⏱ 24 min read
Event-Driven Architecture Patterns from Transformation Programs
Explore proven event-driven architecture patterns from enterprise transformation programs, including integration strategies, domain events, scalability, resilience, governance, and modernization best practices. Sparx EA best practices
event-driven architecture, EDA patterns, transformation programs, enterprise architecture, domain events, event streaming, system integration, microservices, scalability, resilience, modernization, architecture patterns, enterprise transformation, event brokers, technical architecture Sparx EA guide
Introduction
Event-driven architecture (EDA) has become a practical design choice in large transformation programs because it helps enterprises coordinate change across many systems without hard-wiring dependencies between them. Few organizations modernize from a clean slate. Most are working through a mixed landscape of packaged applications, custom platforms, cloud services, SaaS products, operational technologies, and long-established data estates. In that environment, events provide a workable way to connect business capabilities while allowing systems and teams to evolve at different speeds.
The value of EDA is not limited to asynchronous messaging. Its deeper contribution is support for operational autonomy and incremental change. When a domain publishes a meaningful business event such as OrderSubmitted, CustomerProfileUpdated, or PaymentCleared, other systems can react without knowing the producer’s internal process logic or data model. That reduces point-to-point integration, lowers coordination overhead, and makes it easier to add new consumers such as analytics services, workflow tools, customer notifications, or digital channels without destabilizing existing applications.
In practice, EDA rarely appears as an isolated technical pattern. It usually emerges alongside broader shifts such as monolith decomposition, API platform renewal, domain-aligned operating models, IAM modernization, and the push for near-real-time operational insight. As adoption grows, events become both an integration mechanism and a governance concern. Architects must decide not only how events move, but also how they are named, versioned, secured, observed, and owned. Without that discipline, an event backbone quickly turns into another unmanaged integration layer.
Transformation programs also show that EDA is not one pattern but a family of patterns. Some scenarios need lightweight event notification. Others need event-carried state, event streaming, scalable asynchronous processing, or choreography across multiple services. The architectural task is to match the pattern to the business problem rather than apply eventing by default. That matters most in regulated environments, multi-business-unit programs, and estates where legacy and modern platforms will coexist for years.
This article looks at event-driven architecture through the lens of enterprise transformation delivery rather than abstract theory. It focuses on the issues architects repeatedly encounter: uneven modernization across the estate, the tension between agility and governance, integration across legacy and SaaS platforms, and the challenge of operating event ecosystems reliably at scale. The point is not to present eventing as a universal destination, but to show how a disciplined set of event-driven patterns can help enterprises modernize in manageable steps while preserving resilience, traceability, and business alignment.
Why Event-Driven Architecture Emerges in Enterprise Transformation Programs
Event-driven architecture usually appears in transformation programs for a simple reason: traditional integration approaches start to strain under the volume and pace of change. Large programs rarely move in a single line. Platform renewal, channel redesign, process automation, reporting modernization, IAM change, and selective retirement of legacy applications often run in parallel. In that setting, tightly coordinated request-response dependencies become a delivery constraint. Every interface change demands negotiation, synchronized releases, and cross-team regression testing. Events reduce that dependency by letting producers and consumers evolve more independently.
That flexibility matters because transformation is rarely uniform across the estate. One domain may be ready for cloud-native services while another remains tied to a packaged platform or a legacy core with limited integration options. Some systems expose modern APIs; others can produce only files, database changes, or middleware messages. EDA offers a bridging model across that uneven terrain. Rather than waiting for every platform to reach the same maturity level, architects can introduce an event backbone that allows new services, data products, and automation components to react to business changes as they occur. free Sparx EA maturity assessment
A second driver is the need to separate systems of record from systems of engagement. Many enterprises want to redesign customer and employee experiences without repeatedly modifying core transaction platforms that are expensive, slow, or risky to change. Events support that separation. Core systems remain focused on integrity and transaction processing, while downstream services consume business changes to provide responsiveness, personalization, workflow, and operational visibility. ArchiMate modeling best practices
A retail banking program illustrates the point. The core account platform remained unchanged during the first release wave, but it emitted AccountOpened and AddressChanged events through an integration layer. Mobile onboarding, welcome communications, and branch task creation all subscribed independently. The bank improved customer responsiveness without reopening the core platform for each new downstream requirement.
