⏱ 20 min read
Common Enterprise Architect Modeling Mistakes in Large Programs
Discover the most common Enterprise Architect modeling mistakes in large programs, including governance gaps, inconsistent standards, poor traceability, and overcomplicated models—and how to avoid them.
Enterprise Architect modeling mistakes, large program architecture, architecture modeling errors, enterprise architecture governance, model traceability, architecture repository management, UML modeling best practices, ArchiMate modeling issues, systems architecture standards, enterprise architecture quality, modeling consistency, architecture review process Sparx EA best practices
Introduction
In large programs, an Enterprise Architect repository is not just a place to store diagrams. It becomes a working reference for architects, delivery teams, operations, governance forums, and program leadership. The same repository may need to explain business intent, show solution structure, support impact analysis, expose dependencies, and provide evidence for architecture review. That breadth is precisely what makes it valuable—and what makes poor modeling habits expensive. how architecture review boards use Sparx EA
One of the most persistent mistakes is treating modeling as a notation exercise rather than an architectural one. Teams can spend weeks debating whether to use ArchiMate, UML, BPMN, or a local convention, while missing the more important question: what decision is this model meant to support? In a large program, a useful model should clarify a choice, a dependency, a control point, a risk, or an ownership boundary. If it does none of those things, it usually becomes passive documentation—complete in appearance, thin in practical value.
Scale makes the problem harder. In a small initiative, informal diagrams and local shorthand can work because the people who create them are often the same people who use them. In a large program, that overlap disappears. Enterprise architects, domain architects, delivery leads, vendors, security teams, data stewards, and governance bodies all work across the same landscape. Without clear scope, explicit abstraction levels, consistent relationship rules, and named ownership, the repository fragments quickly. Once that happens, traceability weakens, confidence drops, and teams start maintaining parallel views outside the tool.
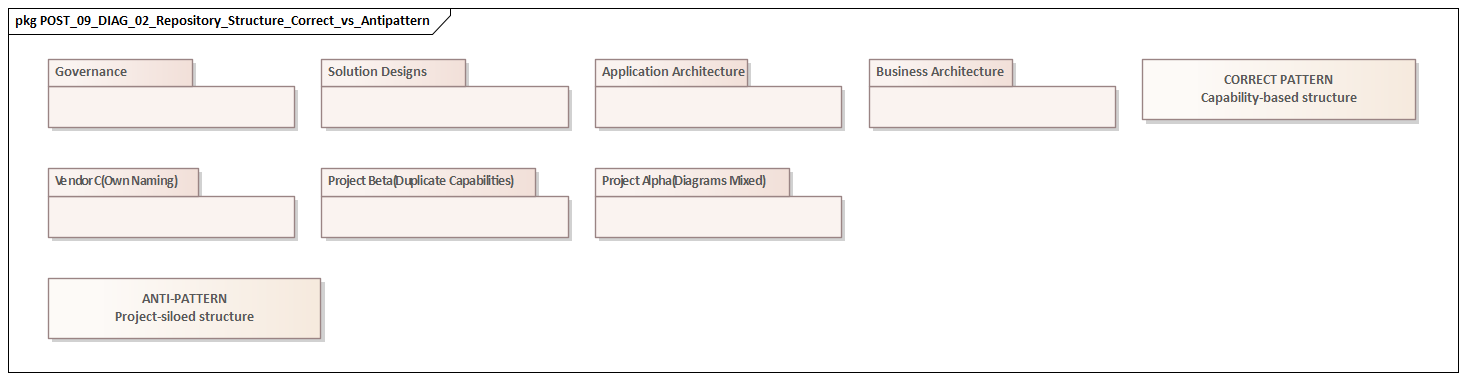
Another recurring issue is structural. Repositories often mirror the organization chart more closely than the enterprise itself. Content is grouped by project, workstream, or funding line rather than by capability, business service, platform, data domain, or lifecycle state. That may help local reporting, but it hides the cross-boundary dependencies architecture is supposed to reveal. In large transformations, the highest risks usually sit at the edges: between business domains, between systems, between data owners, and between shared platforms and local solutions. A CRM change approved for one workstream, for example, may reuse an integration pattern already under review elsewhere. If the repository is arranged around project silos, that collision is easy to miss.
