evolved. For enterprise architecture teams facing similar scale, the practical objective is not to create a static picture of the enterprise, but to build a durable decision asset that evolves with it.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business processes, information systems, and technology. It provides a structured approach to understanding the current state, defining the target state, and managing the transition — using frameworks like TOGAF and modeling languages like ArchiMate.
How does ArchiMate support enterprise transformation?
ArchiMate supports transformation by modeling baseline and target architectures across business, application, and technology layers. The Implementation and Migration layer enables architects to define transition plateaus, work packages, and migration events — creating a traceable roadmap from strategy through to implementation.
What tools are used for enterprise architecture modeling?
The most widely used tools are Sparx Enterprise Architect (ArchiMate, UML, BPMN, SysML), Archi (ArchiMate-only, free), and BiZZdesign Enterprise Studio. Sparx EA is the most feature-rich — supporting concurrent repositories, automated reporting, scripting, and integration with delivery tools like Jira and Azure DevOps.