Delivery economics also play a part. Program teams need a way to introduce new capabilities without reopening every existing integration. If a fraud service, communication engine, or operational dashboard can subscribe to an established event, the marginal cost of change is lower than building another bespoke interface. Over time, the model shifts from negotiated bilateral connections to reusable business signals. That is especially useful when many consumers need the same trigger for different purposes.
EDA also reinforces operating model change. Publishing an event forces a domain to define what business fact it owns and what contract others may rely on. That creates clearer ownership boundaries than shared-database access or undocumented service calls. In one architecture board decision, a customer domain was allowed to publish CustomerProfileUpdated but not expose direct database access to downstream teams. The board accepted slower initial onboarding in exchange for clearer long-term ownership and lower coupling.
Finally, transformation programs increasingly need visibility into business operations, not just infrastructure. Leaders want to know where orders stall, how long process stages take, and which downstream actions were triggered. Event streams naturally create a trail of business facts that can support monitoring, audit, SLA tracking, and process mining. In several programs, that operational transparency became one of the strongest secondary benefits of EDA and shaped the observability model as much as the integration model itself.
Core Event-Driven Architecture Patterns Used in Modernization Initiatives
EDA is not a single solution style. In modernization initiatives, architects usually rely on a small set of recurring patterns and apply them selectively based on business criticality, data sensitivity, and operational need.
Event Notification
Event notification is the lightest pattern and often the safest place to start. A producer emits a signal that something important has happened, but the event carries minimal data. Consumers then decide whether they need to retrieve more information through APIs or other services.
This pattern works well when the goal is to reduce direct coupling without broadly distributing business state. It is often used to add digital channels, workflow tools, or alerts around existing systems of record. Its main weakness is ambiguity. An event such as CustomerUpdated may be easy to publish, but if consumers cannot tell what changed or whether action is required, they are pushed back into synchronous calls to the source system. Hidden coupling returns through the side door.
A stronger implementation uses precise business meaning and enough metadata for consumers to decide whether to act. Notification events should be lightweight, but they should not be vague.
Event-Carried State Transfer
Event-carried state transfer extends the notification model by including the business data consumers are expected to use. This is valuable when downstream services need to react quickly and should not depend on synchronous retrieval from the producer.
In transformation programs, this pattern often supports customer engagement platforms, search indexes, operational data stores, low-latency decisioning services, and downstream automation. Its advantage is responsiveness and reduced dependence on source-system availability. Its cost is governance complexity. Once business state is distributed through events, architects must manage schema evolution, data classification, retention, replay behavior, and lineage.
A common example appears in insurance claims. Rather than publishing a bare ClaimUpdated notification, a claims service may emit ClaimValidated with claim number, product line, severity code, fraud indicator, and validation timestamp. That allows downstream triage, customer communication, and work allocation services to respond immediately, without repeatedly querying the claims platform.
The practical rule is straightforward: publish the state required for a clear business use case, not an uncontrolled replica of transactional tables.
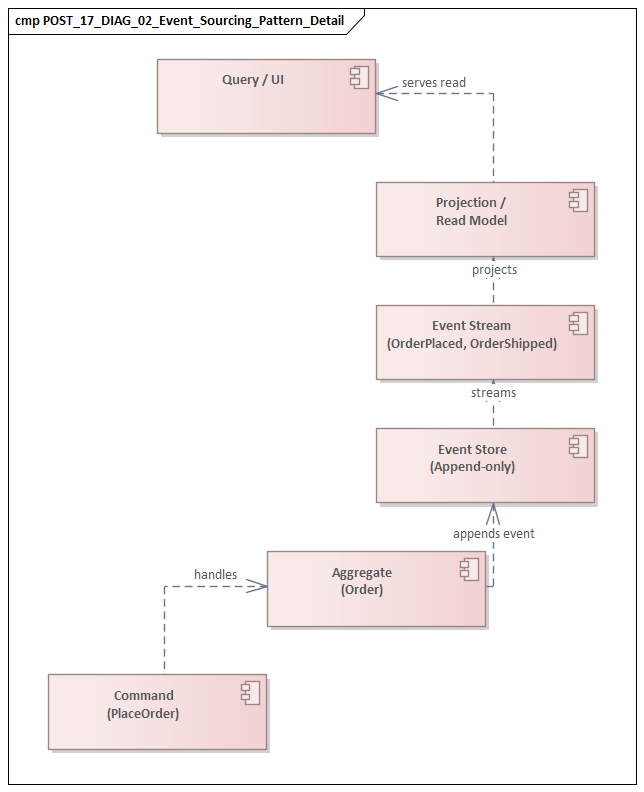
Event Streaming
Event streaming is appropriate when the value lies in a continuous flow of facts rather than isolated messages. It supports near-real-time analytics, operational monitoring, anomaly detection, and derived data products.