That is why Enterprise Architect should be treated as part of the architecture operating model, not simply as a drawing tool. A strong repository supports governance, standards alignment, transition planning, and change impact assessment. A weak one creates the appearance of control while pushing real decisions somewhere else. free Sparx EA maturity assessment
The mistakes discussed here are common because they often begin with sensible intentions: move quickly, be thorough, satisfy governance, document complexity. In large programs, however, good intentions are not enough. They can still produce repositories that are difficult to use, expensive to maintain, and poor at supporting enterprise decisions. The sections that follow examine the most common modeling mistakes and, more importantly, how to avoid them.
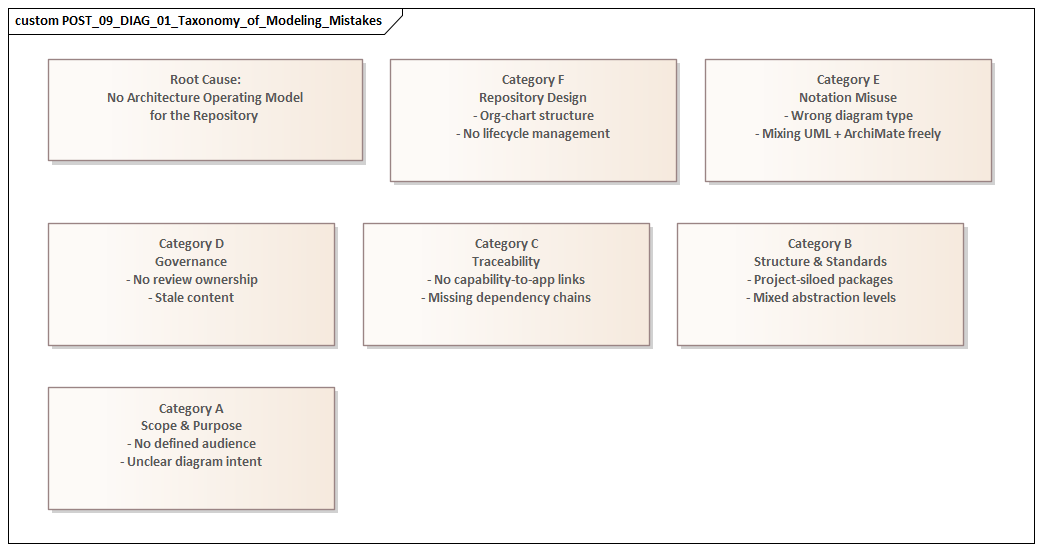
1. Modeling Without Clear Scope, Purpose, and Audience
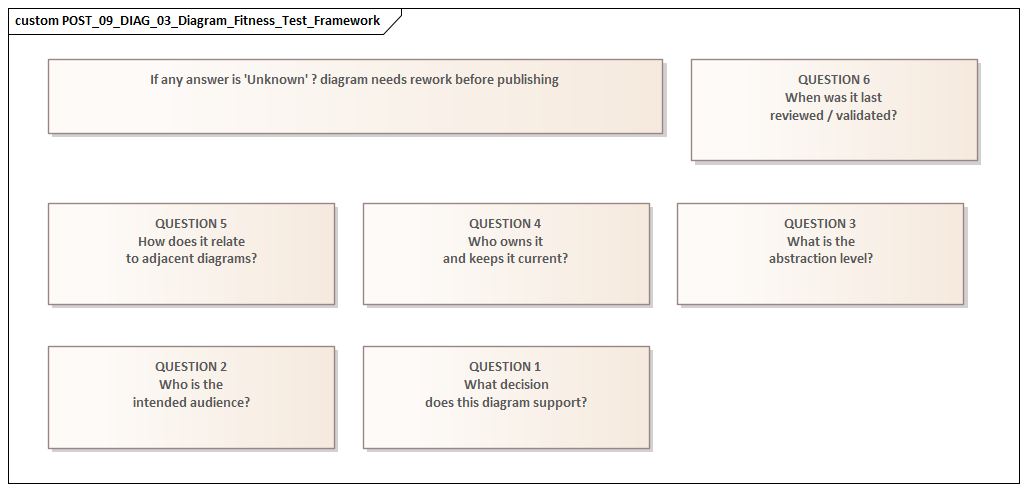
The most common failure in large programs is starting to model before defining what the model covers, why it exists, and who it is for. Time pressure is usually the trigger. Teams need something in the repository for mobilization, governance reviews, or early planning, so they begin drawing. The result may look useful at first glance, but its intent is vague.