In modernization programs, streaming often appears when organizations want to move beyond batch reporting without replacing core platforms immediately. Streams from multiple domains can be correlated and processed incrementally to create a live operational picture without imposing extra load on source applications. A realistic example is a Kafka-based operations stream combining OrderSubmitted, PaymentCleared, and ShipmentDispatched events to show fulfillment bottlenecks within minutes rather than in next-day reports.
Streaming, however, requires more than a broker. It depends on deliberate choices about partitioning, ordering, retention, replay, and ownership of derived streams. Without those decisions, a streaming estate can become technically capable but hard to understand or govern.
Competing Consumers
The competing consumers pattern focuses on scalability and resilience. Multiple consumer instances process events from the same channel so workloads such as document generation, enrichment, case creation, or outbound communication can scale horizontally.
This pattern is particularly useful when demand is uneven or when legacy batch backlogs are being replaced by elastic services. The critical design concern is idempotency. Duplicate delivery, retries, and partial failure are normal operating conditions in enterprise environments. Consumers therefore need explicit handling for reprocessing, poison messages, and side effects.
A utilities program used this pattern to replace overnight billing print batches. BillReadyForDelivery events were consumed by a pool of document-generation workers, each able to scale independently during month-end peaks. The design only became reliable once the team introduced idempotency keys and duplicate suppression for reissued bills.
Event-Based Choreography
Event-based choreography is used when multiple services react to each other’s events to complete a broader business process without a central orchestrator controlling every step.
This can increase autonomy and reduce dependence on a single workflow engine, especially in domain-aligned operating models. It should still be applied selectively. Choreography works best where process steps are loosely coupled and responsibilities are clear. In regulated or high-risk scenarios, too much choreography can make business control flow difficult to understand, audit, and change.
A common enterprise approach is to combine patterns: use choreography for local domain reactions, but retain explicit orchestration or case management where end-to-end control, exception handling, or compliance evidence is required.
Pattern Selection in Practice
Successful programs do not standardize on a single pattern. They establish a governed set of patterns and use them deliberately. An architecture board may approve Kafka for high-volume domain events and streaming analytics, while requiring synchronous APIs for immediate entitlement checks in an IAM modernization program. The objective is not to maximize event usage. It is to create an event model that remains intelligible, supportable, and aligned to transformation outcomes.
Designing Event Contracts, Schemas, and Governance for Enterprise Scale
Once event-driven adoption extends beyond a few isolated use cases, the central challenge shifts from transport to contract design. At enterprise scale, the long-term value of an event ecosystem depends less on broker technology than on whether events are understandable, stable, and governable across many teams.
A useful starting point is to treat an event contract as a business-facing integration product, not just a message definition. The contract should state what business fact occurred, which domain owns it, what the event means, and what consumers may safely assume. That is why naming matters. Events should describe completed business occurrences such as InvoiceIssued or ClaimValidated, not technical triggers such as RecordChanged.
Schema design needs the same discipline. Enterprise events should distinguish clearly between mandatory business identifiers, contextual metadata, and optional attributes. A strong schema usually includes a stable header with fields such as event type, version, event time, producer identity, correlation identifier, and classification markers, along with a payload carrying domain-specific content. That separation supports routing, tracing, audit, and policy enforcement without forcing every consumer to interpret the full payload.
Versioning is one of the most persistent issues in transformation programs. Contracts change because processes change, regulations evolve, and new consumers create pressure for additional data. The goal is not to prevent change, but to make it survivable. Backward-compatible evolution should be the default. Adding optional fields is usually preferable to changing semantics or removing attributes. Where breaking changes are unavoidable, architects need explicit versioning rules, deprecation timelines, and communication mechanisms. A schema registry or equivalent contract repository is valuable not only as a technical control, but also as a shared source of truth for ownership, lifecycle status, and approved usage.
Governance must also address data responsibility. Events often cross organizational and legal boundaries, so payload design cannot be separated from data classification and retention policy. Sensitive information should not be propagated simply because the platform makes distribution easy. Domains should justify why attributes are included, who may consume them, and how long they should remain available for replay or analysis. This reinforces a basic principle of event-carried state transfer: publish the minimum business data needed for the intended interaction.