Scope is the first problem. A model may describe a capability, process, platform, or solution without stating its boundaries. Is it showing the baseline, the target state, or an interim transition state? Does it cover the whole enterprise, one business unit, or only the systems funded by the current program? Are external providers and shared services included, or simply assumed? If those boundaries remain implicit, stakeholders interpret the same model in different ways. Delivery teams may treat an indicative view as committed design. Governance forums may assume a partial model represents the full impact surface.
Purpose comes next. A model should help someone make a decision. Yet many repositories are full of generic diagrams designed to serve every possible need at once. Those views end up too abstract for engineers and too detailed for executives. Worse, they force the reader to infer why the diagram exists at all. A model built for investment approval should not be structured like one intended for interface design or operational handover.
Audience matters just as much. Different stakeholders need different levels of abstraction and different forms of evidence. A domain architect may need to see application interactions and data ownership. A program manager may care more about dependencies and sequencing. A review board may need traceability from business objective to solution component to standards exception. One diagram rarely serves all three well.
A practical way to avoid this is to create a short modeling brief before substantial repository work begins. It should define:
- the architectural question being addressed
- in-scope and out-of-scope boundaries
- the time horizon
- the intended audience
- the required level of detail
- the decision the model is expected to support
That gives the team a clear test for completeness. A model is complete when it supports the intended decision with enough confidence—not when every possible box has been drawn.
Take a realistic example. A program is deciding whether to centralize identity and access management or allow each product team to modernize separately. The model does not need every screen, protocol attribute, or workflow variant. It needs enough to show identity sources, trust boundaries, privileged access controls, onboarding dependencies, and transition impacts. Anything beyond that may add effort without improving the decision.
This first discipline shapes everything that follows. Once scope and purpose are explicit, layering, traceability, governance alignment, and maintenance expectations become much easier to define. Without that foundation, the rest of the repository tends to drift.
2. Confusing Business, Application, Data, and Technology Layers
When scope and purpose are unclear, the next mistake usually follows: the architectural layers collapse into one blended model. Business processes are shown as if they were applications. Applications appear to own business meaning. Data entities are mixed with interfaces. Technology platforms are presented as though they were business capabilities. The repository may look detailed, but its analytical value declines quickly.
Layering matters because each layer answers a different question:
- Business architecture explains why change is needed, what outcomes matter, and where accountability sits.
- Application architecture shows which systems support those needs and how responsibilities are distributed.
- Data architecture clarifies information meaning, ownership, lifecycle, and movement.
- Technology architecture shows the platforms, infrastructure, and technical constraints that enable the landscape.
When those concerns are blended together, it becomes much harder to tell whether a problem comes from business design, application coupling, data ambiguity, or platform constraint.
A common symptom is the “everything on one diagram” approach. Teams try to show actors, processes, applications, APIs, databases, and cloud platforms in one end-to-end view. The intent is understandable: they want to show the whole picture. In practice, the result usually obscures the real issue. Reviewers cannot tell what is conceptual, what is logical, and what is implementation-specific. Discussion moves into technical detail before the architecture problem itself has been framed.
Ownership becomes distorted as well. A business capability may appear to be “owned” by one application simply because that application dominates the diagram. A database may be treated as the owner of a business concept simply because it stores the records. In reality, ownership usually sits with a business domain, while systems and data stores implement that responsibility. If the repository blurs those distinctions, funding decisions, control design, and impact analysis become less reliable.
The answer is not rigid purity; it is controlled separation with explicit linkage. Each layer should be modeled for its own purpose and then connected through clear relationships. For example:
- business capabilities link to processes, services, roles, and outcomes
- applications support or realize business services and processes
- data entities link to business meaning, stewardship, and system usage
- technology components host or enable applications and data services
This makes complexity easier to navigate and gives each stakeholder a view at the right level. Business leaders can validate capability impacts without debating infrastructure. Engineers can assess technical dependencies without redefining business intent.
A simple micro-example illustrates the point. In an event-driven fulfillment program, the business layer might define the domain event Order Dispatched as part of the customer promise process. The application layer would show which services publish and consume that event. The data layer would define the event payload terms and stewardship. The technology layer would show Kafka topics, schema registry, and retention settings. Put all of that into one undifferentiated diagram and the conversation quickly turns into topic naming and broker configuration, while the actual business question—what triggers customer notification and who owns the event semantics—gets lost.
Clear layering does not reduce realism. It makes realism usable.
3. Creating Overengineered Models That Teams Cannot Use
If the first two mistakes create ambiguity, this one creates friction. Large repositories often fail because they are too elaborate to be practical. Architects introduce excessive detail, too many element types, intricate metamodels, and documentation structures that the program cannot realistically maintain. The intention is rigor. The result is often low adoption.
One clear sign of overengineering is a repository optimized for modeling purity rather than program use. Architects define extensive stereotypes, mandatory metadata for every object, deep package hierarchies, and highly granular relationship rules. In theory, that creates control. In practice, most contributors do not have the time, training, or incentive to maintain it consistently. Quality becomes uneven. Some areas are highly structured; others remain sparse. Confidence in the repository drops accordingly. Sparx EA training
A repository should help people answer recurring questions quickly. Overengineered models do the opposite by increasing cognitive load. Delivery leads want to understand dependencies. Engineers want to see integration responsibilities and constraints. Governance forums want evidence of alignment, risk, and exception handling. If stakeholders need specialist support just to interpret the model, they will revert to slides, spreadsheets, or local diagrams.
The maintenance burden is another warning sign. Large programs change constantly: interfaces evolve, scope shifts, transition states move, and exceptions get approved. If every change triggers updates across a dense web of detailed elements, the repository becomes expensive to keep current. It may still look sophisticated, but it gradually drifts away from delivery reality.
The right level of detail is the minimum needed to support governance, coordination, and design decisions with confidence. Not every part of the estate needs the same modeling depth. Shared platforms, critical integrations, regulated controls, and cross-domain data flows usually justify richer metadata and stronger traceability. Temporary utilities, low-risk local solutions, or commodity services usually do not. ArchiMate modeling guide
A useful test is straightforward: can the model answer common program questions quickly and reliably? For example:
- Which capabilities are affected by this release?
- What upstream and downstream dependencies exist for this change?
- Where are standards exceptions in place?
- Where is data ownership unclear?
- Which teams are changing the same platform?
If the answer is no, adding more detail is unlikely to help. Better curation, clearer viewpoints, and tighter focus usually matter more than additional complexity.
Consider a realistic example from payments modernization. A repository may contain hundreds of objects describing every message field, queue, environment, and firewall rule. Yet if it cannot show which payment journeys still depend on a legacy settlement engine, which channels are affected by its retirement, and which teams own the cutover sequence, it is over-modeled in the wrong places. By contrast, a leaner model that captures payment capabilities, settlement services, integration dependencies, and release transitions may support the decision far better.
A usable repository is not a simplified repository. It is one where the complexity is deliberate.
4. Failing to Maintain Traceability Across Requirements, Capabilities, Processes, and Solutions
Traceability is often the point at which a repository either proves its worth or exposes its weakness. Large programs may contain requirements, capabilities, process models, applications, interfaces, and work packages, but the links between them are often thin or inconsistent. When that happens, line of sight from strategic intent to delivery reality is lost.
This usually occurs because different parts of the change are modeled in different places with little structural connection. Requirements sit in one package, capabilities in another, process models somewhere else, and solution designs under project-specific folders. Each artifact may be valid on its own, but the repository still cannot answer basic enterprise questions with confidence:
- Which capabilities are being improved by this release?
- Which processes are affected by a changed requirement?
- Which applications implement a control or policy obligation?
- Which solution components are tied to a particular business outcome?
Without traceability, those questions become manual investigations rather than routine architectural analysis.
Good traceability does not mean linking everything to everything. That simply produces noise. What matters is a selective chain of reasoning that supports governance and delivery. In most large programs, that chain looks something like this:
drivers and obligations → requirements → capabilities and processes → services and solution building blocks → work packages or releases
When those relationships are explicit, the repository becomes an evidence base rather than a collection of disconnected views.