A healthcare example makes the point. A scheduling platform initially proposed publishing full patient demographics in AppointmentBooked events so downstream reminder and reporting services could avoid lookups. The architecture review rejected that design. The approved contract carried appointment ID, clinic ID, booking time, and a patient reference token, while protected demographic data remained behind controlled APIs. The event still supported workflow and analytics, but with a far smaller privacy footprint.
Effective governance is rarely achieved through central review boards alone. It works better when lightweight enterprise standards are combined with domain accountability. Central architecture can define conventions for naming, metadata, versioning, security tagging, and documentation, while domain teams remain responsible for semantic quality and contract stewardship. In practice, design-time checklists, reusable schema templates, automated validation in CI/CD pipelines, and catalog-based discoverability are often more effective than heavy approval processes. This is also where technology lifecycle governance matters: teams may be required to publish only through supported broker versions and approved client libraries, with older messaging components placed on a timed retirement path.
The broader lesson is simple. Governance must enable reuse without slowing delivery to a crawl. If standards are too weak, the event landscape becomes inconsistent and hard to trust. If they are too rigid, teams bypass the model and create private integrations instead. The most effective enterprise approach provides enough structure to preserve clarity, interoperability, and compliance while still allowing domains to evolve their event products within well-understood boundaries.
Integrating Legacy Systems, SaaS Platforms, and Domain Services Through Events
One reason EDA emerges in transformation programs is that modernization happens unevenly. That reality becomes most visible when events have to connect legacy systems, SaaS platforms, and newly built domain services within the same business flow.
Legacy Systems
For legacy platforms, the key pattern is usually event enablement at the boundary rather than deep internal redesign. In many cases, the source system cannot publish well-formed business events directly. Architects therefore introduce intermediary mechanisms such as change data capture, transaction log mining, batch-to-event conversion, integration middleware, or wrapper services that observe state changes and emit curated events outward.
The important design choice is to avoid exposing raw technical changes as enterprise events. A database update or file arrival may be the trigger, but consumers need a business-level fact that remains meaningful beyond the legacy implementation. That often requires a translation layer that enriches, filters, and normalizes source changes before they enter the broader event backbone.
SaaS Platforms
SaaS products create a different challenge. Many provide webhooks, outbound notifications, or proprietary event feeds, but those interfaces are shaped by the vendor’s object model and release cycle rather than the enterprise domain model. If consumed directly, they can pull downstream architecture toward product-specific semantics. how architecture review boards use Sparx EA
A more sustainable approach is to treat vendor events as inputs to an anti-corruption layer. That layer maps SaaS-specific structures into enterprise event contracts, applies policy controls, and shields consumers from vendor changes. This is especially important where multiple SaaS products support adjacent processes and the organization wants to preserve freedom to replace or reconfigure them later.
For example, a CRM platform may emit a webhook when an opportunity stage changes. Rather than passing that vendor event straight to downstream consumers, an integration service can translate it into SalesOpportunityQualified or SalesOpportunityClosedLost, using enterprise identifiers and agreed business semantics. That small design choice prevents the vendor’s object taxonomy from becoming the enterprise integration model.
Domain Services
Domain services are often the easiest producers and consumers to align with enterprise standards, but they introduce a different risk: fragmented event design driven by local team preferences. In practice, they integrate most effectively when architects distinguish between internal service events, domain-shared events, and enterprise-wide events.
Not every event generated within a microservice landscape should be exposed broadly. Some are useful only for local coordination, while others represent business facts that other domains can legitimately depend on. This layering prevents the event platform from being saturated with low-value technical chatter and reinforces contract discipline.
Coexistence Patterns
During transformation, the same business process may span a legacy core, a SaaS workflow platform, and newly built domain services. Events can connect them, but only if architects design for uneven latency, partial ownership, and inconsistent failure behavior. Legacy systems may emit delayed batches, SaaS platforms may throttle notifications, and domain services may expect near-real-time reactions.
Integration design therefore needs explicit handling for temporal mismatch, replay windows, duplicate signals, and fallback procedures when one platform cannot participate at the same operational standard as another. Coexistence is not only an integration problem; it is also an observability and resilience problem.
Successful programs usually establish a small number of reusable building blocks such as legacy event adapters, SaaS normalization services, canonical metadata standards, and policy-based routing. The objective is not to make every platform equally event-native, but to create a consistent enterprise interaction model despite underlying diversity.