Traceability matters most during change control. Requirements shift because of policy updates, funding constraints, delivery realities, and emerging risks. If those requirements are not linked to the capabilities, processes, and solution components they affect, impact assessment becomes unreliable. Teams may think they are making a local design change when they are actually affecting enterprise controls, shared platforms, or customer journeys.
It also influences prioritization. Program leaders need to distinguish between strategic progress and local technical activity. If capabilities are not traced to solution increments, the repository cannot show whether delivery is moving the enterprise toward its target state or simply adding more complexity.
A small but realistic example makes this clear. Suppose a regulatory change requires stronger customer consent capture for data sharing. If the repository links that obligation to the affected customer onboarding capability, the consent management process, the CRM and digital channels, the consent data entity, and the release work packages implementing the change, an architecture board can assess impact in minutes. If those links are missing, the same question turns into a multi-team discovery exercise. multi-team Sparx EA collaboration
A practical minimum is to define a mandatory traceability path for governed change. For example:
- each material requirement links to a business capability or policy objective
- that capability links to affected processes or services
- those processes or services link to key applications, data entities, and technology components
- major solution components link to the work packages or releases that change them
That is usually enough to support decision-grade lineage without overwhelming the repository.
Ownership is critical here. Traceability decays when each role updates only its own artifacts and no one maintains the relationships between them. In large programs, cross-layer linkage has to be assigned, reviewed, and checked as part of governance. Otherwise the repository slowly becomes a set of parallel truths.
5. Treating Architecture Models as Static Documentation Instead of Living Assets
Even a well-structured repository loses value if it is not maintained as the program evolves. A common mistake is to create models for a gate, review, or funding submission and then leave them largely untouched. They remain polished enough to look authoritative, but they no longer reflect current decisions or delivery reality.
This is especially common in stage-gated environments. Teams produce strong architecture artifacts during mobilization or design, pass governance checkpoints, and then move into delivery using backlogs, vendor documents, sprint boards, and wikis. The repository is not deliberately abandoned; it simply stops being part of the operating rhythm. Over time, the real architecture lives somewhere else.
In large programs, that is risky because change is constant. Transition states move, sequencing assumptions break, interfaces evolve, and temporary exceptions become semi-permanent. If the repository is updated only at major milestones, it cannot support one of architecture’s core functions: understanding the consequences of change while change is happening.
A living model depends on the same disciplines already discussed:
- clear purpose, so teams know which views matter
- selective detail, so updates remain manageable
- layering, so changes can be assessed at the right level
- traceability, so impact can be followed across the estate
Without those foundations, maintenance becomes expensive and the repository drifts.
The practical answer is to align updates with delivery and governance events rather than annual refresh cycles. Significant epics, interface changes, platform decisions, standards waivers, and release milestones should trigger targeted updates to the relevant views and relationships. Not every diagram needs revision every sprint, but critical views should have an expected refresh cadence tied to program controls.
Technology lifecycle governance is a good example. If a database platform moves from strategic to contain or retire, affected applications, data stores, and transition plans should be updated in the repository—not just in a standards spreadsheet. The same applies when a shared integration platform is extended beyond its approved use or when a temporary identity provider exception is granted pending migration.
It also helps to distinguish clearly between:
- baseline state
- approved transition state
- emerging or under-review state
- retired state
Many repositories become misleading because old target-state diagrams remain visible with no indication of what is still planned, what is in flight, and what has already been replaced. Simple lifecycle visibility goes a long way toward restoring trust.
Think of a cloud migration program where a target-state diagram still shows all customer workloads on the strategic landing zone, even though three critical services remain on legacy virtual machines due to latency and licensing constraints. If the repository does not show that interim reality, dependency planning, resilience assessment, and budget decisions will all be distorted. The problem is not the diagram; it is the absence of lifecycle discipline.
A living repository earns its place by supporting active decisions: release impact analysis, dependency management, roadmap adjustment, and exception review. If it cannot do that, teams will bypass it no matter how polished it looks.
6. Ignoring Governance, Standards, and Stakeholder Alignment
The final mistake is separating modeling from the governance and stakeholder environment that gives architecture its authority. A repository can be technically correct and still be operationally weak if it does not reflect approved standards, decision rights, and stakeholder concerns.