Operating Event-Driven Architectures: Observability, Resilience, and Security Patterns
Designing an event-driven architecture is only part of the enterprise challenge. Once events become part of a core business flow, the architecture has to be operated as a reliable business platform. Attention then shifts from design-time pattern selection to runtime discipline.
Observability
Observability in EDA requires more than broker health metrics. Architects need visibility into business progression across asynchronous hops: which event was published, which consumers processed it, which downstream events were emitted, and where delays or failures occurred.
That usually requires correlation identifiers, standardized metadata, distributed tracing where supported, and business-level monitoring dashboards. One of the strongest reasons EDA gains traction in transformation programs is the promise of operational transparency. That benefit is realized only when observability is designed around business journeys and domain outcomes, not just infrastructure status.
A broker may be healthy while a customer journey is failing. Technical telemetry alone rarely explains why an order was not fulfilled or why a notification was never sent. Enterprises therefore need monitoring models that connect event flow to business state.
Resilience
Event-driven systems fail in ways that are often less visible than synchronous services. Consumers may lag, process stale data, retry indefinitely, or produce inconsistent side effects after partial failure. For that reason, architects should treat duplicate delivery, out-of-order events, replay, and transient downstream outages as normal operating conditions.
Idempotent consumers are the baseline requirement, especially for patterns such as competing consumers. Mature operating models go further: dead-letter handling, retry policies with backoff, poison message isolation, and clear replay procedures are all essential. Replay is particularly important. It supports recovery and audit, but only if schemas, retention settings, and consumer logic are designed to tolerate historical reprocessing without corrupting business outcomes.
Flow control is another resilience concern. Event backbones can absorb bursts, but downstream systems often cannot. A legacy platform, SaaS API, or document service may have throughput limits that are invisible to upstream publishers. Without back-pressure controls, buffering strategies, and consumer throttling, the event platform simply moves the point of failure. Architects should therefore define rate-aware consumers, circuit breakers around dependent services, and workload prioritization for critical events.
Security
Security in EDA must be treated as a runtime concern, not just a design-time checklist. Because events are propagated, retained, replayed, and consumed by multiple parties, the attack surface is broader than in tightly scoped API calls.
Enterprise controls typically include producer authentication, consumer authorization, topic- or stream-level access policies, encryption in transit and at rest, and tamper-evident audit trails. Fine-grained data protection is particularly important where a single stream may contain both operational and regulated information. In some cases, this requires tokenization, field-level encryption, or separation of sensitive payloads from broadly consumable metadata.
This directly reinforces the governance principles discussed earlier: minimal payload design and clear classification are not only data management concerns, but also security controls. A common IAM modernization example is to publish AccessProvisioned or RoleRevoked events for downstream audit and workflow, while keeping entitlement decisions and privileged approval checks behind tightly controlled synchronous services.
Shared Operational Responsibility
Successful operating models define clear responsibilities across platform engineering, security, and domain teams. Platform teams usually own broker reliability, policy enforcement, and monitoring foundations. Domain teams remain accountable for semantic correctness, consumer robustness, and business incident response.
This matters because many failures are not broker outages. They are contract misunderstandings, schema misuse, unhandled edge cases, or downstream processing defects. Enterprises that treat EDA operations as a shared discipline, supported by runbooks, replay procedures, service-level objectives, and business-aware monitoring, are far more likely to sustain event-driven adoption beyond initial releases.
Lessons from Transformation Programs: Organizational Alignment, Delivery Models, and Anti-Patterns
A consistent lesson from transformation programs is that event-driven architecture succeeds or fails less on broker selection than on organizational alignment. If funding, governance, and team responsibilities remain organized around applications rather than business capabilities, events tend to mirror old silos in a new technical form. Producers publish what is convenient for their system, consumers create private interpretations, and hidden dependency accumulates.
That is why event design must be tied to domain ownership and operating model decisions, not treated as a middleware workstream on its own. Contract and governance practices are effective only when there is a clear accountable owner behind each event product.
Delivery model matters as well. Event-driven change works best when teams can release producers, consumers, schemas, and observability changes through coordinated but independent pipelines. Where release processes remain heavily centralized, the theoretical agility of EDA is undermined by environment bottlenecks, shared test dependencies, and lengthy approvals. A practical response is to establish product-oriented delivery around event domains, with self-service lower environments, automated compatibility checks, and platform guardrails that reduce manual coordination.
Another recurring lesson is that event adoption should follow business value streams, not technical enthusiasm. Programs that begin by creating a generic enterprise event catalog often struggle to generate meaningful reuse. By contrast, initiatives focused on a small number of high-value journeys such as onboarding, fulfillment, claims handling, or service restoration usually produce better event models because the business significance, consumers, and outcomes are clearer.
Transformation programs also expose several common anti-patterns:
Event Everywhere
Some teams try to replace all synchronous integration with asynchronous messaging regardless of need. This creates unnecessary complexity in scenarios that require immediate validation, deterministic responses, or tightly controlled transactions. EDA should complement other styles, not replace them indiscriminately.
Publishing Internal Noise
Another anti-pattern is using events as a substitute for poor domain design. Teams publish excessive internal state changes because service boundaries are unclear. This floods the platform with low-value technical chatter and forces consumers to reconstruct business meaning that should have been explicit.
Central Team as Bottleneck
A further anti-pattern is the creation of a central event team that becomes a delivery gatekeeper. Some central capability is necessary, but if every topic, schema, and subscription depends on a specialist bottleneck, onboarding slows, teams create workarounds, and fragmentation follows. A federated model works better: central teams own standards, reliability, and enablement, while domain teams own semantic design and lifecycle accountability.
Unowned Contracts and Hidden Dependencies
Programs also struggle when event contracts have no clear owner, when consumers rely on accidental payload details, or when private topics recreate hidden point-to-point coupling. These are governance and organizational failures as much as technical ones.
The strongest programs treat EDA as both a technical pattern set and a change discipline. They invest in domain ownership, contract stewardship, platform self-service, and delivery metrics that show whether events are improving lead time, reuse, and operational responsiveness. They also review anti-patterns explicitly rather than assuming good event design will emerge on its own.
Conclusion
Event-driven architecture has proven valuable in transformation programs not because it provides a universal target state, but because it offers a practical way to evolve complex estates without forcing uniform modernization. Its real contribution is architectural optionality: the ability to introduce new capabilities, reshape business processes, and improve operational responsiveness while preserving manageable boundaries between teams and platforms.
As the earlier sections showed, that value depends on disciplined choices. Architects need to select the right event pattern for the business need, define contracts that are stable and meaningful, govern schemas and data responsibly, and build coexistence mechanisms for legacy, SaaS, and modern domain services. They also need strong operational foundations in observability, resilience, and security, because event-driven systems succeed or fail in runtime behavior as much as in design.
A useful way to judge maturity is not by the number of events published, but by the quality of decisions and outcomes the event ecosystem enables. Well-designed event landscapes help enterprises detect change sooner, localize impact more effectively, and make cross-domain behavior more visible to delivery teams and business operators. They also create a foundation for future capabilities such as process intelligence, adaptive automation, and policy-aware decisioning.
The most effective enterprise approach is incremental and evidence-based. Start with a small number of important business moments, establish clear ownership and measurable outcomes around them, and use those implementations to refine standards, platform capabilities, and governance. In that model, architecture evolves through delivery experience rather than abstract design alone. A useful companion practice is periodic architecture board review of event domains, IAM dependencies, Kafka platform usage, and technology lifecycle status so that the event estate remains coherent as adoption grows.
EDA is therefore best treated as an enterprise design discipline, not simply an integration technology choice. When combined with strong domain ownership, disciplined contract management, and business-aware operations, it becomes a durable enabler of transformation. Without those foundations, it risks recreating the same complexity modernization programs are trying to remove.
Frequently Asked Questions
What is enterprise architecture?
Enterprise architecture is a discipline that aligns an organisation's strategy, business processes, information systems, and technology. It provides a structured approach to understanding the current state, defining the target state, and managing the transition — using frameworks like TOGAF and modeling languages like ArchiMate.
How does ArchiMate support enterprise transformation?
ArchiMate supports transformation by modeling baseline and target architectures across business, application, and technology layers. The Implementation and Migration layer enables architects to define transition plateaus, work packages, and migration events — creating a traceable roadmap from strategy through to implementation.
What tools are used for enterprise architecture modeling?
The most widely used tools are Sparx Enterprise Architect (ArchiMate, UML, BPMN, SysML), Archi (ArchiMate-only, free), and BiZZdesign Enterprise Studio. Sparx EA is the most feature-rich — supporting concurrent repositories, automated reporting, scripting, and integration with delivery tools like Jira and Azure DevOps.