One common pattern is to keep governance outside the model. Standards live in separate documents. Exceptions sit in committee papers. Design decisions are buried in meeting minutes. The repository may show applications, interfaces, and platforms, but not which standards apply, where deviations have been approved, or what risk has been accepted. Review boards are then forced to rely on presentations and verbal explanation instead of evidence held in the repository itself.
Stakeholder alignment is the other half of the problem. Large programs involve enterprise architects, domain architects, security teams, data offices, service managers, program leaders, vendors, and operational owners. Each group has legitimate concerns, but repositories are often designed around only one or two of them. A model may support solution design while omitting operational ownership, control obligations, or policy dependencies. Or it may satisfy governance reporting while offering little practical value to delivery teams.
A repository works only when it is designed around real decisions, and governance decisions are part of that. Standards, principles, approved patterns, waivers, and decision records should be treated as first-class elements, linked directly to the applications, services, data objects, and technology components they govern. That allows reviewers to see not only what has been designed, but why it is acceptable, where it departs from standards, and which trade-offs have been approved.
For example, if an architecture board approves Kafka as the strategic event backbone, that decision should not sit only in meeting minutes. It should be linked in the repository to the domains expected to publish events, the integration patterns being retired, the schema governance obligations, and any exceptions granted to systems that cannot migrate in the current funding cycle. Likewise, if a temporary waiver permits a business unit to remain on a non-standard IAM platform, the affected applications, sunset date, risk owner, and migration dependency should all be visible in the model.
Stakeholder needs should shape repository structure from the outset. For example:
- security may need trust boundaries and control inheritance
- operations may need service ownership and resilience dependencies
- data governance may need stewardship, classification, and retention visibility
- program leadership may need transition sequencing and delivery exposure
When those needs are built into the model design, architecture becomes easier both to govern and to use.
This final mistake brings the earlier themes together. Scope, layering, selective detail, traceability, and lifecycle maintenance all contribute to one larger outcome: making the repository part of the program’s control system rather than a side activity. If governance is detached from the model, the repository becomes descriptive but not authoritative. If stakeholder concerns are ignored, it becomes authoritative in theory but irrelevant in practice.
Conclusion
In large programs, the real test of an Enterprise Architect repository is not how much it contains, but whether it improves decision-making under pressure. When funding is time-bound, delivery is moving quickly, and governance needs evidence rather than assertion, poor modeling becomes an operational risk. It hides dependencies, weakens accountability, and drives teams toward parallel documentation outside the managed architecture environment.
The strongest repositories are designed as decision systems, not diagram collections. They begin with clear scope, purpose, and audience. They preserve the distinction between business, application, data, and technology concerns while linking those layers explicitly. They avoid unnecessary complexity, maintain decision-grade traceability, stay current as delivery evolves, and embed standards and governance directly into the architecture record.
Not every part of the estate deserves the same modeling intensity. Good architects invest most heavily where complexity, reuse, regulation, operational criticality, or cross-domain dependency is highest. That selective discipline is what keeps a repository useful and sustainable.
Ultimately, Enterprise Architect delivers value when it is treated as a living part of the architecture operating model: connected to governance, maintained through delivery change, structured for traceability, and shaped around stakeholder decisions. Large programs do not need repositories that merely look comprehensive. They need repositories that remain trustworthy as the enterprise changes.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business processes, information systems, and technology. It provides a structured approach to understanding the current state, defining the target state, and managing the transition — using frameworks like TOGAF and modeling languages like ArchiMate.
How does ArchiMate support enterprise transformation?
ArchiMate supports transformation by modeling baseline and target architectures across business, application, and technology layers. The Implementation and Migration layer enables architects to define transition plateaus, work packages, and migration events — creating a traceable roadmap from strategy through to implementation.
What tools are used for enterprise architecture modeling?
The most widely used tools are Sparx Enterprise Architect (ArchiMate, UML, BPMN, SysML), Archi (ArchiMate-only, free), and BiZZdesign Enterprise Studio. Sparx EA is the most feature-rich — supporting concurrent repositories, automated reporting, scripting, and integration with delivery tools like Jira and Azure DevOps.